GLM-5.1 Tops SWE-Bench Pro With Zero NVIDIA Hardware
Z.ai's GLM-5.1 scores 58.4 on SWE-bench Pro, edging out GPT-5.4 and Claude Opus 4.6, after being trained on 100,000 Huawei Ascend chips with no US silicon.

Z.ai shipped GLM-5.1 on April 7, and the first thing the community noticed wasn't the benchmark score. It was what the model wasn't trained on.
No NVIDIA. No AMD. No CUDA. The entire training run - 100,000 chips across a cluster the size of a city block - ran on Huawei Ascend 910B hardware using Huawei's MindSpore framework. And the model it produced just claimed the top spot on SWE-bench Pro, the toughest software engineering benchmark that exists.
Key Specs
| Spec | Value |
|---|---|
| Total parameters | 744B (MoE) |
| Active per token | ~40B |
| Context window | 200K tokens |
| Max output | 128K tokens |
| Training tokens | 28.5T |
| SWE-bench Pro | 58.4 (#1) |
| License | MIT |
| Training hardware | 100K Huawei Ascend 910B |
| Weights | HuggingFace |
What Changed From GLM-5
GLM-5.1 isn't a new architecture. It's a post-training upgrade to GLM-5, the 744B MoE model Z.ai released in early 2026. The base weights, context window, and active parameter count are unchanged. What's new is how the model was refined after pre-training.
The Agentic Training Loop
Z.ai's post-training pipeline centers on what they call asynchronous reinforcement learning, a setup that decouples the generation step from the learning step so the model can keep working while the training backend catches up. This matters for long-horizon tasks, where a single job can involve hundreds of tool calls spanning hours.
The result is that GLM-5.1 can sustain up to eight hours of continuous autonomous work on a single coding task - a figure verified under METR evaluation standards. The model breaks complex problems into subproblems, runs experiments, reads outputs, identifies blockers, and backtracks when stuck. Z.ai calls this "break-and-repair" optimization.
The company demonstrated it building a Linux desktop environment from scratch and improving a vector database through 600-plus iterations to reach 21,500 queries per second. These aren't cherry-picked demos. The METR evaluation is third-party and methodology-disclosed.
Architecture Refresher
For those who didn't follow the original GLM-5 launch, here's what's underneath:
- 744B total / 40B active: A Mixture of Experts model that routes each token through roughly 40B parameters, keeping inference costs manageable relative to a dense 744B model.
- Dynamic Sparse Attention: Z.ai's variant of sparse attention that cuts memory overhead during long-context inference by skipping attention over less-relevant tokens.
- 28.5T training tokens: Pre-training dataset comparable in scale to Llama 4 and the GPT-5 family.
- GLM_MOE_DSA architecture: The model type string on Hugging Face, which confirms the MoE topology and the sparse attention variant.
Benchmark Numbers
GLM-5.1's headline claim is SWE-bench Pro at 58.4. That's the benchmark that actually tests whether a model can fix real bugs in real codebases, not toy problems. The competitors cluster within two points of each other, which makes the margin meaningful without being decisive.
| Benchmark | GLM-5.1 | GPT-5.4 | Claude Opus 4.6 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-bench Pro | 58.4 | 57.7 | 57.3 | 54.2 |
| Terminal-Bench 2.0 | 63.5-69.0 | - | - | - |
| MCP-Atlas (public) | 71.8 | - | - | - |
| HLE (with tools) | 52.3 | - | 36.7 | - |
| CyberGym | 68.7 | - | - | - |
| GPQA-Diamond | 86.2 | - | - | 94.3 |
| AIME 2026 | 95.3 | 98.7 | - | - |
The pattern is clear from the broader coding leaderboard: GLM-5.1 leads on agentic software engineering tasks and trails on pure math and science reasoning. It isn't the best model at everything. It's specifically the best model at the kind of work software engineers actually do.
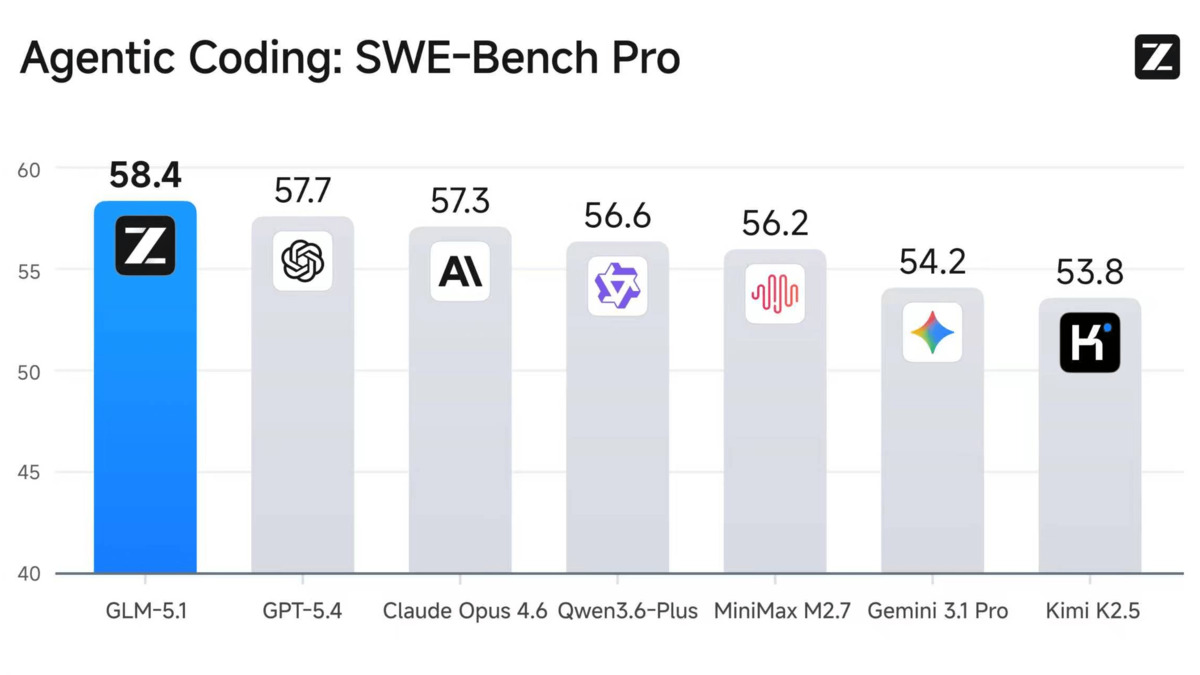 GLM-5.1 leads the SWE-bench Pro ranking, edging GPT-5.4 by 0.7 points and Claude Opus 4.6 by 1.1 points.
Source: officechai.com
GLM-5.1 leads the SWE-bench Pro ranking, edging GPT-5.4 by 0.7 points and Claude Opus 4.6 by 1.1 points.
Source: officechai.com
What the HLE Score Means
Humanity's Last Exam with tools is worth a closer look. GLM-5.1 scores 52.3, while Claude Opus 4.6 scores 36.7 - but the Anthropic number is without tools. Direct comparison is tricky. The more interesting signal is that GLM-5.1 shows consistent gains from tool access, which suggests the agentic post-training is doing real work and not just padding scores.
The Huawei Hardware Story
Zhipu AI landed on the US Entity List in January 2025, cutting off legal access to Nvidia H100, H200, and B200 chips for training. Most analysts expected that to cap the company's frontier ambitions. GLM-5.1 is the clearest evidence yet that those predictions were wrong.
Training Stack
The GLM-5 family (including this 5.1 upgrade) was trained on roughly 100,000 Huawei Ascend 910B chips. The Ascend 910B isn't equivalent to a H100 on raw FP16 throughput, but at scale, with enough chips and good enough systems software, the gap closes. MindSpore, Huawei's AI framework, handles the distributed training plumbing that PyTorch and Megatron-LM handle on Nvidia clusters.
This is the same infrastructure story that's been quietly building across China's AI ecosystem. DeepSeek's upcoming V4 is also targeting Huawei's newer Ascend 950PR chips. The bet is that a CUDA-free training stack is achievable if you're willing to invest years in systems engineering and tolerate slower hardware iteration.
For Z.ai, it wasn't a choice. The Entity List made it a necessity. GLM-5.1 is what that necessity produced.
 Huawei's Ascend 910B chip - the hardware behind GLM-5.1's entire training run. Z.ai used roughly 100,000 of them.
Source: tomshardware.com
Huawei's Ascend 910B chip - the hardware behind GLM-5.1's entire training run. Z.ai used roughly 100,000 of them.
Source: tomshardware.com
Z.ai went public on the Hong Kong Stock Exchange in January 2026, raising approximately $558 million. That capital is what funds the compute scale needed to train and iterate on a 744B model without access to US hardware vendors. The IPO also gave the company's benchmark claims more scrutiny - publicly traded AI labs don't benchmark-stuff the same way a startup with nothing to lose might.
 Z.ai's Hong Kong IPO in January 2026 - the first Chinese AI company to go public. The $558M raised funds the compute infrastructure behind GLM-5.1.
Source: cgtn.com
Z.ai's Hong Kong IPO in January 2026 - the first Chinese AI company to go public. The $558M raised funds the compute infrastructure behind GLM-5.1.
Source: cgtn.com
Running It Yourself
Self-hosting a 744B MoE model is not a weekend project, but the numbers are better than they used to be.
| Resource | Unquantized | GGUF Quantized (via Unsloth) |
|---|---|---|
| Storage | ~1.49 TB | ~500 GB (estimated Q4) |
| Min GPUs | 8x (tensor parallel) | 4-8x depending on quant level |
| Inference speed | ~44.3 tok/s | Lower |
| VRAM required | 8x H200 or equiv. | Varies |
The 44.3 tokens per second figure is the weakest number in the GLM-5.1 spec sheet. It's slower than every comparable frontier model. For interactive use, that's noticeable. For agentic background tasks that run overnight, it's irrelevant.
GGUF quantized versions are being tracked by the Unsloth team. If you want to run GLM-5.1 on consumer hardware at lower precision, that's the path to watch.
The model is compatible with Claude Code and other agentic tool harnesses that accept OpenAI-compatible endpoints.
What To Watch
GLM-5.1's SWE-bench Pro score is self-reported by Z.ai. Independent third-party evaluation hadn't published results as of April 8. Z.ai's prior SWE-bench Verified scores for GLM-5 held up under third-party testing, which is a decent precedent, but verification isn't the same as confirmation.
The inference speed problem is real. 44.3 tokens per second at the frontier is slow. Z.ai's API pricing ($25/$125 per million input/output tokens at post-research public rates) also puts it above cheaper options like Gemini Flash variants for high-volume agentic workloads.
The GPQA-Diamond gap (86.2 vs Gemini 3.1 Pro's 94.3) shows this model was shaped by its post-training priorities. Software engineering benchmarks went up; hard science reasoning didn't get the same treatment. That's a design choice, not a flaw - but it matters if you need a model that's equally strong across domains.
The Huawei hardware story is the long-term thread to follow. GLM-5.1 proves that a frontier-class model can be trained on non-CUDA silicon at scale. Whether that proof generalizes to other Chinese labs - and whether it changes how Western policymakers think about compute restrictions - is a question that GLM-5.1 just made notably harder to dismiss.
Sources: Z.ai GLM-5.1 on Hugging Face · TechBriefly · Dataconomy · Simon Willison · Creati.ai

