IBM Granite 4.0 1B Speech Tops OpenASR Leaderboard
IBM's new 1B-parameter speech model claims the top spot on the Open ASR Leaderboard while running on consumer hardware, beating Whisper Large V3 by 25% on word error rate.

IBM Research published the Granite 4.0 1B Speech model on March 9, and the numbers are hard to ignore. A 1-billion-parameter open-weight model is sitting at the top of the Open ASR Leaderboard with a 5.52% average word error rate - better than Whisper Large V3 (around 7.4%), Microsoft's Phi-4 Multimodal (6.14%), and NVIDIA's Canary 1B Flash (6.35%). It's also beating the previous Granite Speech 3.3 8B, IBM's own prior best, while using one-eighth the parameters.
Key Specs
| Spec | Value |
|---|---|
| Parameters | 1B (dense) |
| Context (LLM) | 128K tokens |
| Avg WER (OpenASR) | 5.52% |
| Languages (ASR) | EN, FR, DE, ES, PT, JA |
| Languages (translation) | 8 language pairs |
| License | Apache 2.0 |
| Inference | HuggingFace Transformers, vLLM |
| VRAM (BF16) | ~2GB (weights only) |
Architecture
Three-Component Stack
Granite 4.0 1B Speech isn't a single monolithic model. IBM built it as three components trained to work together: a speech encoder, a temporal projector, and a language model backbone.
The encoder is 16 Conformer blocks trained with Connectionist Temporal Classification (CTC). It takes 80-dimensional log-mel filterbanks as input and uses block-attention on 4-second audio segments with self-conditioned CTC from the middle layer. The key trick here is the temporal downsampling: the encoder compresses audio by 2x, and the projector adds another 5x, so by the time audio reaches the language model, it's running at 10Hz rather than the full frame rate. That's what keeps inference fast.
The projector is a 2-layer Window Query Transformer (Q-Former). It takes 15 acoustic embeddings per block and outputs 3 query vectors per block per layer, collapsing the sequence length notably before it hits the LLM.
The language model is Granite 4.0 1B Base with a 128K context window, fine-tuned on the full training corpus with LoRA adapters. The audio path and text instruction path stay separate, which IBM notes also helps with prompt injection resistance - you can't manipulate the encoder with text embedded in audio.
Training Data
IBM trained on roughly 100,000 hours of audio across ASR and translation tasks, spanning 11 source datasets. The breakdown includes:
- 48,000 hours of Multilingual LibriSpeech across five languages
- 18,000 hours of CommonVoice-17 for speech translation
- 10,000 hours of YODAS English
- 9,600 hours of synthetic Japanese audio generated via Kokoro-82M TTS from Fineweb-2 text
That last item is how IBM added Japanese support cleanly. Creating synthetic training data from high-quality TTS and a large text corpus sidestepped the usual problem of Japanese ASR data scarcity. Real recordings would have taken considerably longer to gather at that scale. IBM trained on 8 NVIDIA H100 GPUs over 30 days: 26 days for the encoder, 4 days for the projector and LLM fine-tuning.
 IBM's Granite model family has expanded to include a compact speech model built for enterprise edge deployment.
Source: research.ibm.com
IBM's Granite model family has expanded to include a compact speech model built for enterprise edge deployment.
Source: research.ibm.com
Benchmark Results
The model's 5.52% average WER across eight standard benchmarks puts it ahead of the full field on the Open ASR Leaderboard. Direct competitors:
| Model | Avg WER | RTFx | Params |
|---|---|---|---|
| Granite 4.0 1B Speech | 5.52 | 280 | 1B |
| Canary Qwen 2.5B | 5.63 | 418 | 2.5B |
| Granite Speech 3.3 8B | 5.85 | 31 | 8B |
| NVIDIA Parakeet TDT 0.6B v2 | 6.05 | 3,386 | 0.6B |
| Microsoft Phi-4 Multimodal | 6.14 | 62 | - |
| NVIDIA Canary 1B Flash | 6.35 | 1,046 | 1B |
| Whisper Large V3 | ~7.40 | varies | 1.55B |
RTFx = real-time factor; higher means faster than real-time. WER = word error rate; lower is better.
A few things stand out. NVIDIA's Parakeet TDT 0.6B v2 posts an RTFx of 3,386 - it's very fast. But Granite 4.0 1B beats it on accuracy by a meaningful margin. Granite's 280 RTFx is roughly 9x faster than its 8B predecessor, which only managed 31, and the 1B model does this while reaching better accuracy. The accuracy-efficiency tradeoff moved in the right direction.
The individual benchmark scores show particular strength in multilingual and video contexts: 81.2% on MMMLU multilingual eval and 84.5% on Video-MME with subtitles. The LibriSpeech clean benchmark sits at 1.42% WER, which is competitive with the best specialized models.
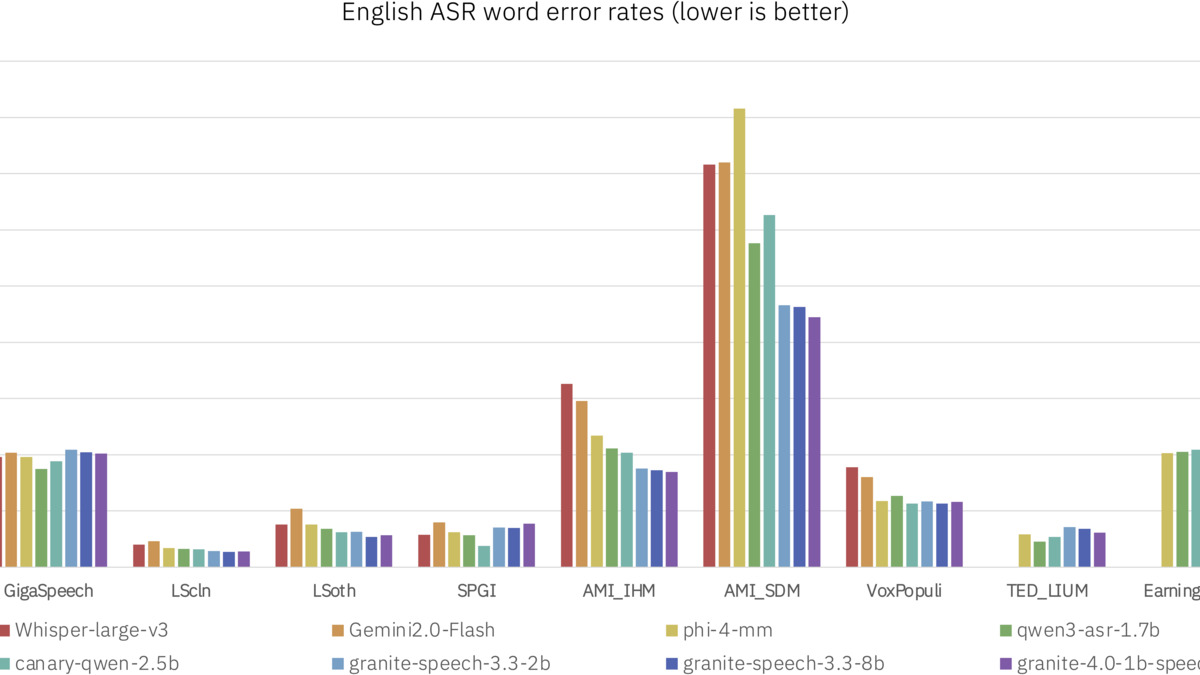 Word error rate comparison across English ASR benchmarks. Lower is better. Granite 4.0 1B Speech leads the Open ASR Leaderboard at time of publication.
Source: huggingface.co
Word error rate comparison across English ASR benchmarks. Lower is better. Granite 4.0 1B Speech leads the Open ASR Leaderboard at time of publication.
Source: huggingface.co
What Runs It
Inference Framework Support
Native vLLM support is the production angle here. You can stand up an OpenAI-compatible speech transcription server with a single command:
vllm serve ibm-granite/granite-4.0-1b-speech --max-model-len 2048
That means any pipeline already using the OpenAI audio API can swap in Granite 4.0 1B Speech with a base URL change. For teams running vLLM 0.17 or later, this drops in directly.
HuggingFace Transformers (>= 4.52.1) also work for batch processing or custom pipelines:
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor
import torch
model = AutoModelForSpeechSeq2Seq.from_pretrained(
"ibm-granite/granite-4.0-1b-speech",
torch_dtype=torch.bfloat16
)
processor = AutoProcessor.from_pretrained("ibm-granite/granite-4.0-1b-speech")
The model weights in BF16 come to roughly 2GB. A RTX 3060 or anything with 6GB+ of VRAM runs it comfortably. CPU inference is possible through Transformers for lower-throughput workloads. IBM explicitly designed this for enterprise deployment on resource-constrained devices - phones, laptops, workstations without a server-grade GPU.
Speculative Decoding
The underlying Granite 4.0 1B Base LLM supports speculative decoding in vLLM. Because the model is small, it can also serve as a draft model for larger Granite LLMs - you get lower per-request latency in exchange for a small overhead on batch processing. IBM has seen 2x speedups on language models and up to 3x on Granite 20B code models with speculative decoding enabled; speech transcription latency should drop proportionally.
Keyword Biasing
IBM added keyword list biasing based on community feedback. You pass a list of domain terms - proper names, product acronyms, medical vocabulary, whatever the model consistently mis-transcribes - as part of the chat prompt alongside the audio. The model learned to weight recognition toward those terms via training on synthetic keyword-biased datasets.
This addresses the most common enterprise complaint about ASR: the model transcribes "Anthropic" as something phonetically similar but wrong. With keyword biasing, you inject the correct forms and the model uses them.
 Granite 4.0 1B Speech's 2GB weight footprint in BF16 puts it within reach of edge deployment on consumer devices.
Source: pexels.com
Granite 4.0 1B Speech's 2GB weight footprint in BF16 puts it within reach of edge deployment on consumer devices.
Source: pexels.com
What To Watch
The Apache 2.0 Angle
IBM released the weights, code, and model card under Apache 2.0 with no usage restrictions. That's the license you need for commercial products - no royalty, no attribution requirement, no restrictions on embedding in enterprise software. It contrasts with other high-performing ASR options that ship under more restrictive terms.
The open-source vs proprietary gap has been closing across text models for over a year. Speech is following the same pattern. Granite 4.0 1B Speech represents the clearest case yet for replacing a proprietary ASR API with a self-hosted model that matches or exceeds it on accuracy.
The Hallucination Caveat
Speech models have their own hallucination failure mode - creating plausible-sounding text when audio is ambiguous, low-quality, or silent. IBM's release notes don't include a systematic hallucination evaluation for Granite 4.0 1B Speech specifically. IBM recommends pairing the model with Granite Guardian 3.3-8b for risk detection in production deployments.
Multilingual Gap
The model handles English, French, German, Spanish, Portuguese, and Japanese for transcription, and adds English-Italian and English-Mandarin for translation. Notably absent: Arabic, Hindi, Korean, and the broader language set you'd expect from a model competing globally. Whisper Large V3 supports 97 languages. Granite 4.0 1B Speech is a stronger model on the languages it supports; the coverage story is less competitive.
The model is on HuggingFace as ibm-granite/granite-4.0-1b-speech with Ollama support at ollama pull granite-speech:1b. The technical report is at arXiv 2505.08699.
Sources:

