Gemini Flash Live Edges GPT-4 Realtime in Voice AI Race
Google's Gemini 3.1 Flash Live beats GPT-4 Realtime 1.5 on Scale AI's Audio MultiChallenge and takes Search Live to 200+ countries - but it doesn't lead every benchmark.

Google's Gemini 3.1 Flash Live is a real-time multimodal voice model that now leads Google's Scale AI Audio MultiChallenge score over GPT-4 Realtime 1.5, narrows the gap on conversational function-calling, and carries Search Live into 200+ countries simultaneously. The announcement landed on March 26, and it's the most complete update to Google's voice AI stack since the Gemini 2.5 generation.
TL;DR
- Replaces Gemini 2.5 Flash Native Audio; available in Gemini API and Google AI Studio from day one
- Scale AI Audio MultiChallenge: 36.1% - beats GPT-4 Realtime 1.5 at 34.7%
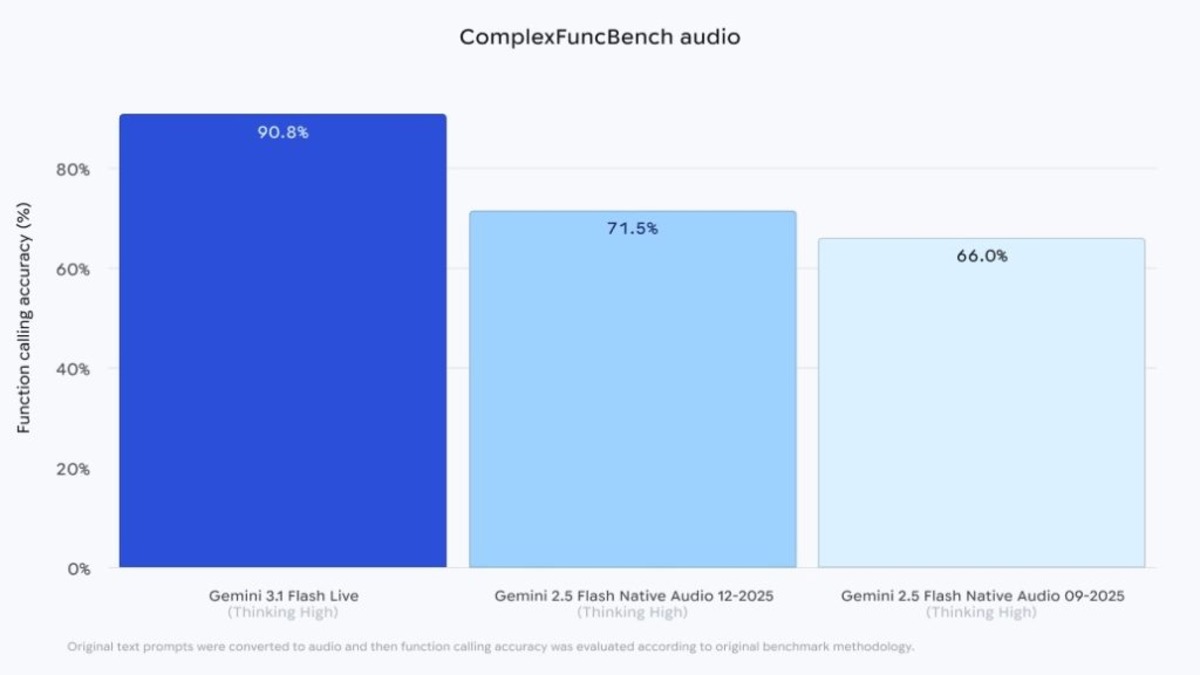
- ComplexFuncBench Audio (multi-step tool calls): 90.8%, up from 71.5% on the predecessor
- Context window doubles to 128K; supports audio, images, video, and text input
- Search Live goes global: 200+ countries, 90+ languages
- Pricing unchanged: $0.35/hour audio input, $1.40/hour audio output
 Google announced Gemini 3.1 Flash Live on March 26, 2026, calling it its "highest-quality audio and voice model yet."
Source: 9to5google.com
Google announced Gemini 3.1 Flash Live on March 26, 2026, calling it its "highest-quality audio and voice model yet."
Source: 9to5google.com
What Changed Under the Hood
The model processes audio natively rather than transcribing speech to text first. That means it picks up pitch, pace, and emotional cues that text-based pipelines strip out. Background noise filtering is improved too: in testing, it's better at separating a voice from TV audio, traffic, and other ambient sound that made earlier versions stumble.
Context and Memory
The 128K context window is double what the predecessor offered. Google describes the practical effect as the model being able to "follow a conversation thread twice as long" before losing track of earlier turns. For developers building voice agents that need to maintain state across extended interactions - customer service bots, tutoring sessions, medical intake calls - that's a real constraint removed rather than a number on a spec sheet.
Tool Calling During Live Sessions
The jump on ComplexFuncBench Audio is the sharpest improvement: from 71.5% to 90.8%. This benchmark specifically tests multi-step function calling mid-conversation, which is the core requirement for any production voice agent that needs to look up data, trigger backend actions, or chain API calls while the user is still talking. A 19-point gain on that specific task matters more for agentic deployments than raw speech quality scores.
How It Compares
| Benchmark | Gemini 3.1 Flash Live (High) | GPT-4 Realtime 1.5 | Step-Audio R1.1 Realtime |
|---|---|---|---|
| Scale AI Audio MultiChallenge | 36.1% | 34.7% | - |
| ComplexFuncBench Audio | 90.8% | - | - |
| Big Bench Audio | 95.9% | - | 97.0% |
| Languages supported | 90+ | 50+ | - |
| Audio input price | $0.35/hr | varies | - |
| Audio output price | $1.40/hr | varies | - |
Google claims first place on Scale AI's Audio MultiChallenge, edging out GPT-4 Realtime 1.5 by 1.4 points. On Big Bench Audio - a speech reasoning benchmark - it scores 95.9% at High thinking mode, but Step-Audio R1.1 Realtime from Stepfun still leads at 97.0%. That gap is modest but real.
The "thinking" modes are a notable design choice. High mode trades latency for accuracy; Minimal mode drops Big Bench Audio from 95.9% to 70.5% in exchange for faster response times. Developers choose at call time, which gives them a knob to tune quality versus speed per interaction type rather than a single fixed tradeoff.
 Benchmark results for Gemini 3.1 Flash Live across Scale AI Audio MultiChallenge and ComplexFuncBench Audio.
Source: 9to5google.com
Benchmark results for Gemini 3.1 Flash Live across Scale AI Audio MultiChallenge and ComplexFuncBench Audio.
Source: 9to5google.com
The Search Live Expansion Is the Bigger Story
Voice quality benchmarks matter to developers building with the API. The Search Live global rollout matters to everyone else.
Search Live launched in the US in July 2025 with voice and camera input. It expanded to India shortly after. The March 26 update extends it to 200+ countries and territories where AI Mode is available, serving 90+ languages. That's a consumer distribution play that no benchmark can measure.
The feature lets users point their phone camera at something and ask questions in real time - a live Google Lens session with voice output instead of text cards. Powered by Gemini 3.1 Flash Live, the global rollout means a French speaker in Marseille can now ask "what's wrong with this plant?" and get a voiced answer while their camera is still on it. That was a US-only product feature three months ago.
Gemini Live App Updates
The Gemini Live app on Android and iOS is also updated to use the new model. The app received a floating pill interface redesign in February that lets users multitask while in a voice session - continue browsing or working while Gemini listens and responds. The combination of the redesigned UI and the improved model is the version that ends up in most users' hands.
 The Gemini Live floating pill UI, introduced in February 2026, lets users stay in a voice session while multitasking on Android.
Source: 9to5google.com
The Gemini Live floating pill UI, introduced in February 2026, lets users stay in a voice session while multitasking on Android.
Source: 9to5google.com
What It Does Not Tell You
Google's announcement doesn't publish a latency figure. The claim is "lower latency" than the predecessor but no millisecond number appears in the model card or the blog post. OpenAI has long cited sub-320ms for its Realtime API. Without a comparable figure from Google, the latency comparison is one-sided.
The Minimal Mode Drop Is Steep
The High/Minimal thinking tradeoff is sharper than it looks in the table. Minimal mode drops Big Bench Audio from 95.9% to 70.5% - a 25-point fall. That means developers using Minimal mode for speed are working with a model that performs clearly worse at speech reasoning. The modal split is opaque from the outside: users interacting with a product powered by this model won't know which mode the developer chose.
Pricing Is Flat, Not Cheap
$0.35/hour for audio input and $1.40/hour for audio output keeps pricing consistent with Gemini 2.5 Flash Native Audio. That's a selling point relative to per-token voice APIs that can run much higher. But it's also worth noting the price didn't drop despite the capability increase. For high-volume deployments, the cost envelope doesn't improve even as the quality ceiling rises.
Coverage Against Competitors Is Incomplete
Google's benchmark table covers Scale AI Audio MultiChallenge and ComplexFuncBench Audio but doesn't include head-to-head numbers for Tencent's Covo-Audio, Mistral's Voxtral, or other voice models entering the market this year. The competitive picture is framed entirely around GPT-4 Realtime, which is a useful comparison but not a complete one.
Google's voice AI stack is truly stronger today than it was last week. A near-20-point gain on multi-step tool calling is something agent developers will notice immediately, and the Search Live global rollout puts this technology in front of far more users than any API benchmark reflects. The missing latency numbers and the Minimal mode quality cliff are legitimate open questions - but neither undermines the substance of what shipped on March 26.
Sources:

