Gemini Robotics-ER 1.6 Can Now Read Analog Gauges
Google DeepMind's Gemini Robotics-ER 1.6 hits 93% accuracy reading industrial gauges via agentic vision, a 70-point jump over ER 1.5, and launches inside Boston Dynamics' Spot today.

Reading a pressure gauge sounds trivial. A human glances at a dial, takes a reading, moves on. For a robot, it's a chain of spatial reasoning tasks that most models handle poorly - or didn't handle at all. Gemini Robotics-ER 1.5 succeeded on instrument reading 23% of the time. The new ER 1.6, released Tuesday by Google DeepMind, hits 93% with its agentic vision mode enabled. That's a 70-point swing on something factories need every day.
Google DeepMind published the model to the Gemini API and Google AI Studio on April 14, pairing the announcement with a joint integration from Boston Dynamics that brings ER 1.6 directly into the Spot robot's inspection platform.
What Changed Between 1.5 and 1.6
Instrument reading accuracy by model
| Model | Instrument Reading |
|---|---|
| Gemini Robotics-ER 1.5 | 23% |
| Gemini 3.0 Flash | 67% |
| Gemini Robotics-ER 1.6 | 86% |
| ER 1.6 + Agentic Vision | 93% |
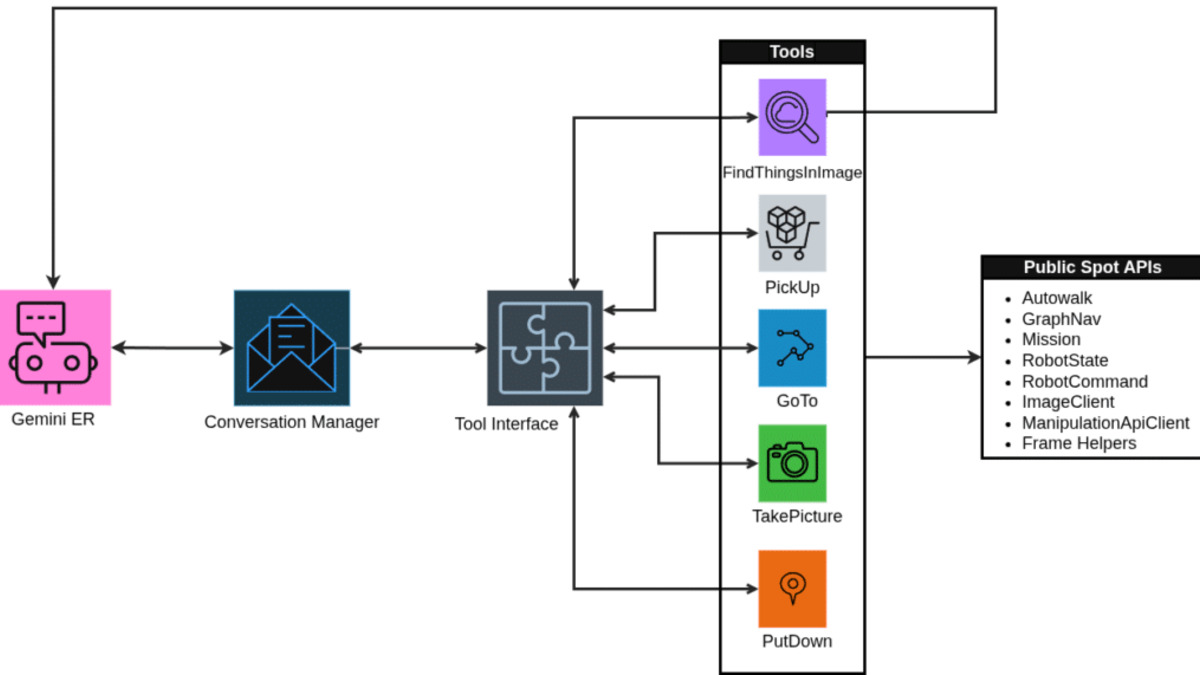
ER 1.6 adds three capabilities that weren't in the previous version.
Instrument Reading
The standout feature. ER 1.6 can now interpret analog pressure gauges, thermometers, and industrial sight glasses using what Google calls "agentic vision" - a combination of visual reasoning and code execution that lets the model zoom, crop, and estimate proportions programmatically rather than relying on a single image pass.
The benchmark comparison is worth sitting with. Gemini 3.0 Flash, a strong general-purpose model, already reached 67%. ER 1.5, a robotics-specific model, managed only 23% - suggesting the previous architecture wasn't built for the close-read, fine-detail work that gauge faces require. ER 1.6 jumps to 86% on its own, then to 93% when the agentic vision pipeline is enabled.
Enhanced Pointing and Spatial Reasoning
ER 1.6 uses coordinate points as intermediate reasoning steps. Instead of directly classifying or grasping an object, the model first identifies spatial anchors, then chains those into grasp points, motion trajectories, or constraint checks. This matters for sorting tasks, counting items in cluttered environments, and identifying which valve in a bank of identical ones meets a specific condition.
