ByteDance Trained an AI Agent That Writes Faster CUDA Kernels Than You
CUDA Agent uses reinforcement learning trained on actual GPU profiling data to generate optimized CUDA kernels. It beats torch.compile by 2.11x overall and outperforms Claude Opus 4.5 and Gemini 3 Pro by 40 points on the hardest kernels.
Most AI code generation optimizes for correctness. Does it compile? Does it pass tests? Good enough. But CUDA kernel performance has nothing to do with correctness. A kernel that produces the right answer can still be 10x slower than it should be because of bank conflicts, uncoalesced memory access, or poor occupancy. The difference between a correct kernel and a fast kernel is hardware expertise that most developers don't have and most LLMs were never trained to learn.
ByteDance and Tsinghua University just published CUDA Agent - a reinforcement learning system that trains a model to write optimized CUDA kernels by rewarding actual GPU speed, not just code correctness. The results: 2.11x geometric mean speedup over torch.compile across 250 kernels, 100% faster-than-compile rate on simple and medium kernels, and 90% on the hardest fused operations.
TL;DR
- CUDA Agent trains a 230B MoE model (23B active) via reinforcement learning where the reward signal is real GPU profiling data - not compilation success or test pass rates
- Achieves 2.11x geometric mean speedup over
torch.compileacross the 250-kernel KernelBench benchmark - Beats Claude Opus 4.5 (1.46x) and Gemini 3 Pro (1.42x) by wide margins - 40 percentage points higher faster-than-compile rate on Level 3 complex kernels
- The agent autonomously profiles, diagnoses bottlenecks, rewrites kernels, and iterates - up to 200 turns of tool-assisted optimization per task
- Four-stage training pipeline: PPO warm-up, rejection fine-tuning, critic pretraining, then full agentic RL - without this, training collapsed at step 17
- Dataset (CUDA-Agent-Ops-6K) is synthetic and contamination-screened against the evaluation set
The core insight
Standard LLM code generation treats CUDA like any other programming language: generate code, check if it runs, maybe iterate on errors. But CUDA performance is about hardware. Warps, memory coalescing, shared memory tiling, bank conflicts, register pressure, occupancy - the things that only show up in a profiler and that no amount of syntax correctness will fix.
CUDA Agent flips the reward function. Instead of "did it compile?" the agent is rewarded based on a four-tier scale:
| Reward | Condition |
|---|---|
| -1 | Correctness verification fails |
| 1 | Correct but no speedup |
| 2 | Faster than PyTorch eager mode only |
| 3 | Faster than both eager AND torch.compile by at least 5% |
The profiling uses device synchronization, warm-up iterations, and repeated measurements with averaging. The target: beat torch.compile on real hardware. Not theoretically. Not on paper. In the profiler.
The numbers
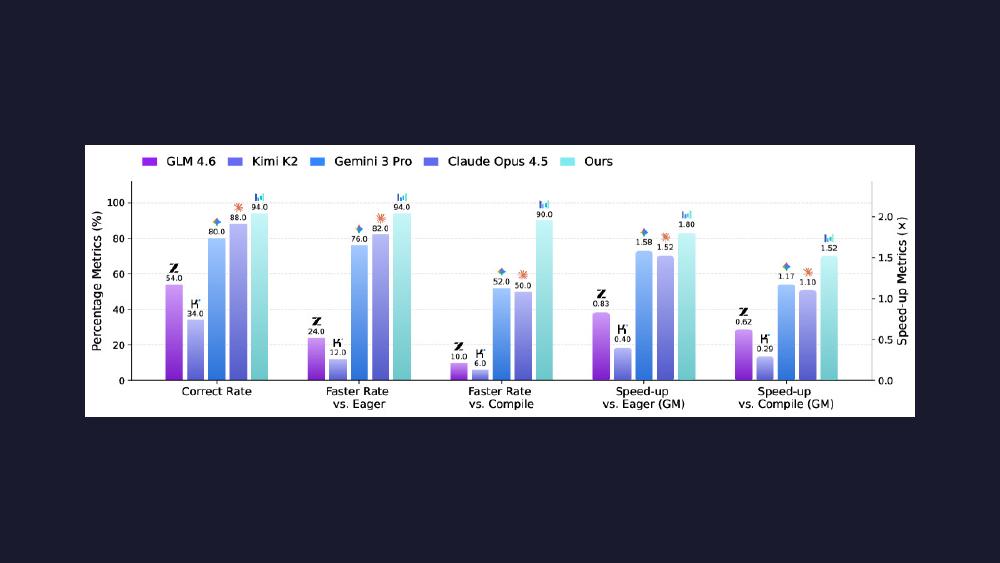
CUDA Agent was assessed on KernelBench, a 250-kernel benchmark spanning three difficulty levels: 100 simple single-operator kernels (Level 1), 100 medium operator-fusion tasks (Level 2), and 50 complex fused operations like ResNet BasicBlocks (Level 3).
Overall (250 kernels)
| Model | Pass Rate | Faster vs Compile | Speedup (Geomean) |
|---|---|---|---|
| CUDA Agent | 98.8% | 96.8% | 2.11x |
| Claude Opus 4.5 | 95.2% | 66.4% | 1.46x |
| Gemini 3 Pro | 91.2% | 69.6% | 1.42x |
| KernelBlaster | - | - | 1.43x |
| GLM 4.6 | - | - | 0.66x |
| Kimi K2 | - | - | 0.57x |
| Seed 1.6 (base model) | 74.0% | 27.2% | 0.69x |
The base model (Seed 1.6) starts at 0.69x - actually slower than torch.compile. After RL training, the same architecture hits 2.11x. That's a 3x improvement in effective speedup from RL alone, on the same model weights.
By difficulty level
| Level | CUDA Agent | Claude Opus 4.5 | Gemini 3 Pro |
|---|---|---|---|
| L1 (simple) - faster rate | 97% | 72% | 72% |
| L1 - speedup | 1.87x | 1.54x | 1.51x |
| L2 (medium) - faster rate | 100% | 69% | - |
| L2 - speedup | 2.80x | 1.60x | - |
| L3 (complex) - faster rate | 90% | 50% | 52% |
| L3 - speedup | 1.52x | 1.10x | 1.17x |
Level 2 is the standout: 100% faster-than-compile rate with a 2.80x geometric mean speedup. These are operator fusion tasks - exactly the kind of optimization where understanding memory access patterns and removing intermediate tensor materializations pays off most.
Level 3 is where the gap between CUDA Agent and frontier LLMs becomes a chasm. At 90% faster-than-compile versus Claude Opus 4.5's 50% and Gemini 3 Pro's 52%, CUDA Agent is 40 percentage points ahead on the hardest kernels. The pass rate drops to 94% (from 100% on L1/L2), showing that complex fused operations like full ResNet blocks still present genuine challenges.
The paper notes that ChatGPT-5 series models declined CUDA-related prompts and couldn't be assessed.
How the agent works
CUDA Agent operates in a ReAct-style loop with tool access: shell execution for compiling and profiling, file read/write/edit for kernel development, and search tools for navigating code. It runs up to 200 interaction turns per task during evaluation and 150 during training, all within a 131K token context window.
The agent follows a standardized workflow: analyze performance using provided profiler scripts, identify bottlenecks, implement a custom CUDA kernel, compile and test, then iterate on optimization until reaching at least 5% speedup over torch.compile. It's not a fixed pipeline - the agent autonomously decides when to profile, when to refactor, and when to try a different optimization strategy.
Five anti-gaming measures keep the reward honest: file permissions protect profiling scripts from modification, context managers block torch.nn.functional fallbacks, correctness is verified against five random inputs per the KernelBench protocol, profiling uses proper device synchronization and averaging, and the agent has no web search access.
The optimization hierarchy
The paper documents three tiers of GPU optimizations the agent learns to apply:
Priority 1 - Algorithmic (>50% gains): Kernel fusion to eliminate intermediate memory materialization, shared memory tiling, memory coalescing for consecutive thread-address access patterns.
Priority 2 - Hardware use (20-50% gains): Vectorized loads (float2/float4), warp primitives (__shfl_sync, __ballot_sync), occupancy tuning through block size and register allocation.
Priority 3 - Fine-tuning (<20% gains): Instruction-level parallelism, mixed precision (FP16/TF32), double buffering, loop unrolling, bank conflict avoidance in shared memory.
Advanced techniques include tensor core usage via WMMA/MMA instructions and persistent kernels. The agent learns to stack these techniques: fuse first for the big win, then optimize memory access patterns, then squeeze out the last percentages through hardware-specific tuning.
Training: why it nearly failed
The base model is ByteDance's Seed 1.6 - a 230B parameter sparse MoE with 23B active parameters. CUDA code comprises less than 0.01% of its pretraining data. That domain mismatch nearly killed the training process.
Without the multi-stage warm-up, RL training collapsed at step 17. The root cause: CUDA tokens have probability around 10^-9 in BF16 precision, causing importance sampling ratios in PPO to "fluctuate wildly or explode." The fix required four stages:
- Single-turn PPO warm-up on 6K synthetic operators to build basic CUDA capability
- Rejection fine-tuning - filter trajectories for reward > 0 and valid tool-use patterns, then supervised fine-tune
- Critic value pretraining using GAE to prevent pathological search during RL
- Full agentic RL via PPO - 150 steps, batch size 1024, 131K context
The ablation study shows every component matters:
| Configuration | Faster vs Compile | Speedup |
|---|---|---|
| Without agent loop (single-turn) | 14.1% | 0.69x |
| Without robust reward | 60.4% | 1.25x |
| Without rejection fine-tuning | 49.8% | 1.05x |
| Without critic pretraining | 50.9% | 1.00x |
| Full CUDA Agent | 96.8% | 2.11x |
Removing the agent loop drops the faster-than-compile rate from 96.8% to 14.1%. Removing any single warm-up stage cuts the rate roughly in half. The training recipe is as important as the architecture.
The training data
CUDA-Agent-Ops-6K is a synthetic dataset of 6,000 operators generated through a three-stage pipeline: seed operators extracted from PyTorch torch and HuggingFace transformers libraries, combinatorial synthesis stacking 1-5 operators sequentially, and execution-driven filtering requiring correct execution in both eager and compile modes, non-stochastic behavior, runtime between 1-100ms, and AST similarity below 0.9 to any KernelBench evaluation task.
The contamination screening is notable. The training set is entirely synthetic and explicitly checked against the evaluation benchmark using AST-based similarity analysis. This addresses a common critique of CUDA generation papers: CUDA-L1 and several derived works train directly on KernelBench subsets, creating data leakage concerns. CUDA Agent trains on separate data and assesses cleanly.
What's released
The paper and project page are public. The CUDA-Agent-Ops-6K dataset is stated as released on HuggingFace. The trained model weights don't appear to be publicly available - the base Seed 1.6 model is accessible through ByteDance's Volcano Engine API, but the RL-finetuned CUDA Agent checkpoint isn't released.
ByteDance-Seed separately maintains cudaLLM, a related but smaller project using Qwen3-8B with SFT+RL for CUDA kernel generation. CudaLLM includes training code, a reward model, PPO training loop, and a 8B model on HuggingFace under Apache 2.0.
Limitations
Level 3 performance drops to 94% pass rate and 1.52x speedup (from 100% and 2.80x at Level 2), suggesting complex fused operations with non-trivial control flow remain challenging. The system was trained and assessed on Hopper-generation GPUs - generalization to other architectures is unproven. The 6K training samples are modest relative to real-world kernel diversity. And no comparison against modern compiler stacks like TVM or Triton-based systems is included.
The broader limitation is compute: this requires RL training a 230B MoE model with 1024 batch size across 150 steps at 131K context. That's not something you reproduce on a consumer GPU cluster. The cudaLLM 8B variant is more accessible but posts substantially lower numbers.
What this means
CUDA Agent represents a genuine fundamental shift in AI-for-systems work. The key move is obvious in hindsight: if you want a model to generate fast code, reward it for creating fast code. Not correct code. Not code that looks like good code. Code that the profiler says is fast.
The 2.11x speedup over torch.compile matters because torch.compile is the default optimization path for most PyTorch users. If a RL-trained agent can consistently beat the compiler on the same hardware, it opens a path toward AI-produced kernels replacing hand-tuned operator libraries in production. The 40-point gap over Claude Opus 4.5 and Gemini 3 Pro on complex kernels suggests that general-purpose coding ability is necessary but insufficient for GPU optimization - you need domain-specific RL on hardware-grounded rewards.
The question now is whether ByteDance releases the trained model. The paper establishes the method. The cudaLLM 8B is a starting point. But the full CUDA Agent - the 230B MoE that actually posts the headline numbers - remains behind closed doors.
Sources:
