Cursor Ships Composer 2 - Its First In-House Coding Model
Cursor launches Composer 2, its first in-house coding model trained via RL on long-horizon tasks, scoring 73.7 on SWE-bench Multilingual at $0.50/M input tokens.

Cursor shipped Composer 2 today - a new code-specialized model built completely in-house - ending its full dependence on third-party model providers for its core coding assistant.
TL;DR
- First model Cursor trained from scratch using continued pretraining and reinforcement learning on long-horizon coding tasks
- Scores 73.7 on SWE-bench Multilingual, up from 65.9 with Composer 1.5
- Priced at $0.50/M input, $2.50/M output (standard) - well below frontier model rates
- Available now in Cursor with a fast variant ($1.50/M input, $7.50/M output) as the default
Until now, Cursor routed its Composer feature through third-party models like Claude and GPT variants. Composer 2 changes that. It's trained on code-only data, tuned for multi-step agent tasks that span hundreds of sequential actions, and priced to be the default choice rather than the premium one.
How Cursor Built It
The blog post describes a two-phase training pipeline, and both phases represent firsts for the company. Previous Cursor models were API wrappers over third-party providers; Composer 2 is the first one Cursor actually trained.
Phase 1 - Continued Pretraining on Code
Cursor describes Composer 2 as their "first continued pretraining run." That means starting from a base model and training further on a large code-specific corpus before any instruction tuning. The result, according to Cursor, is "a far stronger base to scale their reinforcement learning" - a foundation that responds better to the RL signal because it already knows how code behaves at a structural level.
This is the same playbook used by DeepSeek Coder and CodeLlama: take a capable general base model, soak it in code for an extended pretraining phase, then layer higher-level training on top. Cursor doesn't disclose the base model, training data size, or parameter count.
Phase 2 - Reinforcement Learning on Long-Horizon Tasks
The RL phase trains specifically on "long-horizon coding tasks" - problems that require planning sequences of many actions rather than generating a single response. Cursor says Composer 2 can solve tasks requiring "hundreds of actions," which maps to real-world agent scenarios: refactoring a feature across a codebase, writing and debugging a test suite, or building and iterating on a working component end-to-end.
This distinguishes it from models optimized for short code completion or single-shot generation. The RL objective pushes the model to maintain coherent goals across long agent rollouts, where early mistakes compound.
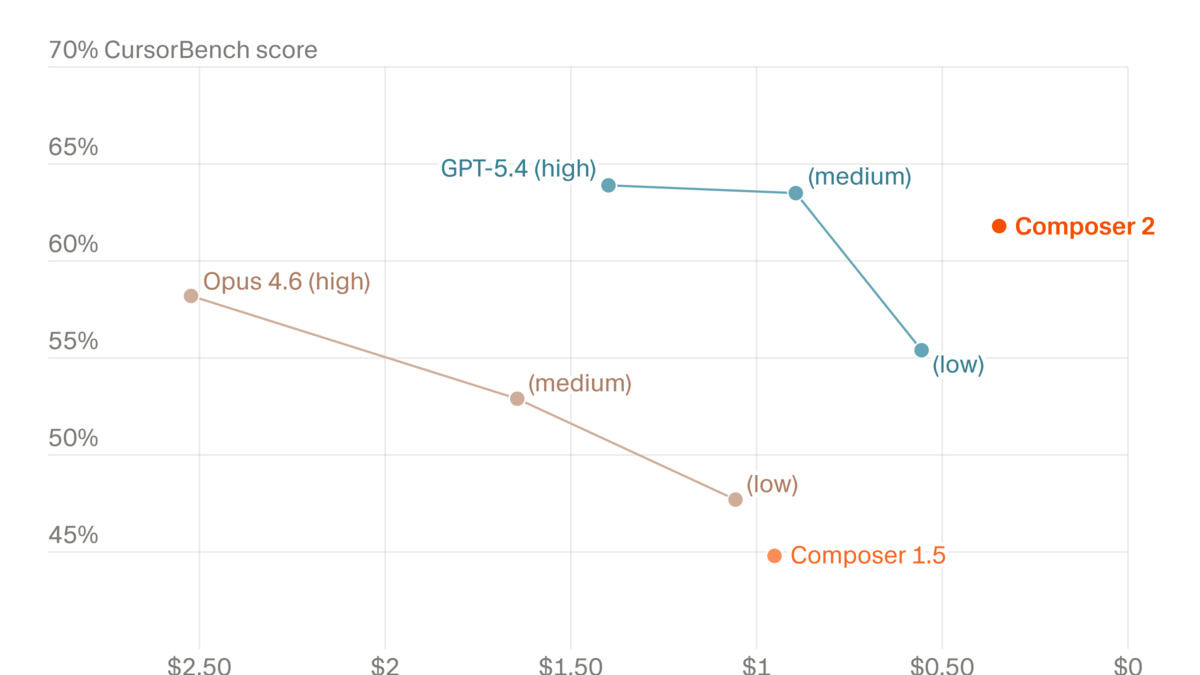 Performance vs. cost on CursorBench. Composer 2 sits at the bottom-left of the frontier cluster - highest score among the low-cost options.