Multi-View Success Detection
Robots in industrial facilities rarely have a clean, unobstructed camera angle. ER 1.6 advances what Google calls "success detection" by fusing information from multiple camera streams - overhead and wrist-mounted - to determine whether a task completed, even when the target is partially occluded.
This capability is less visually exciting than gauge-reading but arguably more critical for real deployment. A robot that can't tell whether its own action succeeded must pause for human confirmation or, worse, declare success incorrectly and move on.
 Spot demonstrating the Gemini Robotics integration during a pilot in March 2026.
Source: bostondynamics.com
Spot demonstrating the Gemini Robotics integration during a pilot in March 2026.
Source: bostondynamics.com
How It Works Inside Spot
Boston Dynamics has embedded ER 1.6 into its Orbit software platform, across two systems: AIVI (AI Visual Inspection) and AIVI-Learning.
A Two-Model Architecture
The integration pairs two distinct models. ER 1.6 acts as the strategist - handling high-level planning, spatial reasoning, and task interpretation. Gemini Robotics 1.5, the vision-language-action model, acts as the executor - translating those plans into Spot's motor commands.
"Capabilities like instrument reading and more reliable task reasoning will enable Spot to see, understand, and react to real-world challenges completely autonomously," said Marco da Silva, VP and General Manager of Spot at Boston Dynamics.
The practical use cases are concrete: reading pressure gauges and flow meters, detecting hazards such as spills and debris, conducting 5S safety and compliance audits, tracking materials and inventory, and monitoring conveyor systems. It's unglamorous industrial work, repeated at scale - exactly where robotics needs to be cost-effective.
This kind of architecture is part of a broader shift in physical AI. NVIDIA's Alpamayo reached 100,000 downloads earlier this year as the top robotics model on Hugging Face, using a similar separation between reasoning and action layers. The pattern is becoming standard.
AIVI-Learning and Data Sharing
AIVI-Learning adapts the model to a specific facility's equipment and layout by training on customer-collected image data. Boston Dynamics says that data stays internal, but the requirement itself deserves scrutiny. Buyers in regulated industries - energy, pharmaceuticals, chemicals - may find that sharing operational footage is not a trivial sign-off, particularly where equipment configuration is itself sensitive.
 The dual-model integration architecture: ER 1.6 handles reasoning, Gemini Robotics 1.5 handles motor control.
Source: bostondynamics.com
The dual-model integration architecture: ER 1.6 handles reasoning, Gemini Robotics 1.5 handles motor control.
Source: bostondynamics.com
Safety
ER 1.6 posts +6 to +10 percentage point improvements over ER 1.5 on the ASIMOV benchmark, which tests whether foundation models used as robot controllers comply with safety policies - avoiding actions that could harm people or damage equipment.
Carolina Parada from Google DeepMind described the underlying approach: the model is trained to reason about consequences rather than just immediate actions. A robot placing a cup on a table edge should flag this as risky and reposition, rather than completing the action and moving on.
This connects to broader research on robotic AI safety that DeepMind published earlier this month, mapping adversarial attack vectors against autonomous agents. Physical robots represent the highest-stakes version of that problem - a manipulated agent in a warehouse doesn't just produce bad text, it moves things.
What It Does Not Tell You
The instrument reading benchmark uses controlled conditions: good lighting, clean gauge faces, calibrated camera positions. Industrial gauges in practice are often dirty, partially obscured, worn, or mounted at awkward angles. Google discloses the 93% figure comes from structured evaluation, not field data.
Boston Dynamics has independently acknowledged that 80% represents the threshold for practical commercial viability in real environments. The gap between 93% in the lab and 80% at the viability floor isn't large, but the test conditions matter a great deal.
There's also no pricing disclosed for Gemini API access in robotics applications, and no public timeline for the agentic vision capability outside the Spot integration. Developers building on the Gemini API can access ER 1.6 for generic robotics tasks, but the Boston Dynamics deployment is a closed commercial integration.
It's also worth noting that Gemini 3.1 Pro's benchmark performance has not always translated to reliable API availability. Developers using ER 1.6 at the API level are working with the same infrastructure.
A 70-point improvement on instrument reading is a real technical step, not a press release number. The dual-model architecture - ER 1.6 reasoning, Gemini Robotics 1.5 acting - separates concerns cleanly, which lets each model improve without the other regressing. Spot is already rolled out across 1,500+ facilities globally; the commercial test population exists. Whether the lab numbers hold at scale, in the conditions actual factories produce, is what the next year of deployments will establish.
Sources:
- Google DeepMind: Gemini Robotics-ER 1.6
- Google Blog: Gemini Robotics-ER 1.6
- Boston Dynamics: Spot and Gemini Robotics
- Robotics & Automation News: Boston Dynamics integrates Gemini into Spot
- IEEE Spectrum: Boston Dynamics and Google DeepMind Unveil a Smarter Spot
- MarkTechPost: Google DeepMind Releases Gemini Robotics-ER 1.6
- ASIMOV Benchmark
