Google Virgo Network Ends the Datacenter Scaling Tax
Google's Virgo Network connects 134K TPU chips at 47 petabits per second using a flat two-layer topology that removes the bandwidth degradation cluster operators have engineered around for years.

If you've ever profiled a large distributed training job, you know the experience: GPUs at partial use while the profiler shows most of the wall time on collective operations. Compute isn't the constraint. The network is.
Google's answer is Virgo Network, unveiled at Cloud Next 2026 on April 22. The premise is straightforward: hierarchical network designs built for general-purpose cloud workloads can't keep up with what modern AI training demands. Virgo replaces the traditional spine-and-leaf topology with a flat, two-layer architecture that Google says removes the bandwidth degradation that cluster operators have been working around for years.
Key Specs
| Metric | Value |
|---|---|
| Bisectional bandwidth | 47 Pb/s non-blocking |
| TPU 8t chips per data center | 134,000 |
| TPU clusters across sites | 1M+ chips |
| NVIDIA Vera Rubin NVL72 per data center | 80,000 GPUs |
| NVIDIA GPU clusters across sites | 960,000 |
| Bandwidth per accelerator | 4x vs prior generation |
| Fabric latency (unloaded) | 40% lower vs prior generation |
| Topology | Flat, 2-layer, high-radix switches |
The announcement came from Benny Siman-Tov, Senior Director of Product Management, and Engineering Fellow Arjun Singh, in a post that reads more like an engineering brief than typical conference marketing. It has specific architecture decisions, explicit tradeoffs, and enough depth to reason about independently.
"The AI era requires a fundamental rethink of physical cloud architecture - networking, in particular. With foundational model parameters growing exponentially, traditional general-purpose networks are reaching their breaking points."
Virgo underpins the AI Hypercomputer, Google Cloud's co-designed infrastructure stack that Meta signed onto earlier this year for a multibillion-dollar GPU workload.
Three Layers, Three Problems
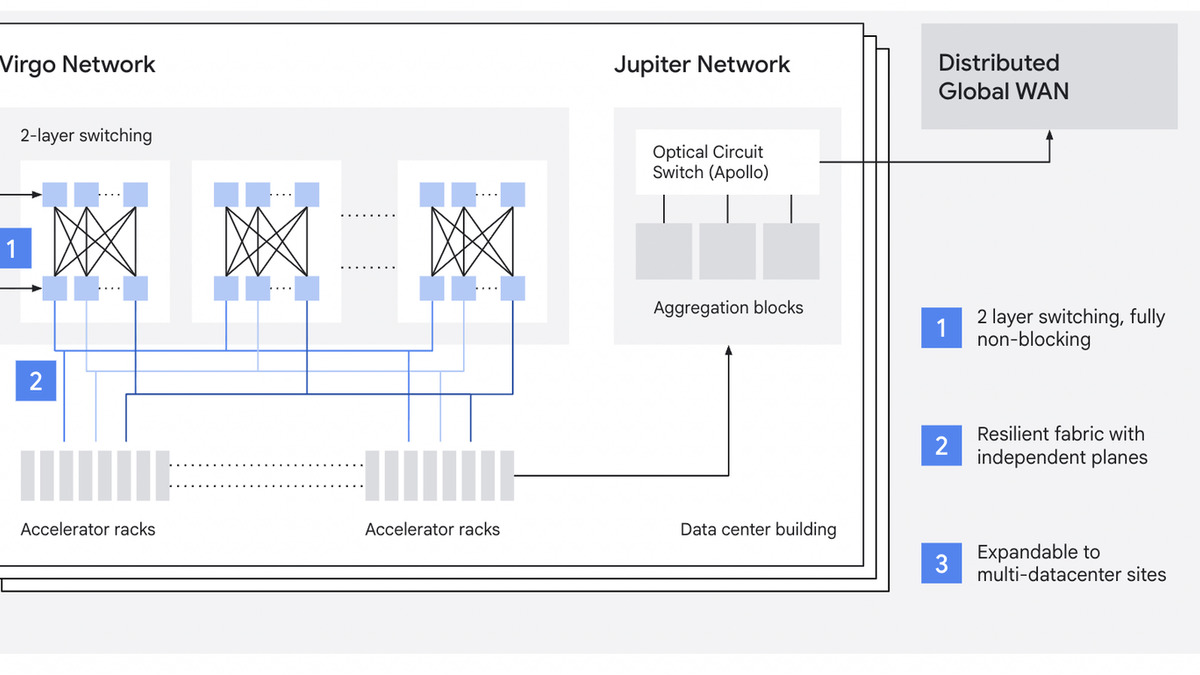
AI workloads impose constraints on network design that general-purpose fabrics weren't built for: massive scale, explosive bandwidth growth, synchronized millisecond-level traffic bursts, and strict inference latency requirements. A single straggler node throttling a 100,000-chip collective operation is a real and common problem at this scale. Virgo addresses this by splitting the data center into three independent network domains, each tuned for a different traffic pattern.