Source: cursor.com
Performance vs. cost on CursorBench. Composer 2 sits at the bottom-left of the frontier cluster - highest score among the low-cost options.
Source: cursor.com
What the Numbers Show
Cursor publishes three benchmarks for Composer 2, all compared against its predecessor versions. Two are external (Terminal-Bench 2.0 and SWE-bench Multilingual); one is proprietary (CursorBench).
| Benchmark | Composer 1 | Composer 1.5 | Composer 2 | Gain over 1.5 |
|---|---|---|---|---|
| CursorBench | 38.0 | 44.2 | 61.3 | +17.1 |
| Terminal-Bench 2.0 | 40.0 | 47.9 | 61.7 | +13.8 |
| SWE-bench Multilingual | 56.9 | 65.9 | 73.7 | +7.8 |
CursorBench
This is Cursor's internal benchmark measuring performance on realistic coding tasks in their own editor environment. Composer 2 scores 61.3, a 39% improvement over Composer 1.5. Take internal benchmarks at face value with appropriate skepticism - Cursor designed it, and the tasks are optimized for their own use cases.
Terminal-Bench 2.0
Terminal-Bench 2.0 is an independent evaluation from the Laude Institute that tests agent performance on terminal-based coding tasks. Cursor scores 61.7 here, which puts it above Claude Opus 4.6 (58.0) but below GPT-5.4 (75.1) based on the bar chart published in the launch post. Cursor notes methodology differences: Anthropic models were scored using the Claude Code harness, OpenAI models used the Simple Codex harness, and Cursor used the Harbor evaluation framework. Cross-harness comparisons aren't apples-to-apples, but Terminal-Bench 2.0 is at least an external number rather than a proprietary one.
SWE-bench Multilingual
SWE-bench Multilingual extends the original SWE-bench (real GitHub issues) to multiple programming languages. A score of 73.7 is strong for a specialized coding model in this price range. For context, Alibaba's SWE-CI agents targeting long-term code maintenance posted different metrics in a different evaluation framework earlier this year - direct comparisons across papers require care.
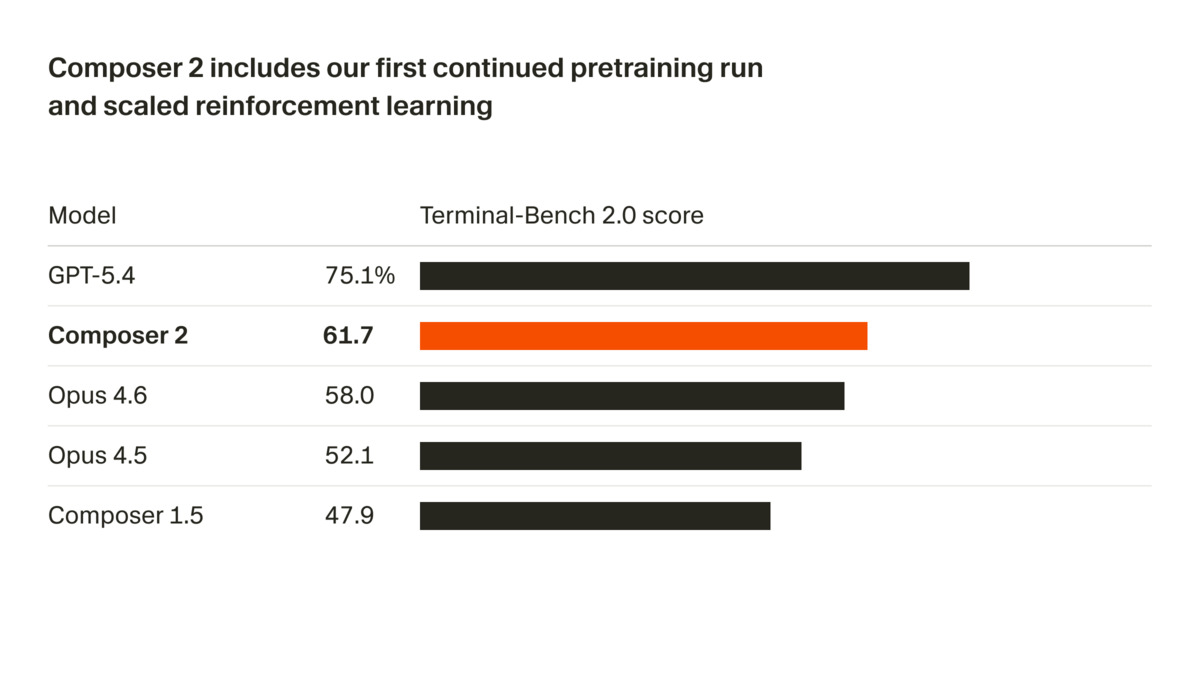 Terminal-Bench 2.0 scores from the Cursor launch post. GPT-5.4 leads, but Composer 2 beats both Opus 4.6 versions despite costing far less.
Source: cursor.com
Terminal-Bench 2.0 scores from the Cursor launch post. GPT-5.4 leads, but Composer 2 beats both Opus 4.6 versions despite costing far less.
Source: cursor.com
Using Composer 2 in Practice
Composer 2 is available directly in the Cursor editor. The fast variant is the default. Both variants are selectable in the model picker - composer-2 for the standard tier and composer-2-fast for the lower-latency option.
Cursor supports .cursorrules files that give the AI context about a project. Since Composer 2 handles long agent rollouts well, teams are pairing it with detailed rules files that lay out codebase conventions upfront - reducing mid-task context drift across hundreds of actions:
# .cursorrules
## Project: payments-api
- Language: TypeScript, Node.js 22
- Testing: Vitest, no mocking of database calls
- Commits: conventional commits, no WIP commits on main
- When refactoring: update tests in the same commit, not separately
The model handles multi-file edits, test generation, and iterative debugging within the same session. Because it was trained specifically on long agent rollouts, it performs best on tasks that benefit from planning ahead rather than tasks requiring a single short code snippet.
For teams using the Cursor API for automated code review or agent pipelines, the token pricing makes Composer 2 attractive compared to routing through Anthropic or OpenAI directly - especially at scale.
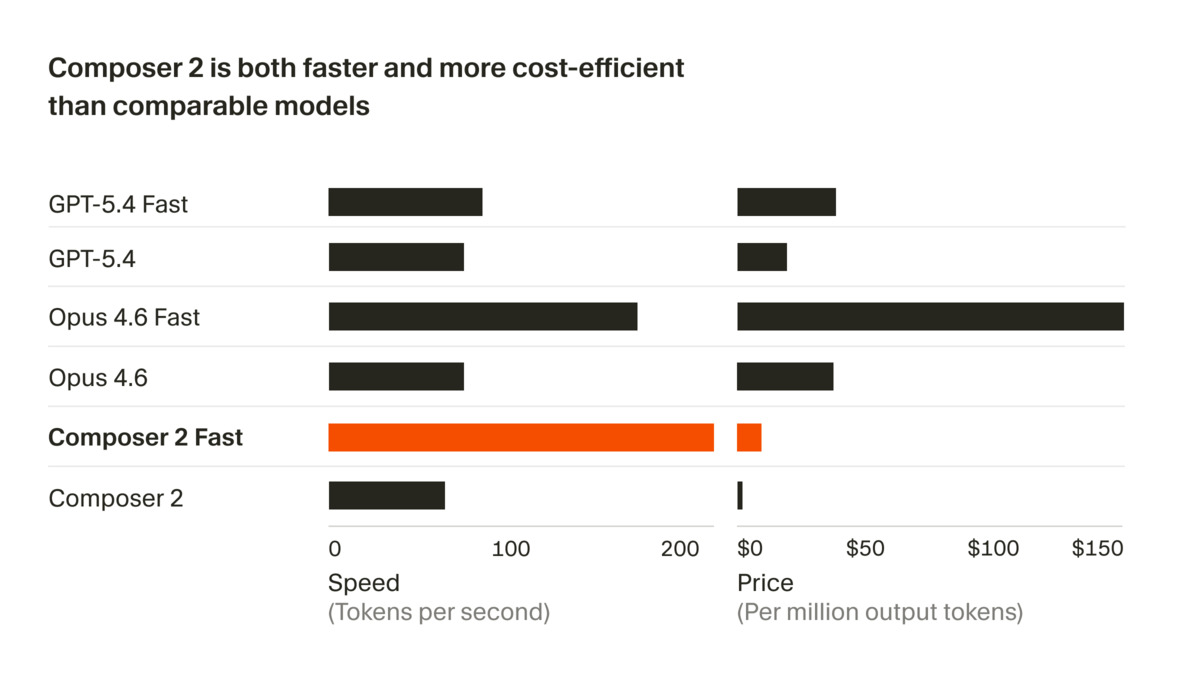 The fast variant positions itself as faster and cheaper than equivalent frontier model outputs.
Source: cursor.com
The fast variant positions itself as faster and cheaper than equivalent frontier model outputs.
Source: cursor.com
Pricing and Compatibility
| Variant | Input (per 1M tokens) | Output (per 1M tokens) | Notes |
|---|---|---|---|
| Composer 2 Standard | $0.50 | $2.50 | Slower, lower cost |
| Composer 2 Fast | $1.50 | $7.50 | Default in Cursor |
| Claude Opus 4.6 | ~$15 | ~$75 | For reference |
| GPT-5.4 Standard | ~$10 | ~$30 | For reference |
Composer 2 is available on Cursor's Hobby (free), Pro ($20/mo), Pro+ ($60/mo), and Ultra ($200/mo) plans. Individual plans include it within their usage pools. Business and Enterprise plans get access with the same model controls and API audit capabilities.
Access to Cursor Cloud Agents - the fully autonomous VM-based coding agents Cursor shipped in March - runs separately and uses its own compute pricing.
Where It Falls Short
The benchmark picture has gaps worth knowing about.
Cursor published only benchmarks it chose. There's no MMLU, HumanEval, or LiveCodeBench score to anchor Composer 2 against the broader field. The CursorBench numbers are high, but they're internal - designed to reward the behaviors Cursor cares about in their own product. That isn't necessarily a flaw, but it limits external validation.
The Terminal-Bench 2.0 gap matters too. GPT-5.4 scores 75.1% on the external benchmark; Composer 2 scores 61.7%. On the task types Terminal-Bench measures, there's a real performance gap. Whether that gap shows up in day-to-day coding tasks depends heavily on what you're building.
There's also no information on context window size, training data composition, or model parameter count. For an infrastructure reporter, that's a striking omission. You can't assess fit for large-codebase scenarios, fine-tuning potential, or inference hardware requirements without knowing the architecture basics.
Cursor has been moving fast - automations that trigger agents from GitHub PRs and Slack, cloud agents that run in isolated VMs, $2B ARR hit in record time - and Composer 2 fits that trajectory. Training your own model reduces per-token costs and removes a key third-party dependency. For a company at this growth rate, that's a rational infrastructure move regardless of whether Composer 2 beats GPT-5.4 on every task.
The practical question is whether $0.50/M input and a 39% benchmark improvement over Composer 1.5 makes it the default choice for developer teams. For most Cursor users already inside the monthly plan, that pricing calculation is invisible - the model is just the one Cursor chose for them.
Sources:

