Google Ships Gemini 3.1 Flash TTS With 200 Audio Tags
Google's new Gemini 3.1 Flash TTS hits Elo 1,211 on the Artificial Analysis leaderboard and introduces 200-plus audio tags for mid-sentence voice control, available in preview today via the Gemini API.

Google shipped Gemini 3.1 Flash TTS today in public preview, and its headline claim isn't voice quality - it's control. The model introduces 200-plus audio tags that let developers direct emotion, pace, and non-verbal sounds mid-sentence using square-bracket syntax embedded in the input text. It also posts an Elo score of 1,211 on the Artificial Analysis TTS Arena, which puts it in the "most attractive quadrant" for quality-to-cost ratio on that benchmark.
The model ID is gemini-3.1-flash-tts-preview and it's live now on the Gemini API, Google AI Studio, and Vertex AI. Google Vids integration went out to Workspace users the same day.
Key Specs
| Spec | Value |
|---|---|
| Model ID | gemini-3.1-flash-tts-preview |
| Status | Public preview |
| Voices | 30 prebuilt (named after astronomical objects) |
| Languages | 70+ |
| Audio tags | 200+ |
| Output format | PCM 24kHz mono, 16-bit |
| Multi-speaker | Up to 2 speakers per request |
| SynthID | Enabled on all outputs |
| Streaming | Not supported |
Comparing the Field
Before getting into what makes this model different, the competitive context:
| Model | Elo Score | Languages | Audio tags / style control | Price (approx.) | Streaming |
|---|---|---|---|---|---|
| Gemini 3.1 Flash TTS | 1,211 | 70+ | 200+ audio tags | $0.018/min equiv. | No |
| ElevenLabs (v3) | Not published | 30+ | Style sliders, voice cloning | Higher at scale | Yes |
| OpenAI gpt-4o-mini-tts | Not published | 57 | Speaking style instructions | ~$0.018/min | Yes |
| Mistral Voxtral TTS | Not published | 9 | Zero-shot voice cloning | $0.016/1,000 chars | Yes |
| Gemini 3.1 Flash Live | Separate eval | 90+ | Real-time conversational | $0.35/hr audio in | Yes (real-time) |
ElevenLabs remains the industry reference for voice naturalness and cloning quality. OpenAI's gpt-4o-mini-tts supports streaming, which Google's new model doesn't. Mistral's Voxtral trades multilingual breadth for open weights and a 9-language limit. Google's play here is controllability at scale - 70+ languages, a broad voice library, and the audio tags system nobody else has shipped in this form.
The Audio Tags System
This is the part that actually changes how developers write prompts. Instead of selecting a voice style once at the API call level, audio tags let you embed performance directions inline with the text itself.
Syntax and Rules
Tags use square brackets: [determination], [whispers], [short pause]. You can stack them with text between, but the system prohibits placing two tags directly adjacent without intervening text or punctuation. A working example from Google's documentation, in French:
[cautious] L'ombre avança lentement dans la pièce silencieuse. [whispers] Le document secret devait être caché ici. [short pause] Mais où? [gasp] Soudain, un bruit sourd résonna dans le couloir [panic] Il fallait sortir d'ici immédiatement.
That sequence moves through cautious narration, a whisper, a pause, a gasp, and panic - all in one API call. The text is French. The tags are English-only. The model keeps the language of the spoken output while responding to English instructions in the markup.
What the Tags Control
Four categories: emotional state ([determination], [frustration], [nervousness], [excitement]), non-verbal sounds ([laughs], [sighs], [gasp], [crying]), pacing ([slow], [fast], [short pause], [long pause]), and tone ([sarcastic], [positive], [neutral], [negative]). The full list runs to 200-plus entries according to the Cloud documentation, though the developer-facing docs reference a smaller subset.
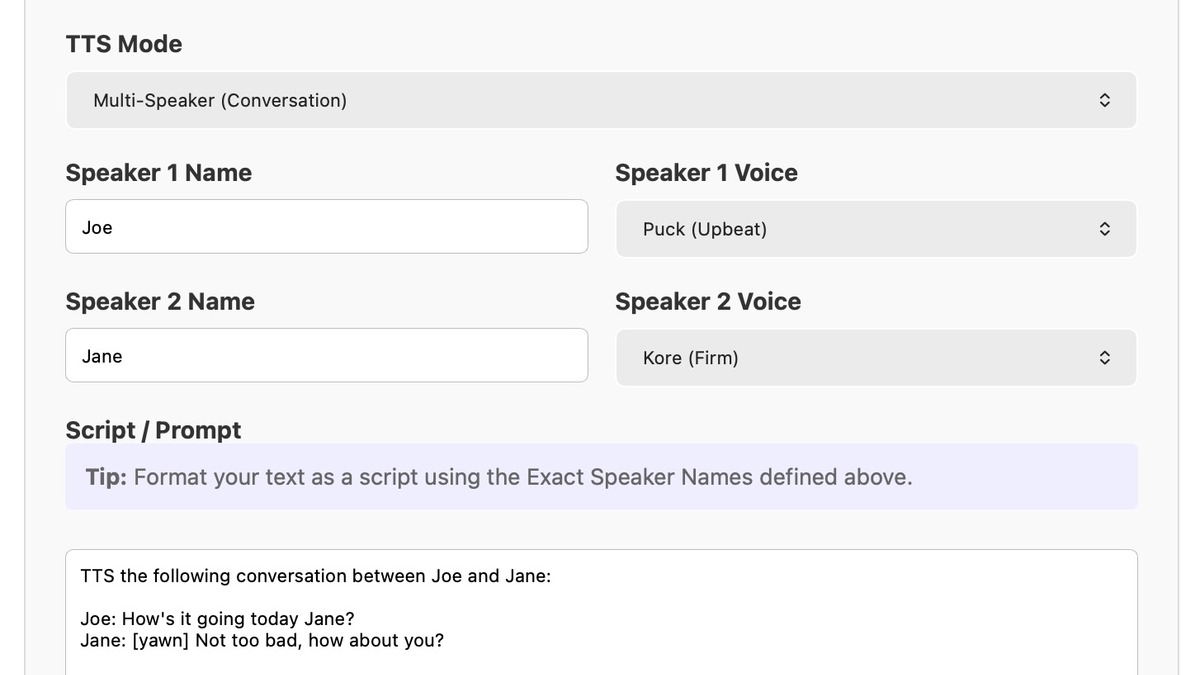 The Gemini 3.1 Flash TTS playground in Google AI Studio, showing the script input, speaker configuration, and one-click export to API code. Tested by Simon Willison on April 15, 2026.
Source: simonwillison.net
The Gemini 3.1 Flash TTS playground in Google AI Studio, showing the script input, speaker configuration, and one-click export to API code. Tested by Simon Willison on April 15, 2026.
Source: simonwillison.net
Google also introduced what it calls the Voice Director framework - a structured prompting pattern for the model. The recommended format: an Audio Profile describing the speaker's voice and character, a Scene describing the environment, Director's Notes on tone and accent, and then the transcript with tags embedded. Simon Willison tested this in practice on launch day and found the accent variation particularly effective - swapping in different UK regional references shifted the output accent measurably.
Technical Specs
Pricing and Access
The standard tier costs $1.00 per million input tokens and $20.00 per million output tokens. At 25 audio tokens per second, that works out to roughly $0.018 per minute of created audio. A batch tier halves both figures: $0.50 input, $10.00 output. Both figures land in the same range as OpenAI's TTS pricing.
The model is available via the Gemini API (generativelanguage.googleapis.com/v1beta/models/gemini-3.1-flash-tts-preview:generateContent), through Google AI Studio's audio playground at aistudio.google.com/app/generate-speech, and on Vertex AI for enterprise accounts. Google also published a Colab quickstart in the google-gemini/cookbook repository.
Voices and Languages
Thirty prebuilt voices cover the library, all named after astronomical objects: Zephyr, Puck, Charon, Kore, Fenrir, Leda, and 24 more. Language support runs to 70-plus, with auto-detection available. The audio tags are English-only even when the spoken output is in another language.
The Python SDK call for a single speaker:
from google import genai
from google.genai import types
client = genai.Client()
response = client.models.generate_content(
model="gemini-3.1-flash-tts-preview",
contents="[enthusiasm] Welcome to today's session! [slow] Let's begin with the basics.",
config=types.GenerateContentConfig(
response_modalities=["AUDIO"],
speech_config=types.SpeechConfig(
voice_config=types.VoiceConfig(
prebuilt_voice_config=types.PrebuiltVoiceConfig(voice_name='Kore')
)
)
)
)
Multi-Speaker Support
Multi-speaker output works in a single API call, with a current cap of two speakers. You assign names and voice configurations to each speaker, and the model handles turn-taking rhythm without you managing timing manually. Two speakers only - no ensemble casts.
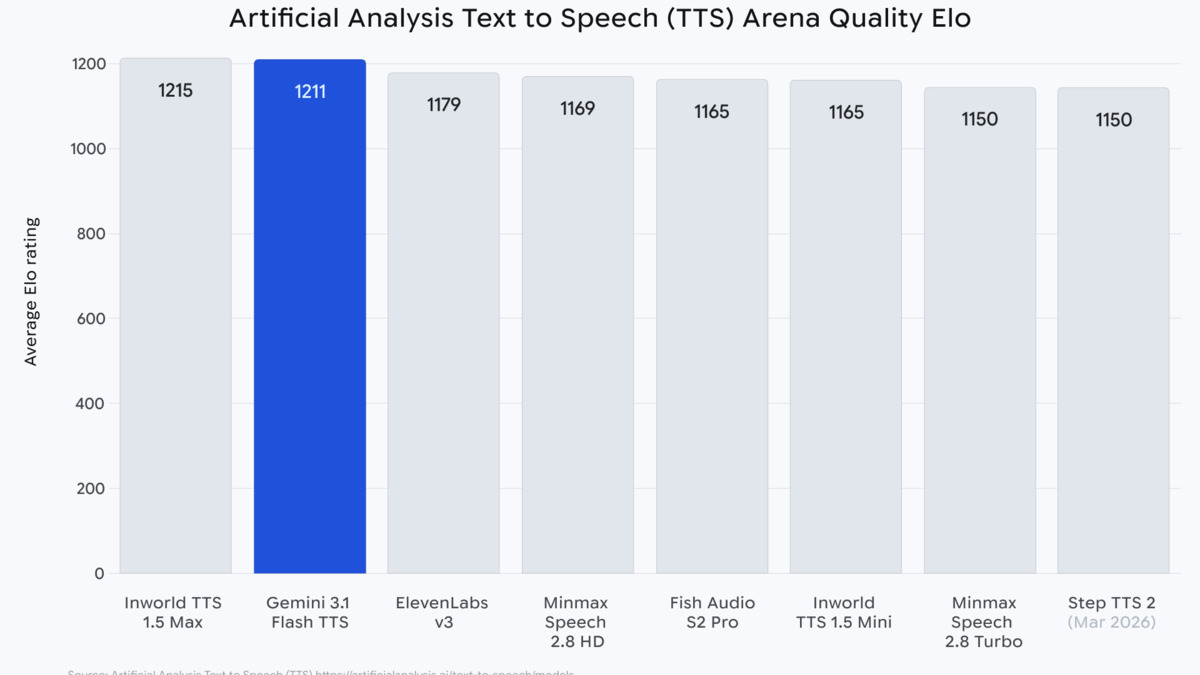 The Artificial Analysis TTS Arena places Gemini 3.1 Flash TTS at Elo 1,211, in the "most attractive quadrant" combining quality and cost-efficiency. Released with the official Google blog post on April 15, 2026.
Source: blog.google
The Artificial Analysis TTS Arena places Gemini 3.1 Flash TTS at Elo 1,211, in the "most attractive quadrant" combining quality and cost-efficiency. Released with the official Google blog post on April 15, 2026.
Source: blog.google
SynthID Watermarking
Every audio output from Gemini 3.1 Flash TTS carries an embedded SynthID watermark. The markers are imperceptible to listeners and don't degrade audio quality. The stated purpose is making AI-produced audio detectable, which matters as audio deepfakes become a routine policy and legal concern. Google doesn't publish the false-positive or false-negative rates for SynthID audio detection, so the practical robustness of the watermark against adversarial processing remains an open question.
Google's play here is controllability at scale - 70-plus languages, a broad voice library, and an audio tags system nobody else has shipped in this form.
What It Does Not Tell You
The Elo score of 1,211 comes from Artificial Analysis's human preference blind tests. Those tests measure general voice attractiveness, not task-specific performance. Naturalness under stress, accuracy in technical pronunciation, or voice consistency across long documents are different questions - and none of those results appear in the launch materials.
Streaming isn't supported. Compared with Gemini 3.1 Flash Live, which runs real-time conversational audio at around 960ms latency, Flash TTS is a batch system. For applications that need low-latency streaming - live reading assistants, real-time narration - you'd use Flash Live or OpenAI's streaming TTS instead.
The two-speaker cap is a real constraint. Podcast-style content with three or more distinct voices requires multiple API calls and your own stitching logic. ElevenLabs handles larger voice ensembles natively.
Audio tags are English-only for the instruction syntax, even though the spoken text can be in 70-plus languages. Developers building non-English audio-tagged content need to keep track of which part of their input is language-directive versus spoken output - a workflow wrinkle Google doesn't address directly in the documentation.
The model is also still in preview. Pricing and feature set can change before GA.
 Logan Kilpatrick, Product Lead for Google AI Studio and the Gemini API, announced the model on X on April 15, 2026.
Source: blog.google
Logan Kilpatrick, Product Lead for Google AI Studio and the Gemini API, announced the model on X on April 15, 2026.
Source: blog.google
The audio tags system is the meaningful technical contribution here - not the benchmark number. The AI Voice Speech Leaderboard and the best voice generators comparison both reflect a market where ElevenLabs leads on quality and cloning while open-weights alternatives like Voxtral undercut on price. Flash TTS sits between them, trading voice cloning and streaming for the widest language coverage and the most granular mid-sentence control any commercial TTS API has shipped so far. Whether developers find the audio tags system worth the workflow complexity over simpler prompt-level style instructions is a question the preview period will answer.
Sources:
Last updated