Scale-Up: Inside the Pod
The scale-up domain handles accelerator-to-accelerator communication within a single pod - the high-bandwidth, low-latency fabric where AllReduce and other collective operations actually run. This layer is about tight coupling: all chips in a pod need to operate in near lock-step. It isn't new conceptually, but it's been redesigned to match the doubled interchip bandwidth of the TPU 8t.
Scale-Out: Crossing Pod Boundaries
The scale-out fabric is the new piece. Google describes it as "a dedicated accelerator-to-accelerator RDMA fabric optimized for massive horizontal scale across pods," engineered for deterministic latency and maximum resilience. Instead of routing cross-pod traffic through hierarchical spine switches, the scale-out fabric is flat and non-blocking - every chip can reach every other chip without competing for shared uplinks.
High-radix switches make this possible. More ports per switch means fewer hops in the path, and fewer hops means lower latency and fewer contention points. What used to require three or four network tiers now fits in two. Google calls this a "collapsed fabric," and it's the architectural choice that drives the 40% latency reduction.
Jupiter: Storage and North-South Traffic
Storage access and multi-site traffic still route through Jupiter, Google's existing data center fabric. Virgo handles east-west traffic between accelerators; Jupiter handles north-south flows between accelerators and storage, and between data centers for very large multi-site training runs.
This division is worth noting for anyone doing throughput analysis. The 47 Pb/s figure is accelerator-to-accelerator bandwidth only. Storage I/O runs through a separate fabric with its own limits. The two numbers can't be added.
 Virgo Network's three-layer architecture: scale-up within pod, scale-out RDMA east-west fabric across pods, and Jupiter north-south for storage and multi-site access.
Source: cloud.google.com
Virgo Network's three-layer architecture: scale-up within pod, scale-out RDMA east-west fabric across pods, and Jupiter north-south for storage and multi-site access.
Source: cloud.google.com
What the Scaling Tax Actually Looks Like
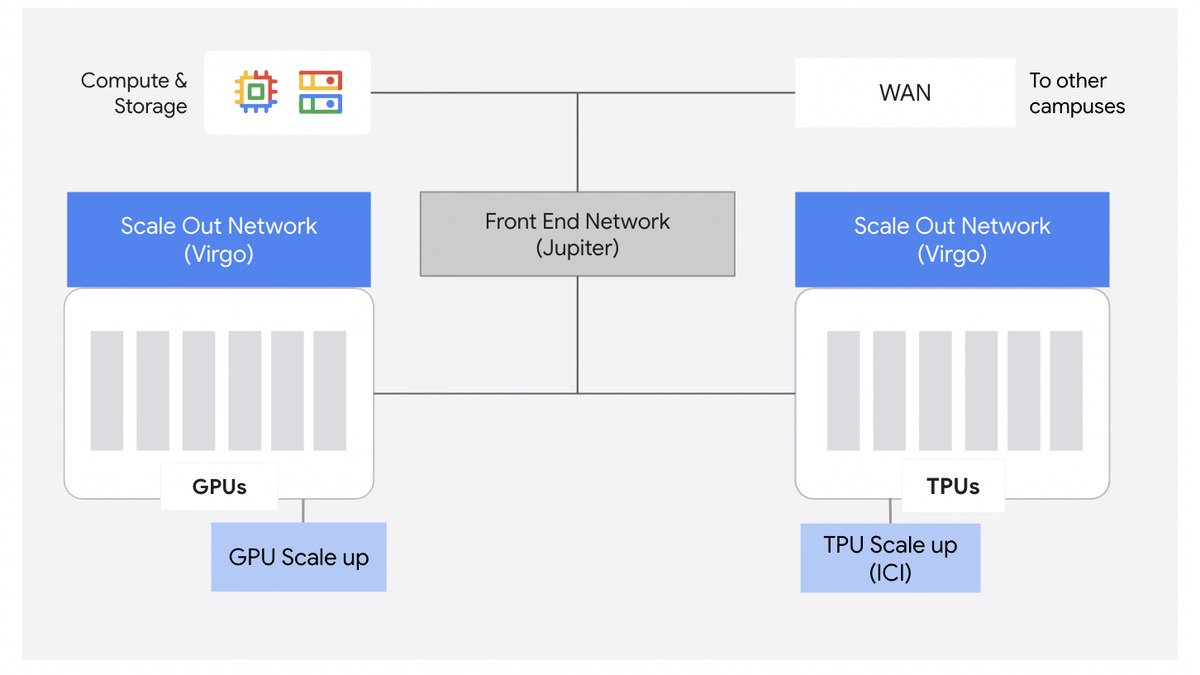
Every distributed training practitioner knows the degradation curve: double your nodes and you don't get double throughput. The gap between theoretical and actual performance grows with cluster size. This is the scaling tax, and it comes from hierarchical network topology.
In a traditional fat-tree network, traffic between nodes in different parts of the cluster traverses shared uplinks at the core. As cluster size grows, those core links become the bottleneck. Aggregate bandwidth grows, but per-node effective bandwidth shrinks. Gradient compression, reduced-precision collectives, and careful batch size tuning exist largely to work around this constraint.
Virgo's non-blocking design removes the shared-uplink bottleneck. Google claims near-linear scaling efficiency across the full 134,000-chip cluster. Those are Google's own measurements, taken against their own prior generation. Independent benchmarks for six-figure chip scaling don't yet exist, and the real-world numbers from external workloads will matter more than internal comparisons.
The fault isolation architecture also deserves attention. Virgo uses independent switching planes so that a localized hardware failure doesn't degrade throughput across the entire cluster. The system also ships with sub-millisecond telemetry and automated straggler and hang detection - both useful for multi-day training jobs where a single stuck node can waste enormous amounts of compute time.
Platform Support
Virgo supports both current Google accelerator families.
| Platform | Per Data Center | Across Multiple Sites |
|---|---|---|
| TPU 8t | 134,000 chips | 1M+ chips |
| NVIDIA Vera Rubin NVL72 (A5X) | 80,000 GPUs | 960,000 GPUs |
The A5X bare metal instances are expected later in 2026. Google and NVIDIA co-designed the Falcon open networking protocol that connects Vera Rubin into the Virgo fabric - a departure from NVIDIA's typical preference for InfiniBand at this scale.
 Traditional hierarchical data center networks (top) vs Virgo's flat two-layer design (bottom), depicting the reduced hop count that drives latency improvements.
Source: cloud.google.com
Traditional hierarchical data center networks (top) vs Virgo's flat two-layer design (bottom), depicting the reduced hop count that drives latency improvements.
Source: cloud.google.com
Where It Falls Short
The 134,000-chip number is Google's infrastructure ceiling, not a customer-facing allocation. Individual Cloud customers won't be reserving anything close to that count. The latency and bandwidth improvements still apply at smaller cluster sizes - fewer hops is fewer hops at 100 chips or 100,000 - but Google hasn't published the per-job allocation limits for Virgo-backed instances. Practitioners can't benchmark against the spec sheet.
No pricing transparency came with the announcement. Google Cloud's TPU and GPU instance pricing doesn't break out networking costs separately. Whether the higher fabric bandwidth changes the price-performance calculation for bandwidth-intensive workloads - large mixture-of-experts models with heavy all-to-all communication, for instance - isn't answerable from public documentation.
A5X and Vera Rubin support is flagged as "later in 2026" with no specific date. Existing A3 Ultra (H200) clusters aren't listed as Virgo-compatible. If your workloads run on Blackwell hardware today, this announcement doesn't affect your current setup.
The storage throughput improvements Google announced at the same event - 10 TB/s Managed Lustre, sub-millisecond Rapid Buckets - also route through Jupiter, not Virgo. An end-to-end training pipeline now spans two distinct network fabrics, each with separate performance characteristics to monitor.
The 4x bandwidth-per-chip increase is the cleanest claim in the announcement. Network-bound training jobs should see that headroom show up in runtimes. What Google still hasn't published is a direct comparison between Virgo-backed TPU 8t and NVIDIA NVL72 pairs running InfiniBand - the benchmark that would actually inform infrastructure decisions. That comparison will come from customers and independent researchers, not from a Cloud Next stage.
Sources:
