Gemini 3.5 Flash: Real Speed, Selective Benchmarks
Google's Gemini 3.5 Flash is genuinely fast at 289 tok/s and competitive on agentic tasks - but the benchmark portfolio has gaps worth knowing before you build on it.

Google put Gemini 3.5 Flash into general availability on May 19, framing it at I/O 2026 not as a smarter chatbot but as infrastructure for agentic workflows. At 289 tokens per second and $1.50 per million input tokens, the raw efficiency numbers are real. The benchmark picture is more selective than the announcement slides suggest.
TL;DR
- Gemini 3.5 Flash hits 289 tok/s output speed - 4x faster than rival frontier models by Google's numbers
- Every benchmark Google published is an agentic or coding benchmark; no MMLU, GPQA, or general reasoning scores
- SWE-Bench Pro ranking: 3rd at 55.1%, behind Claude Opus 4.7 (64.3%) and GPT-5.5 (58.6%)
- Long-context retrieval drops sharply at scale: 77.3% MRCR v2 accuracy at 128K falls to 26.6% at 1M tokens
- Pricing is 3-6x higher than earlier Flash models - HN developers flagged the jump within hours
What Google Announced
Six benchmarks appeared in the official I/O presentation. All six target agentic or coding scenarios.
| Benchmark | Gemini 3.5 Flash | Gemini 3.1 Pro | Change |
|---|---|---|---|
| Terminal-Bench 2.1 | 76.2% | 70.3% | +5.9 pts |
| MCP Atlas | 83.6% | 78.2% | +5.4 pts |
| Finance Agent v2 | 57.9% | 43.0% | +14.9 pts |
| GDPval-AA Elo | 1,656 | 1,314 | +342 pts |
| SWE-Bench Pro | 55.1% | - | - |
| CharXiv Reasoning | 84.2% | not published | - |
All numbers are vendor-reported. No independent third-party evaluation had been published as of May 22.
Terminal-Bench 2.1 measures task completion in terminal environments. MCP Atlas benchmarks Model Context Protocol tool-use, which Google also shipped natively in Chrome at the same I/O. Finance Agent v2 tests multi-step financial reasoning with tool calls. GDPval-AA is Google's own Elo-style agentic leaderboard. Every single benchmark is one Google wants to win.
 At 289 tok/s, Gemini 3.5 Flash is the fastest frontier model available through a public API.
Source: pexels.com
At 289 tok/s, Gemini 3.5 Flash is the fastest frontier model available through a public API.
Source: pexels.com
What the Benchmarks Don't Cover
No General Reasoning Scores
MMLU, GPQA, MATH-500, and competition math results are absent from the announcement and the model card. For Flash models, Google has historically published a broader benchmark suite. Gemini 3.1 Pro, for instance, showed consistent reasoning scores alongside its agentic numbers. The 3.5 Flash launch skips this.
Gemini 3.1 Pro consistently beats Flash by three to eight percentage points on knowledge benchmarks. Not publishing those numbers for 3.5 Flash doesn't mean it scores worse - but it does mean developers building knowledge-intensive applications are working without data.
The SWE-Bench Caveat
The SWE-Bench situation deserves its own paragraph. Google reports 55.1% on SWE-Bench Pro - a legitimate, harder benchmark that Scale AI built specifically because SWE-Bench Verified had become unreliable. Verified uses 500 Python-only tasks where many require only one or two line changes; OpenAI stopped reporting Verified scores after auditing for training contamination.
Pro uses 1,865 tasks across four languages, every one requiring at least 10 lines of change. The gap between the two benchmarks is dramatic: models that score 70%+ on Verified drop to 20-30% on Pro. Gemini 3.5 Flash's 55.1% on Pro is a genuine result, but it ranks third behind Claude Opus 4.7 at 64.3% and GPT-5.5 at 58.6%. On real multi-file code changes, it sits behind its two main proprietary competitors.
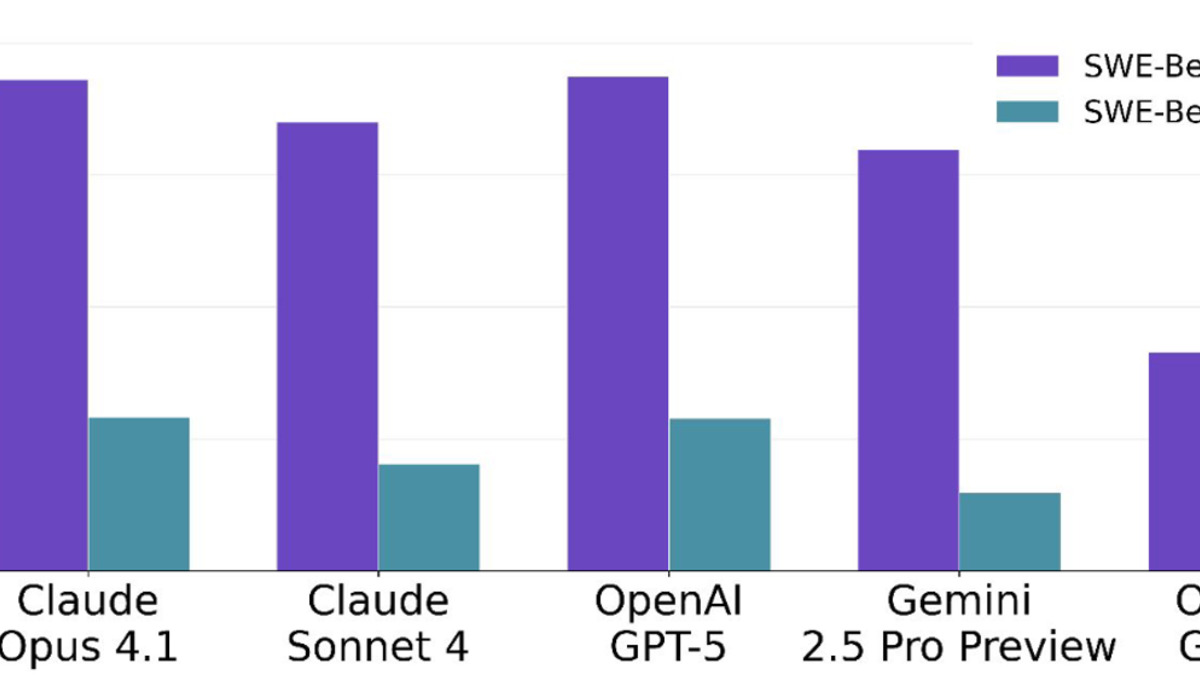 SWE-Bench Pro exposes a large gap from the easier Verified benchmark. Gemini 3.5 Flash sits third at 55.1% on Pro.
Source: scale.com
SWE-Bench Pro exposes a large gap from the easier Verified benchmark. Gemini 3.5 Flash sits third at 55.1% on Pro.
Source: scale.com
The 1M-Token Accuracy Drop
Google markets a 1M-token context window as a headline feature. The MRCR v2 retrieval accuracy numbers buried in the technical documentation tell a more complicated story: 77.3% at 128K tokens, falling to 26.6% at 1M tokens. That's not catastrophic - it's roughly where most frontier models are at that scale - but it's far from what developers imagining "1M context" as near-perfect retrieval should expect.
Subquadratic's SubQ model claimed 65.9% MRCR v2 at 1M tokens when it launched earlier this month, using a purpose-built sparse attention architecture. That benchmark comparison isn't apples-to-apples since SubQ's numbers come from Subquadratic itself and haven't been independently verified either. The broader point stands: 1M-token context and reliable 1M-token retrieval are different things.
The Pricing Jump
Earlier Flash-series models priced at $0.10-0.30 per million tokens. Gemini 3.5 Flash opens at $1.50 input and $9.00 output. That's a 5-15x increase from where the Flash brand started.
All three major labs are testing price tolerance this quarter. Gemini 3.5 Flash, Claude Sonnet, GPT-5.5 Instant - none of them are cheap compared to last year's equivalent tier.
The Hacker News thread on the announcement reached 951 points and 653 comments, with pricing the dominant topic. Developers building at scale noticed right away. For high-volume agentic workloads doing thousands of tool calls, $9.00 per million output tokens adds up differently than $0.30 did.
The cached-input pricing at $0.15 per million tokens - a 90% discount - is the pressure valve. Applications that can structure prompts to maximize cache hits get something close to the old Flash pricing on the read side.
Should You Care?
The speed is real. 289 tok/s output throughput matters for agentic tasks where you're doing many sequential API calls per workflow. At that speed, latency stops being a bottleneck in agent chains that used to require parallel execution hacks just to keep up.
The agentic benchmarks are strong where they count for agentic use cases. Terminal-Bench 2.1 and MCP Atlas aren't made-up metrics - they test real things. If you're building tool-calling agents, the model performs.
The gaps matter depending on your application. Knowledge retrieval, general reasoning, math: no data. Long-context retrieval at the 1M-token end: known degradation. Coding against multi-file real-world repos: third place by a 9-point margin behind the current leader.
The full technical review at our models page has the complete spec breakdown. The hands-on review covers practical agentic performance.
For teams already on the Gemini platform, 3.5 Flash is a clear upgrade over 3.1 Flash. The speed improvement alone justifies testing it. For teams choosing between providers, the missing benchmark coverage means running your own evals rather than trusting the announcement numbers.
Sources:
- Gemini 3.5 Flash Official Announcement - Google Blog
- Gemini 3.5 Flash Deep Dive - Appwrite
- SWE-Bench Pro: Raising the Bar for Agentic Coding - Scale AI
- SWE-Bench Pro Leaderboard - Scale AI Labs
- Why SWE-Bench Verified No Longer Measures Frontier Coding - OpenAI
- Gemini 3.5 Flash Benchmark Analysis - NxCode
- Gemini 3.5 Flash - Hacker News Discussion
- Long-Context Accuracy Analysis - Quantum Zeitgeist
