llama.cpp Lands Three Audio Models in 48 Hours
Three separate PRs merged into llama.cpp between April 11-13 add MERaLiON-2, Gemma 4's Conformer encoder, and Qwen3-Omni/ASR - making local voice AI inference practical on consumer hardware for the first time.

Between April 11 and April 13, three independent contributors each merged months of audio model work into llama.cpp's main branch within the same 48-hour window. Builds b8762, b8766, and b8769 add MERaLiON-2 from Singapore's A*STAR, Gemma 4's USM-style Conformer encoder, and Alibaba's Qwen3-Omni and Qwen3-ASR respectively. A fourth build, b8775, patched a causal attention bug in the Gemma 4 implementation on April 13.
The cumulative effect is a real step-change for local voice AI. Before this week, llama.cpp's audio support was thin and experimental - Ultravox, Qwen2.5-Omni, and a couple of poorly-verified older integrations. Now it has three architecturally distinct, production-quality audio model families running through a shared inference path on consumer hardware.
TL;DR
- b8762 (Apr 11): MERaLiON-2 3B/10B - Whisper large-v2 encoder + Gemma2 decoder, six speech tasks, Singapore-English/Mandarin/Malay/Tamil
- b8766 (Apr 12): Gemma 4 E2B/E4B audio Conformer - 12-layer USM encoder, BF16 mmproj required, 30s chunking for long audio
- b8769 (Apr 12): Qwen3-ASR + Qwen3-Omni - 24-layer Whisper-like encoder, vision+audio multimodal, 119 language text support
- b8775 (Apr 13): causal attention bug fix for Gemma 4 audio - update right away if on b8766
- All three use
llama-mtmd-cli --audio --mmprojvia the sharedlibmtmdabstraction
What Shipped
MERaLiON-2 - build b8762, April 11
PR #21756 adds MERaLiON-2, a multilingual speech-text model from A*STAR's Institute for Infocomm Research in Singapore, developed under the country's S$70M National Multimodal Large Language Model Programme.
The architecture pairs a Whisper large-v2 encoder with a Gemma2 text decoder, connected through a gated MLP adaptor that stacks audio frames 15x, passes them through layer normalization, then a GLU projection block. Two variants are available: MERaLiON-2-3B (Gemma2-3B decoder) and MERaLiON-2-10B (Gemma2-27B decoder). The model accepts mono 16kHz audio up to 300 seconds per clip.
Coverage goes well beyond English-only models that dominate the open-source ASR space (compare to Cohere's Transcribe release earlier this year): primary targets are English including Singapore English, Mandarin, Malay, and Tamil, with Thai, Indonesian, and Vietnamese also supported. Six task types are handled: ASR, spoken question answering, dialogue summarization, audio captioning, audio-scene QA, and paralinguistic QA.
The llama.cpp implementation hit within 0.002 absolute WER of the bf16 HuggingFace baseline in validation. In practice, quantized local inference is as accurate as running the reference implementation on server hardware. Conversion splits the model in two: convert_hf_to_gguf.py --mmproj produces the audio projection GGUF, while the text decoder is converted separately as a standard Gemma2 model after stripping the text_decoder. prefix.
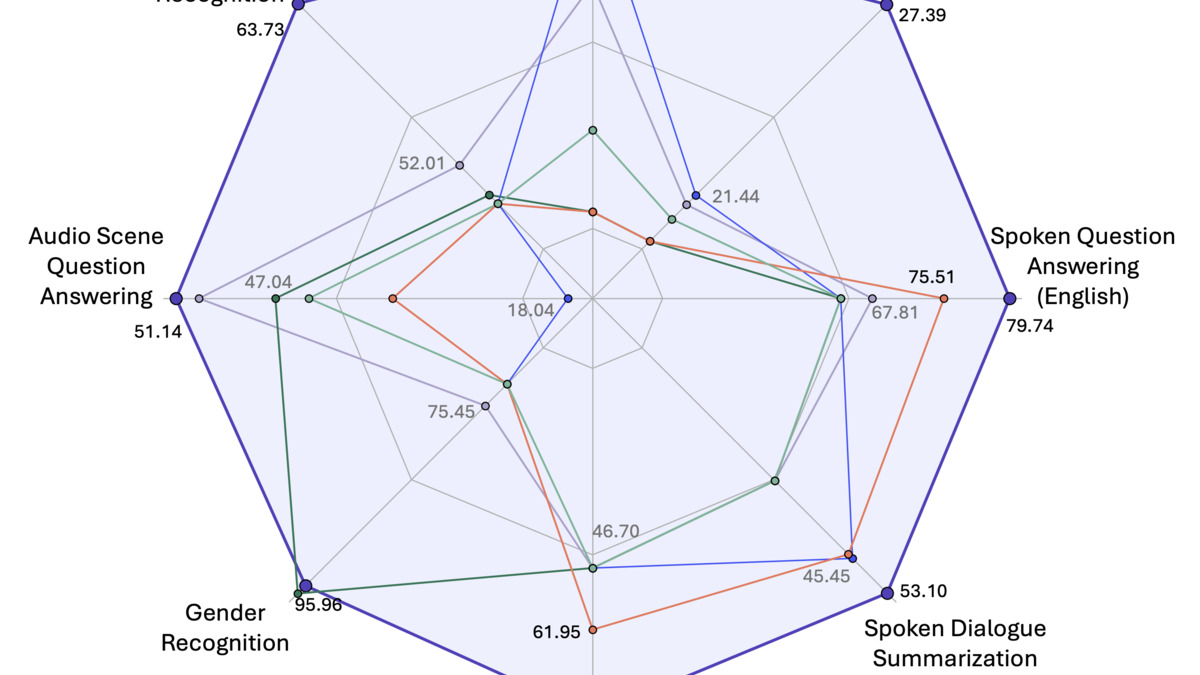 MERaLiON-2-10B performance across six spoken language task types: ASR, spoken QA, dialogue summarization, audio captioning, scene QA, and paralinguistic QA.
Source: huggingface.co
MERaLiON-2-10B performance across six spoken language task types: ASR, spoken QA, dialogue summarization, audio captioning, scene QA, and paralinguistic QA.
Source: huggingface.co
Gemma 4 Audio Conformer - build b8766, April 12
PR #21421 delivers the audio component that the initial Gemma 4 merge explicitly deferred. When PR #21309 landed on April 2 with its title "vision + moe, no audio," a user comment prompted the author to confirm a follow-up was in progress. B8766 is that follow-up.
Only Gemma 4 E2B and E4B include native audio - the larger 26B and 31B variants don't have audio capability in the upstream model weights. The encoder is a 12-layer USM-style Conformer with this per-layer structure: FFN, Self-Attention, Causal Conv1D, FFN, Norm. A two-stage Conv2D subsampler provides 4x total temporal reduction before the Conformer stack. Attention uses chunked local with sinusoidal relative position encoding (chunk_size=12, context_size=24). Output projection uses ClippableLinear with per-tensor clamping and logit softcapping at 50.0, followed by RMSNorm.
The hard constraint: the mmproj GGUF must stay in BF16. F16 and Q8_0 cause measurable quality degradation because ClippableLinear is numerically sensitive. The text decoder itself is quantizable as normal. For long audio, the implementation chunks at 30-second intervals. The quantization compatibility matrix from the PR shows E2B passing 14/14 combinations on short audio and 8/14 on long audio; E4B passes 19/21 and 20/21. Only the lowest 2-bit quantizations fail.
Build b8775, released April 13, patches a causal attention bug. Anyone on b8766 should update before using this.
Qwen3-Omni and Qwen3-ASR - build b8769, April 12
PR #19441 - note the much lower PR number, meaning this was opened and in review for weeks before landing the same day as the Gemma 4 audio work. The PR adds two related models: Qwen3-ASR (speech recognition only) and Qwen3-Omni (vision plus audio simultaneously).
The audio encoder for the ASR path: three Conv2D layers with stride=2 each (8x total time downsampling) feed into a 24-layer Whisper-like transformer, then a MLP projector (Linear(1024,1024), GELU, Linear(1024,2048)). For Qwen3-Omni, audio and vision configurations are extracted from thinker_config in the model parameters. Audio input uses <|audio_start|> and <|audio_end|> tokens; 30-second chunks are used for long audio.
Alibaba's Qwen3 family has been a consistent presence on open-source leaderboards. The underlying Qwen3-Omni model supports 119 text languages and 19 for speech recognition. In the llama.cpp implementation, only audio input is supported - the Talker module for real-time speech synthesis isn't yet implemented.
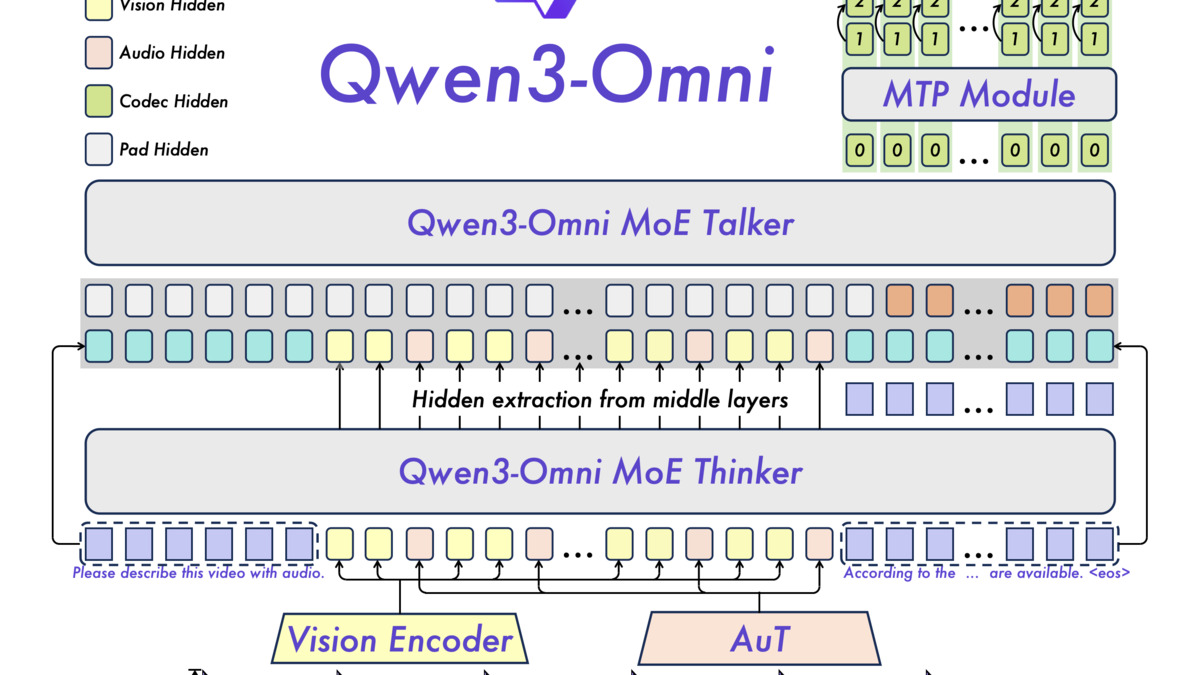 Qwen3-Omni's Thinker-Talker architecture: a MoE text model handles reasoning while a Talker module generates streaming speech output. Only the audio-input (Thinker) side is implemented in the current llama.cpp build.
Source: github.com/QwenLM
Qwen3-Omni's Thinker-Talker architecture: a MoE text model handles reasoning while a Talker module generates streaming speech output. Only the audio-input (Thinker) side is implemented in the current llama.cpp build.
Source: github.com/QwenLM
How to Run It
All three model families use the same interface. Convert a model from HuggingFace format, then pass the decoder GGUF and the mmproj GGUF to llama-mtmd-cli:
# Convert (MERaLiON-2 example)
python3 convert_hf_to_gguf.py --mmproj /path/to/MERaLiON-2-3B/ --outfile mmproj.gguf
python3 convert_hf_to_gguf.py /path/to/MERaLiON-2-3B/ --outfile decoder.gguf
# Transcribe / query with audio
llama-mtmd-cli -m decoder.gguf --mmproj mmproj.gguf --audio input.wav \
-p "Transcribe this audio"
# For Gemma 4 E2B - BF16 mmproj is mandatory
llama-mtmd-cli -m gemma-4-e2b-q4.gguf --mmproj gemma4-mmproj-bf16.gguf \
--audio recording.wav -p "What is being said?"
# For Qwen3-Omni with both vision and audio
llama-mtmd-cli -m qwen3-omni-thinker.gguf --mmproj qwen3-omni-mmproj.gguf \
--audio clip.wav --image photo.jpg -p "Describe what you hear and see"
If VRAM is tight, --no-mmproj-offload keeps the projection model on CPU while the text decoder runs on GPU.
Hardware requirements
| Model | VRAM at Q4 | Apple Silicon | CPU inference |
|---|---|---|---|
| MERaLiON-2-3B | 6-8 GB | M2 16GB | Yes |
| Gemma 4 E2B | 4-6 GB | M2 16GB | Yes |
| Gemma 4 E4B | 6-8 GB | M2 16GB | Yes |
| MERaLiON-2-10B | 12-16 GB | M2 Pro 32GB | Yes |
| Qwen3-ASR | 8-12 GB (model size varies) | M2 Pro 32GB | Yes |
All figures are estimates from reported architecture sizes and standard llama.cpp Q4 memory usage. CPU inference is supported across via llama.cpp's existing backend.
Why Three in Two Days
The timing isn't coincidence, but it isn't coordination either. The Gemma 4 Conformer PR had been in review since late March - the initial Gemma 4 vision+MoE merge on April 2 established the model's GGUF format and unblocked the audio follow-up. MERaLiON-2 appears to have been developed independently and landed when it was ready. Qwen3-Omni's low PR number (19441 vs. Gemma 4 audio's 21421) shows it was submitted weeks earlier and went through a long review cycle before the merge window opened.
Since Georgi Gerganov and the ggml.ai team joined Hugging Face, llama.cpp's review pipeline has had more maintainer bandwidth. That likely contributed to three complex audio PRs clearing in the same window.
The libmtmd abstraction layer, introduced in April 2025, is also part of this story. Before libmtmd, each new modality required deep changes in the core inference path. Now adding a new audio encoder is closer to implementing a plugin against a defined interface. Three independent contributors working on three different architectures all converging on the same binary (llama-mtmd-cli) without conflict is a sign the abstraction is working.
Where It Falls Short
The Qwen3-Omni Talker module - the real-time streaming speech synthesis side - isn't implemented. What shipped is audio understanding only: you feed audio in, get text out. Full voice conversation (audio in, speech out, no round-trip to a TTS API) remains unavailable for this model in llama.cpp.
MERaLiON-2 doesn't yet appear in the multimodal.md pre-quantized model table. Users need to run conversion themselves, which adds friction compared to just pulling a pre-built GGUF from Hugging Face.
Gemma 4's larger variants (26B, 31B) still don't have audio support. GitHub issue #21325 is tracking this, but the 26B and 31B models use a different architecture that wasn't covered in PR #21421. For users who want Gemma 4's reasoning capability with audio input, they're waiting.
And the b8775 patch for Gemma 4 audio causal attention is a reminder that audio support in llama.cpp, despite this week's gains, is still getting sharp edges filed off. The vLLM team went through a similar optimization cycle last year before audio landed cleanly in production inference servers. llama.cpp is a few months behind that curve for audio, but the pace of merges this week suggests the gap is closing fast.
Sources:

