GPT-5.5 Brings Mythos-Like Hacking to the Masses
XBOW's benchmarks show GPT-5.5 cuts vulnerability miss rate to 10%, matches Anthropic's restricted Mythos - and is available to all ChatGPT subscribers.
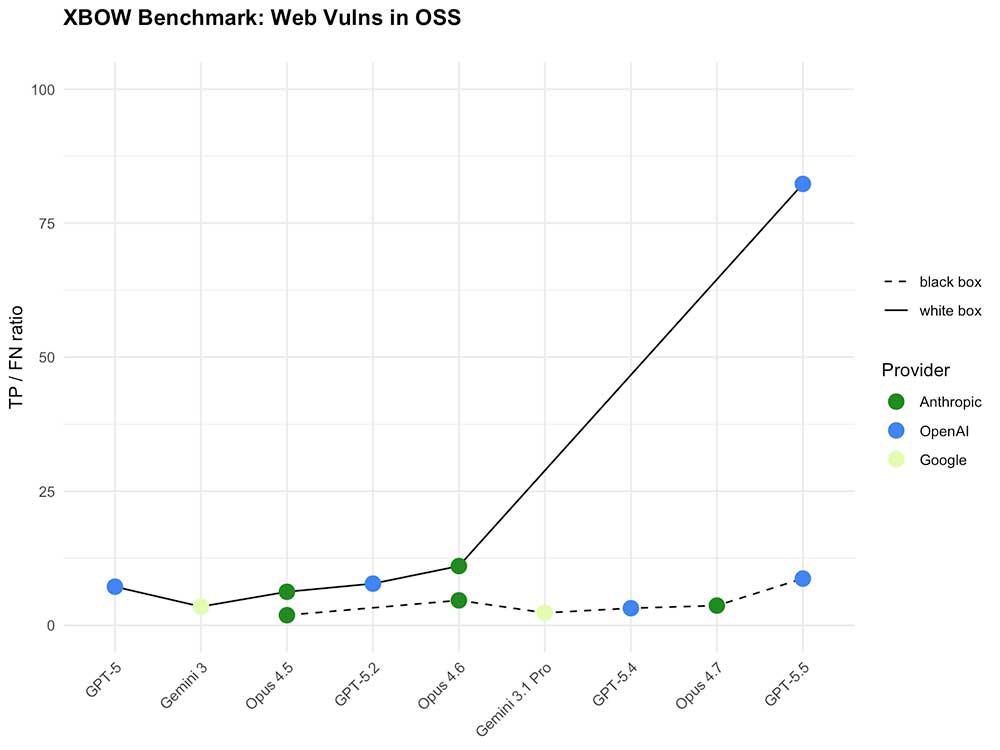
XBOW Benchmark: GPT-5.5 white box performance (solid line, far right) dwarfs every prior model on a shared scale. Source: XBOW
Two days after Anthropic restricted its Mythos Preview model from general release because of its offensive security capabilities, OpenAI published a comparable result - available to anyone with a ChatGPT subscription.
XBOW, the automated penetration testing company, had early access to GPT-5.5 before its April 23rd launch. They tested it the way they test every model: not in isolation, but inside real penetration testing workflows against a benchmark of open-source applications frozen at known-vulnerable versions. The headline number is a 10% vulnerability miss rate - down from 40% for GPT-5 and 18% for Claude Opus 4.6.
That progression alone would be notable. The details are more striking.
The black box flip
XBOW tracks two modes for its benchmark: black box testing, where the agent has no access to source code and must work like an external attacker; and white box testing, where source code is provided. White box has always been the easier mode - more information means better coverage.
GPT-5.5 inverts that assumption in black box mode. Without source code, GPT-5.5 already outperforms GPT-5 running with full source code access. The expected hierarchy - where black box means fighting with oven mitts on, as XBOW's researchers put it - no longer applies.
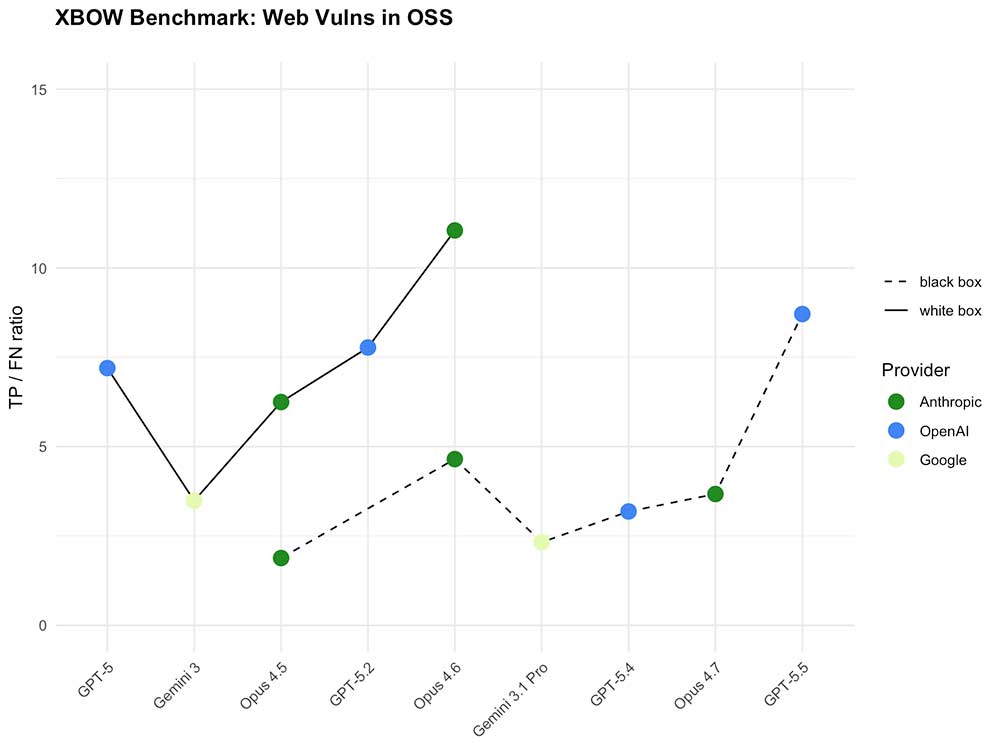
In white box mode, the improvement is so large it broke XBOW's chart scale. Their TP/FN ratio - true positives against false negatives - had previously ranged between roughly 2 and 11 across all models tested, including Gemini 3, the Opus family, and earlier GPT versions. GPT-5.5 with source code access reaches approximately 82 on the same metric. The researchers describe it plainly: "GPT-5.5 effectively killed our benchmark."
Speed and fail-fast behavior
XBOW also measures how efficiently models work through real-world interactions: logging into target systems, navigating interfaces, and handling the friction of production environments.
GPT-5.5 logs in successfully using roughly half the iterations required by the next best model. More practically, it also fails faster. When credentials are wrong or bot detection is active, GPT-5.5 identifies this and moves on in about half the time compared to other models. For automated security testing at scale, that matters - faster failure surfaces configuration problems earlier in an engagement.
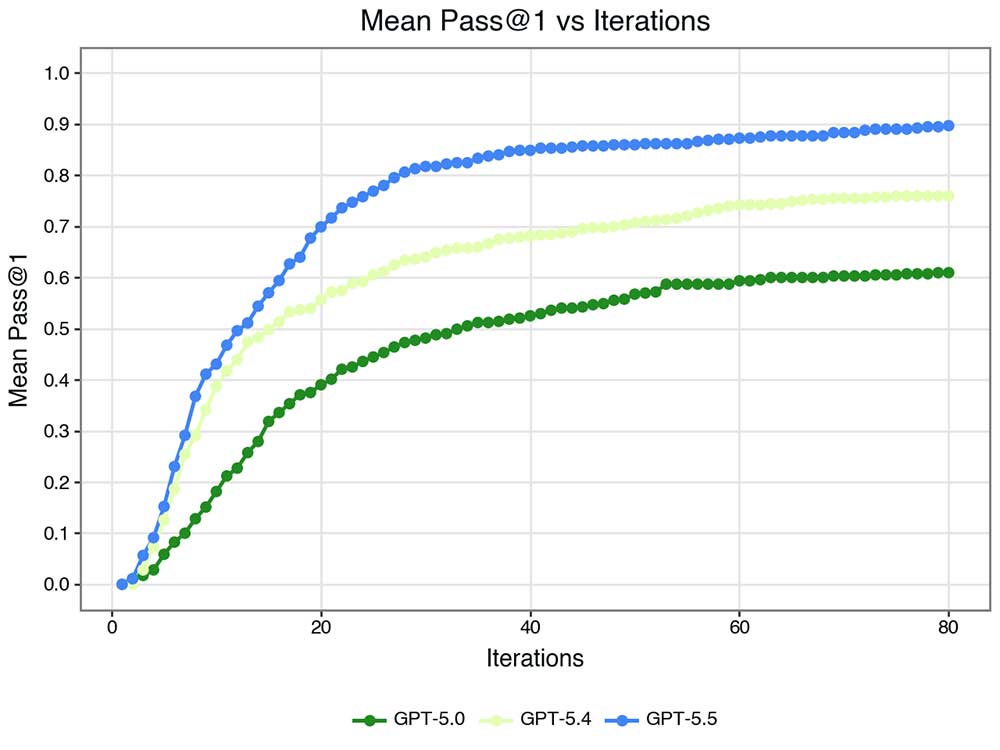
The Mean Pass@1 curves across GPT versions show a clear generational pattern: GPT-5.4 learned to work faster within its iteration budget; GPT-5.5 learned to go further, reaching a Pass@1 around 0.9 at 80 iterations compared to roughly 0.6 for GPT-5.0.
The persist-or-pivot problem
One of the harder things to train for in agentic systems is knowing when to give up. Security agents constantly face the choice between pushing further on a failing path versus cutting losses and redirecting. RLHF-style training tends to discourage giving up, since user satisfaction metrics don't reward it.
GPT-5.5 still sometimes persists longer than ideal, according to XBOW - but only half as often as previous GPT versions or Claude Opus in similar conditions. As AI agents take on longer, more autonomous tasks, this kind of judgment improvement compounds significantly.
The Mythos comparison
The context for all of this is Anthropic's Mythos Preview, released on the same day as GPT-5.5.
Mythos is the first AI model Anthropic has restricted from general users on security grounds. According to Anthropic's published evaluation, Mythos can identify and exploit zero-day vulnerabilities across every major operating system and web browser - capabilities that emerged as downstream consequences of general improvements in code reasoning, not from explicit offensive training. Anthropic released it through Project Glasswing to a curated set of organizations including Amazon, Cisco, CrowdStrike, Microsoft, and Nvidia, with the stated goal of giving defenders time to build countermeasures before such capabilities proliferate.
XBOW's position is that GPT-5.5 delivers comparable offensive capability. OpenAI classifies GPT-5.5's cybersecurity risk as "High" in its Preparedness Framework - serious enough to warrant additional safeguards around agentic vulnerability research and exploit chaining, but below the "Critical" threshold that would trigger access restrictions. The model launched to all ChatGPT Plus, Pro, Business, and Enterprise users.
The gap between Anthropic's restricted approach and OpenAI's broad release is not primarily a safety debate - it is a product strategy difference that happens to have security implications. Whether OpenAI's in-model safeguards are sufficient substitutes for access restrictions is now an open empirical question, not a theoretical one.
XBOW, for their part, says GPT-5.5 will become a key part of their penetration testing stack. Their multi-model system will continue using different models for different tasks, but for core vulnerability detection workflows, the new benchmark is set.
Source: XBOW blog - GPT-5.5: Mythos-Like Hacking, Open To All | OpenAI GPT-5.5 launch coverage | Anthropic Mythos Preview evaluation
