Cohere's Open-Source Transcribe Tops ASR Leaderboard
Cohere releases its first audio model - a 2B-parameter open-source ASR system beating Whisper Large v3 by 27% on the HuggingFace Open ASR Leaderboard.

Cohere spent five years building text models for enterprise customers. On March 26, the company shipped cohere-transcribe-03-2026, its first audio product, and it right away claimed the top spot on the HuggingFace Open ASR Leaderboard with a 5.42% average word error rate across eight standard English test sets.
Key Specs
| Spec | Value |
|---|---|
| Parameters | 2B |
| Architecture | Fast-Conformer encoder + lightweight decoder |
| English leaderboard | #1 - 5.42% avg WER |
| Multilingual leaderboard | #4 overall, #2 open |
| Languages | 14 |
| License | Apache 2.0 |
| Training data | 500,000 hours curated audio |
| API | Free via Cohere dashboard |
That 5.42% WER beats OpenAI's Whisper Large v3 (7.44%) by about 27%. It also edges past ElevenLabs Scribe v2 (5.83%) and NVIDIA Canary Qwen 2.5B (5.63%). The release marks Cohere's first move into audio as a product category - the company has built its business entirely around text until now.
Architecture
Encoder-heavy by design
Cohere Transcribe uses a Fast-Conformer encoder paired with a lightweight decoder. More than 90% of the model's 2 billion parameters sit in the encoder, which processes audio waveforms converted to log-Mel spectrograms. Audio is automatically resampled to 16 kHz if needed; stereo inputs get averaged to mono before processing.
This inverts the typical approach. Most speech models put more capacity in the decoder side. Cohere's team - Julian Mack, Ekagra Ranjan, Walter Beller-Morales, Bharat Venkitesh, and Pierre Richemond - pushed the bulk of the model's capacity into understanding speech, then handed off clean representations to a small, fast decoder that handles tokenization.
Training from scratch
The model was trained on 500,000 hours of curated audio-transcript pairs, not fine-tuned from Whisper or any other base. Training used supervised cross-entropy with background noise augmentation at signal-to-noise ratios between 0 and 30 dB. The team also added synthetic data after error analysis rounds to patch specific failure modes.
The tokenizer is a 16,000-token multilingual BPE tokenizer with byte fallback, trained on in-distribution data rather than adapted from a general-purpose LLM tokenizer.
Benchmark Results
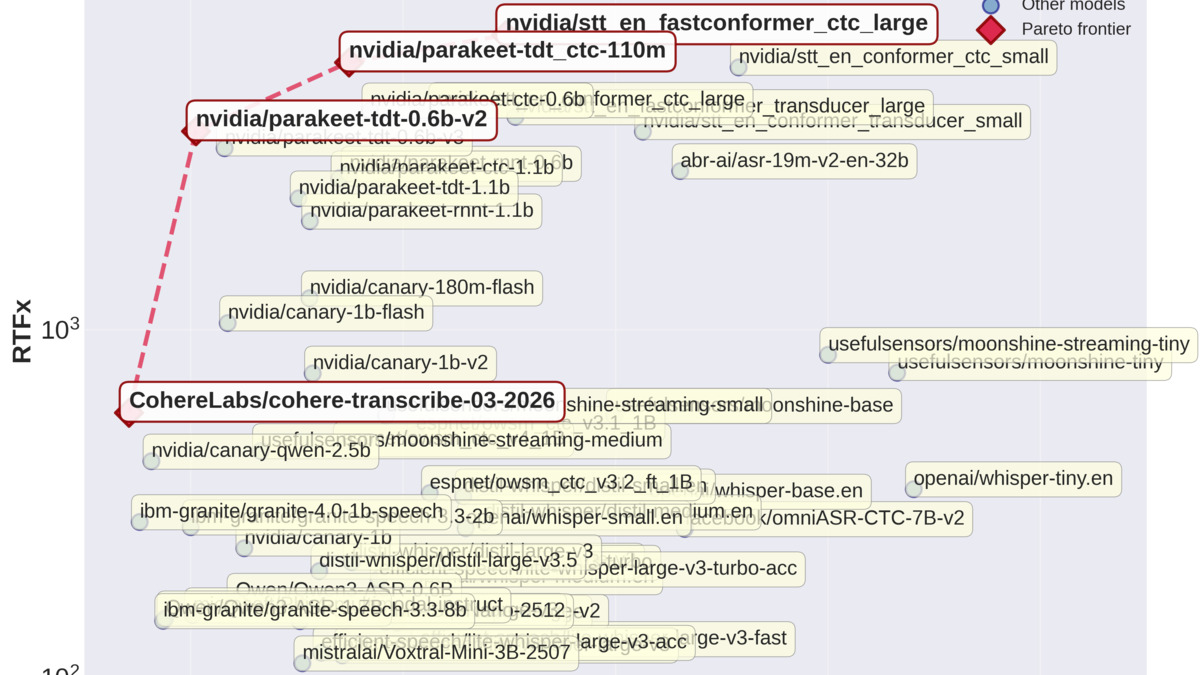 The HuggingFace Open ASR Leaderboard scatter plot showing real-time factor vs. word error rate. Cohere Transcribe sits at the top-left corner - highest accuracy and competitive throughput.
Source: github.com/huggingface/open_asr_leaderboard
The HuggingFace Open ASR Leaderboard scatter plot showing real-time factor vs. word error rate. Cohere Transcribe sits at the top-left corner - highest accuracy and competitive throughput.
Source: github.com/huggingface/open_asr_leaderboard
The eight test sets cover many domains: AMI (meeting transcription), Earnings22 (financial calls), GigaSpeech (mixed audio), LibriSpeech Clean and Other, SPGI (financial), Tedlium (lectures), and VoxPopuli (parliamentary speech).
| Model | Avg WER | AMI | Earn22 | GigaSpeech | LS Clean | LS Other | Tedlium |
|---|---|---|---|---|---|---|---|
| Cohere Transcribe | 5.42 | 8.15 | 10.84 | 9.33 | 1.25 | 2.37 | 2.49 |
| Zoom Scribe v1 | 5.47 | 10.03 | 9.53 | 9.61 | 1.63 | 2.81 | 3.22 |
| IBM Granite 4.0 1B Speech | 5.52 | 8.44 | 8.48 | 10.14 | 1.42 | 2.85 | 3.10 |
| NVIDIA Canary Qwen 2.5B | 5.63 | 10.19 | 10.45 | 9.43 | 1.61 | 3.10 | 2.71 |
| ElevenLabs Scribe v2 | 5.83 | 11.86 | 9.43 | 9.11 | 1.54 | 2.83 | 2.37 |
| OpenAI Whisper Large v3 | 7.44 | 15.95 | 11.29 | 10.02 | 2.01 | 3.91 | 3.86 |
| Mistral Voxtral Mini 4B | 7.68 | 17.07 | 11.84 | 10.38 | 2.08 | 5.52 | 3.79 |
The top of the leaderboard is tight. IBM Granite 4.0 1B Speech, which claims the accuracy crown on the Earnings22 financial call set (8.48%), comes in third overall at 5.52% - only 0.1 points behind Cohere. Zoom Scribe v1 sits at 5.47%. No model leads cleanly across all eight domains.
On human preference evaluations, Cohere Transcribe wins 64% of head-to-head comparisons against Whisper Large v3 and 67% against NVIDIA Canary. Against IBM Granite 4.0 1B Speech, the win rate jumps to 78% - which suggests subjective transcription quality gaps that raw WER numbers don't fully capture.
Throughput
Cohere claims 3x higher offline throughput than similarly sized dedicated ASR models. The model supports variable-length audio natively, using packed representations to minimize padding overhead in batched inference. A vLLM integration is already live - a pull request merging support directly into the vLLM codebase - and Cohere says it adds up to 2x additional throughput on top of the baseline.
How To Run It
The simplest path is HuggingFace Transformers. The model requires transformers>=5.4.0 - versions 5.0 and 5.1 have a weight-loading bug that breaks it:
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor
import torch, soundfile as sf
model_id = "CohereLabs/cohere-transcribe-03-2026"
processor = AutoProcessor.from_pretrained(model_id, trust_remote_code=True)
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True
)
audio, sr = sf.read("audio.wav")
inputs = processor(audio, sampling_rate=sr, return_tensors="pt").to(model.device)
output = model.generate(**inputs, language="en")
print(processor.batch_decode(output, skip_special_tokens=True)[0])
For production throughput with vLLM:
vllm serve CohereLabs/cohere-transcribe-03-2026 --trust-remote-code
The model also runs on Apple Silicon via mlx-audio and in the browser via transformers.js with WebGPU. A Rust client library (cohere_transcribe_rs) is available for lower-level integrations.
For teams that don't want to self-host, the model is available via Cohere's API on a free tier and through Cohere's Model Vault for private cloud deployment at an hourly rate.
Multilingual Coverage
Fourteen languages: English, French, German, Italian, Spanish, Portuguese, Greek, Dutch, Polish, Arabic, Chinese (Mandarin), Japanese, Korean, and Vietnamese. On the multilingual ASR leaderboard, Cohere Transcribe ranks 4th overall and 2nd among open models.
 Enterprise transcription use cases - call centers, earnings call processing, meeting notes - are Cohere's primary target market for the model.
Source: unsplash.com
Enterprise transcription use cases - call centers, earnings call processing, meeting notes - are Cohere's primary target market for the model.
Source: unsplash.com
Fourteen languages covers the major enterprise markets well. For organizations working with speakers from outside that set, Whisper Large v3 still has a much larger language coverage at 99 languages. Cohere's model isn't a replacement for Whisper in multilingual workflows at scale.
One firm limitation: language detection isn't automatic. You have to specify the language at inference time. That rules out the model for workflows where audio language is unknown or mixed.
What To Watch
There are four gaps worth tracking before committing to this model in production:
No timestamps or diarization. The model outputs a flat transcript. Most production transcription use cases - call center analytics, legal transcription, meeting tools - need speaker labels and word-level timestamps. These are on Cohere's roadmap but not shipped yet.
Code-switching is unstable. If speakers switch between languages mid-sentence, transcription quality degrades. This isn't unusual for ASR models but it matters for multilingual enterprise deployments.
Non-speech sounds get transcribed. Background noise, music, and ambient sound tend to appear in the output. Cohere recommends running a voice activity detection (VAD) model as a preprocessing step. That adds complexity to any production pipeline.
Domain generalization is unproven. The leaderboard results cover clean read speech (LibriSpeech) and broadcast audio. Medical, legal, and highly accented speech aren't tested publicly. High WER on general benchmarks doesn't guarantee that it holds on specialized vocabularies.
You can follow how this model compares to others on our AI Voice and Speech Leaderboard as more evaluations come in. For developers comparing this to Mistral's Voxtral, note the use-case difference: Voxtral is a multimodal voice-language model while Cohere Transcribe is a dedicated speech-to-text system optimized purely for transcription accuracy.
The Apache 2.0 license removes any commercial usage friction. For enterprise teams currently paying per-minute to ElevenLabs Scribe or OpenAI's transcription API, a self-hosted deployment on a single consumer GPU changes the unit economics. Whether those accuracy numbers hold on domain-specific audio is the test Cohere hasn't published results for yet.
Sources:

