Leanstral Outperforms Claude Sonnet at Formal Code Proofs
Mistral's new open-source Lean 4 agent scores higher than Claude Sonnet on formal proofs at one-fifteenth the cost, raising the bar for trustworthy AI code generation.

Mistral released Leanstral on March 16, a sparse mixture-of-experts model built specifically to write and check formal mathematical proofs in Lean 4. On their own FLTEval benchmark, it beats Claude Sonnet 4.6 by 2.6 points while costing roughly one-fifteenth as much per run.
Key Specs
| Spec | Value |
|---|---|
| Total parameters | 120B |
| Active per token | 6B (sparse MoE) |
| License | Apache 2.0 |
| Target language | Lean 4 (also Rocq/Coq) |
| API endpoint | labs-leanstral-2603 |
| pass@2 FLTEval score | 26.3 (vs. Claude Sonnet: 23.7) |
| pass@2 cost | $36 (vs. Claude Sonnet: $549) |
The context for this release matters. Vibe coding's security record is not great - one study found 69 vulnerabilities in a sample of AI-produced codebases. Mistral is pitching Leanstral as a way to formally verify that AI-written code actually meets its specification before it ships, which is a different problem than unit testing or static analysis.
What Leanstral Does
Formal verification isn't the same as code review. When a human reviews code, they're applying judgment. When a formal prover checks code, it constructs a mathematical proof that the code satisfies a given specification - if the proof fails, the code is wrong, not probably wrong. Lean 4 is one of the main tools researchers and mathematicians use to do this at scale.
Why Lean 4 Specifically
Lean 4 sits at an interesting intersection: it's a full-featured functional programming language and a proof assistant at the same time. You can write real software in it, and the compiler can verify your proofs. It's been gaining traction in mathematics research, most notably through the Fermat's Last Theorem formalization project at Imperial College London.
That FLT project is exactly where Mistral sourced Leanstral's training data. Rather than training on isolated math competition problems - the standard approach for prior models in this space - they used pull requests from a realistic collaborative repository. The difference matters. Proofs in a working codebase involve dependencies, imported definitions, and project structure. Isolated competition problems don't.
Model Architecture
The 120B/6B MoE split is worth unpacking. At each token, only 6 billion parameters activate - drawn from 128 expert modules. This is the same routing approach Mistral has used in their Mixtral family, and it means inference is much cheaper than a dense 120B model despite the headline parameter count. The Labs API endpoint (labs-leanstral-2603) is currently free or near-free during the feedback period.
Leanstral also ships with Model Context Protocol support via lean-lsp-mcp. If you're running the Lean 4 language server locally, Leanstral can interact with it directly, which lets it get real-time proof state feedback rather than guessing blindly. That's not a marketing feature - it directly affects whether the model converges on valid proofs or spins in circles.
 The Lean 4 infoview panel in VS Code shows live proof goals and errors as you write. Leanstral can interact with this state via the lean-lsp-mcp server.
Source: github.com/leanprover/vscode-lean4
The Lean 4 infoview panel in VS Code shows live proof goals and errors as you write. Leanstral can interact with this state via the lean-lsp-mcp server.
Source: github.com/leanprover/vscode-lean4
Benchmark Numbers
Mistral introduced FLTEval with the model. It tests performance on formal proof tasks drawn from the FLT project repository, scoring how often a model generates a correct proof in N attempts (pass@N), normalized against the cost of N calls.
| Model | FLTEval Score | Cost per eval run |
|---|---|---|
| Claude Opus | 39.6 | $1,650 |
| Leanstral pass@16 | 31.9 | $290 |
| Leanstral pass@4 | 29.3 | $72 |
| Leanstral pass@2 | 26.3 | $36 |
| Qwen3.5-397B-A17B pass@4 | 25.4 | - |
| Claude Sonnet | 23.7 | $549 |
| Claude Haiku | 23.0 | $184 |
| Leanstral pass@1 | 21.9 | $18 |
| Kimi-K2.5-1T-32B | 20.1 | - |
| GLM5-744B-A40B | 16.6 | - |
Two things stand out. First, Leanstral pass@2 beats Claude Sonnet outright despite activating only 6B parameters per token while Sonnet is a much larger dense model. Second, Claude Opus remains the best model for this task by a meaningful margin - Leanstral at pass@16 ($290) doesn't reach Opus territory ($1,650 for 39.6). For teams that need the highest possible proof success rate, Opus is still the answer; for teams that need good-enough verification at volume, Leanstral changes the math entirely.
The benchmark is also Mistral's own creation, which limits external validation. FLTEval has been open-sourced, so independent researchers can run it - but the results above are from Mistral's paper.
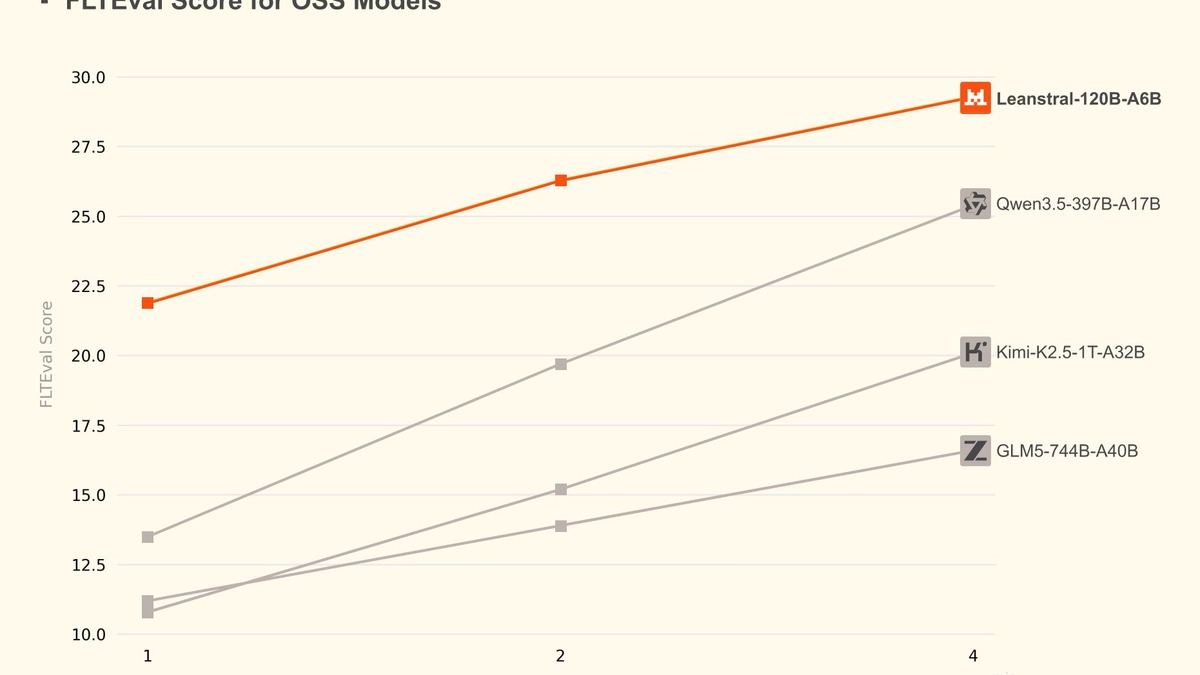 Mistral's cost-vs-score chart for FLTEval. Leanstral pass@2 sits well above the price-to-performance line drawn by Claude Sonnet and Haiku.
Source: mistral.ai
Mistral's cost-vs-score chart for FLTEval. Leanstral pass@2 sits well above the price-to-performance line drawn by Claude Sonnet and Haiku.
Source: mistral.ai
How to Access It
Three paths, depending on your use case:
Mistral Vibe
The easiest entry point. Run /leanstral in the Vibe interface, or use vibe --agent lean from the CLI. This is the zero-setup option - no API key wrangling, no weights to download.
Labs API
The labs-leanstral-2603 endpoint is live and currently free. It's explicitly described as a feedback-period endpoint, so pricing will change after the beta. If you're evaluating whether Leanstral fits your workflow, now is the time.
Self-hosted Weights
Apache 2.0, no strings attached. If you're running on-premise infrastructure or need full control over the model's behavior, the weights are available for download. A 6B-active MoE at 120B total isn't a laptop model - you'll need serious GPU memory - but it's within reach for most teams that already run inference locally. Mistral published this with Mistral Small 4, their new general-purpose model released the same week.
 Arthur Mensch, Mistral AI's CEO. The company has focused heavily on open-source releases and enterprise tooling this quarter, including the Mistral Forge platform.
Source: wikimedia.org
Arthur Mensch, Mistral AI's CEO. The company has focused heavily on open-source releases and enterprise tooling this quarter, including the Mistral Forge platform.
Source: wikimedia.org
What To Watch
The core claim - that Leanstral beats Claude Sonnet at one-fifteenth the cost - is verifiable because FLTEval is open-source. Anyone can run the benchmark independently. That's a stronger foundation than most model comparisons, which rely completely on vendor-reported numbers.
That said, FLTEval covers one specific domain: formal proofs in the style of the FLT project at Imperial College. If your use case is formal verification for software systems rather than pure mathematics, the numbers might look different. Lean 4 is used in both contexts, but training heavily on a mathematics repository doesn't guarantee the same performance on software verification tasks.
The MCP integration is the detail worth watching most closely. A model that can query a live Lean 4 language server gets real feedback on whether its proofs compile - it doesn't have to hallucinate proof state. That feedback loop is what separates a truly useful proof agent from a model that writes plausible-looking Lean syntax. How well that works in practice, across different project structures and dependency graphs, will determine whether this lands as a real tool for AI code review workflows or stays a research curiosity.
The Rocq (formerly Coq) translation capability is a smaller but useful addition. Rocq is the older, more established formal verification system; Lean 4 has better tooling but a younger ecosystem. A model that can translate between them lowers the migration cost for teams sitting on Rocq proofbases who want to move to Lean 4.
Leanstral isn't the first model to attempt formal verification, but it's the first open-source one purpose-built for a realistic repository setting rather than isolated problems. The cost curve is compelling enough that teams using Claude Sonnet for any Lean 4 work should run the numbers before their next billing cycle.
Sources: Mistral AI - Leanstral announcement · The Register - Mistral's new agent proofs your code on the cheap · arXiv - FLTEval benchmark · Top AI Product - Leanstral technical breakdown

