Google DiffusionGemma: Parallel LLM Hits 1,100 t/s
Google DeepMind open-sources DiffusionGemma, a 26B MoE model that generates 256 tokens per denoising pass instead of one at a time, reaching 1,100 tokens per second on a single H100.

Google DeepMind published DiffusionGemma on June 10, 2026 - a 26B MoE open-weight model that ditches token-by-token autoregressive generation for block-level discrete diffusion. Instead of one token per forward pass, it produces 256 tokens per denoising pass on a single GPU. Available on HuggingFace today under Apache 2.0.
Key Specs
| Spec | Value |
|---|---|
| Total parameters | 25.2B |
| Active parameters | 3.8B per forward pass |
| Architecture | MoE + block diffusion head |
| Context length | 256K tokens |
| Generation canvas | 256 tokens per denoising pass |
| Speed on H100 (FP8) | 1,008-1,100 tokens/sec |
| Speed on H200 (FP8) | ~1,288 tokens/sec |
| Speed on RTX 5090 | 700+ tokens/sec |
| VRAM quantized | 18-24GB |
| License | Apache 2.0 |
How the Generation Actually Works
Every autoregressive transformer - from GPT-2 to Gemma 4 - creates text one token at a time, left to right. Each step needs a full forward pass through the model, which means loading weights from VRAM repeatedly. That's memory-bandwidth-bound work: the GPU spends most of its time moving data, not computing tensors.
DiffusionGemma flips that. It starts with a 256-token canvas of random placeholder tokens, runs multiple denoising passes over the entire block simultaneously, and commits the result to the KV cache when confident enough. The GPU's tensor cores stay busy doing real matrix multiplications all through, which is why the token throughput numbers are so far ahead of standard autoregressive inference.
Block Autoregressive Diffusion
The model's weights serve dual duty, controlled by a single attention mode flag. In encoder mode, it runs standard causal (left-to-right) attention for prefill and when committing finished blocks. In decoder mode, it switches to fully bidirectional attention over the 256-token canvas - every in-progress position attends to every other simultaneously. That bidirectional view is what makes parallel refinement possible.
This sits on top of the Gemma 4 26B MoE backbone (128 experts, 8 active per token, 1 shared expert), with the diffusion head derived from the Gemini Diffusion research program. The academic foundation is the ICLR 2026 paper "Block Diffusion: Interpolating Between Autoregressive and Diffusion Language Models."
Entropy-Bound Token Locking
Not all positions get denoised at the same speed. The model tracks per-token entropy across denoising iterations. When entropy drops below a threshold of 0.005, that position locks in - it's excluded from further sampling passes. Positions still uncertain resample fresh random tokens and go another round. This gating mechanism is what keeps parallel generation coherent: high-confidence tokens anchor the surrounding context, constraining the remaining uncertain positions.
The recommended sampling config is 48 max denoising steps with linear temperature decay from 0.8 to 0.4, entropy bound 0.1, and mutual information-based token selection.
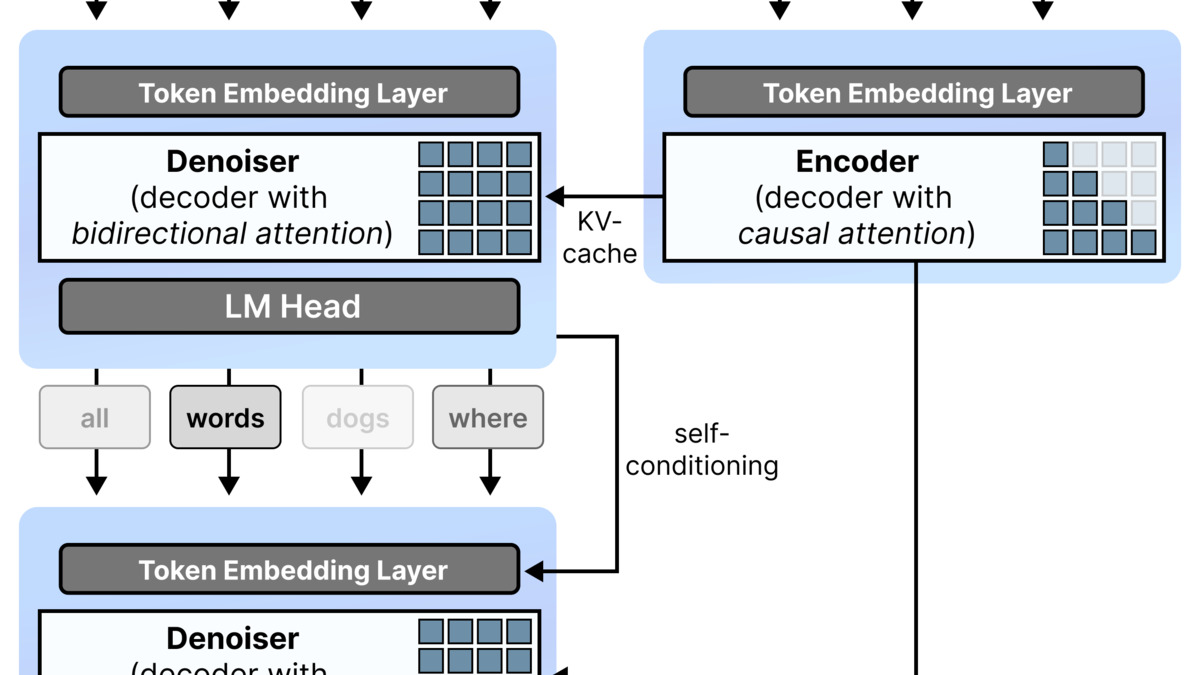 The block autoregressive diffusion architecture - causal attention during prefill and commit, bidirectional attention during denoising passes over the 256-token canvas.
Source: developers.googleblog.com
The block autoregressive diffusion architecture - causal attention during prefill and commit, bidirectional attention during denoising passes over the 256-token canvas.
Source: developers.googleblog.com
Benchmark Numbers
The speed-quality tradeoff is real. Google's own documentation says so directly, which is more transparent than most model launches. The gaps are largest on hard reasoning and vision tasks.
| Benchmark | DiffusionGemma 26B | Gemma 4 26B | Gap |
|---|---|---|---|
| MMLU Pro | 77.6% | 82.6% | -5.0 pts |
| AIME 2026 | 69.1% | 88.3% | -19.2 pts |
| LiveCodeBench v6 | 69.1% | 77.1% | -8.0 pts |
| GPQA Diamond | 73.2% | 82.3% | -9.1 pts |
| MMMU Pro (Vision) | 54.3% | 73.8% | -19.5 pts |
| MATH-Vision | 70.5% | 82.4% | -11.9 pts |
The general-knowledge gap (MMLU Pro: -5 points) is manageable for many use cases. The math and vision losses (-19 points each) are harder to work around if your workload relies on multi-step reasoning.
This isn't the first open-weight diffusion language model to ship. Inception Labs released Mercury 2 earlier this year, which we independently verified at 1,196 tokens per second on Blackwell hardware - faster than DiffusionGemma on comparable GPUs. The distinction is architecture: Mercury 2 was built for diffusion inference from scratch, while DiffusionGemma bolts a diffusion head onto the Gemma 4 MoE backbone, gaining multimodal inputs and a larger overall parameter budget in exchange for a more constrained quality-speed tradeoff.
You can read the full technical breakdown in our DiffusionGemma model card.
Running It Locally
The consumer bar for running DiffusionGemma is achievable but specific.
A RTX 4090 (24GB) or RTX 5090 (24GB) can handle it quantized - six GGUF variants and NVFP4 (Blackwell-optimized 4-bit float) are available on HuggingFace. The NVFP4 format is described as "near-lossless" on Blackwell GPUs. At full FP8 precision on a H100, you get the headline 1,008-1,100 tokens/sec numbers at single-user concurrency.
Apple Silicon is explicitly not a target. The architecture relies on compute-dense operations that don't translate well to unified-memory GPUs, and Google's documentation says so plainly. If your local setup is M3 Max or M4 Pro hardware, the benchmark numbers won't carry over.
Framework support is solid for a day-one release. DiffusionGemma is the first diffusion LLM natively supported in vLLM - serve it with vllm serve "google/diffusiongemma-26B-A4B-it". MLX, SGLang, and HuggingFace Transformers also work. Fine-tuning is available via Unsloth and NVIDIA NeMo.
 DiffusionGemma ships with day-one support for vLLM, MLX, SGLang, and HuggingFace Transformers.
Source: developers.googleblog.com
DiffusionGemma ships with day-one support for vLLM, MLX, SGLang, and HuggingFace Transformers.
Source: developers.googleblog.com
What To Watch
Three things worth tracking before putting this into production.
Hard tasks expose the quality gap most. The -19 point AIME 2026 result isn't just a number - it reflects that multi-step reasoning chains are where parallel generation struggles most. The bidirectional attention over a 256-token canvas has trouble propagating logical dependencies across many intermediate steps. Applications requiring accurate multi-hop reasoning or formal math should test thoroughly before committing.
The speed advantage is local-only. Google's own documentation acknowledges that high-QPS cloud deployments already saturate GPU compute through request batching. The throughput advantage of block diffusion shrinks or disappears in that environment. The case for DiffusionGemma is strongest in low-concurrency local inference, real-time applications where latency matters more than throughput, and on-device scenarios.
Fine-tuning looks promising. One result in the model card stands out: base DiffusionGemma solves 0% of Sudoku puzzles; a SFT-tuned version solves 80% in 12 denoising steps versus 48+ for the base. That's a large jump from targeted fine-tuning, and it suggests the diffusion head responds well to task-specific training. Constrained structured generation may be where this architecture has the clearest edge over autoregressive alternatives - not in matching Gemma 4 26B on general benchmarks, but in specialized tasks where iterative refinement over a fixed canvas is a genuine technical advantage.
Sources:
