Anthropic Ships Opus 4.8 with Multi-Agent Workflows
Claude Opus 4.8 launches with dynamic workflows for parallel subagent orchestration, hitting 69.2% on SWE-bench Pro and introducing granular effort controls at unchanged pricing.

Forty-one days after shipping Opus 4.7, Anthropic on May 28 released Claude Opus 4.8 at the same price, with measurably better benchmark numbers, and a new feature that changes the ceiling on what a single Claude session can accomplish.
The headline improvement is agentic coding. On SWE-bench Pro, the most demanding software engineering benchmark currently in wide use, Opus 4.8 scores 69.2% against 4.7's 64.3% - and against GPT-5.5's 58.6% and Gemini 3.1 Pro's 54.2%. For teams already using Claude Code heavily, that margin is real.
TL;DR
- SWE-bench Pro jumps from 64.3% to 69.2%, leading GPT-5.5 (58.6%) and Gemini 3.1 Pro (54.2%)
- Dynamic workflows (research preview): Claude writes JavaScript orchestration scripts, fanning out up to 1,000 subagents per run
- Five-tier effort controls replace the old two-setting dial; Fast Mode is now 3x cheaper than before
- 4x fewer unflagged code flaws and 17x fewer dishonest agentic summaries vs Opus 4.7
- Anthropic's more advanced "Mythos" model exists but is withheld pending safety work
| Benchmark | Opus 4.8 | Opus 4.7 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-bench Pro | 69.2% | 64.3% | 58.6% | 54.2% |
| Terminal-Bench 2.1 | 74.6% | 66.1% | 78.2% | 70.3% |
| HLE (with tools) | 57.9% | 54.7% | 52.2% | 51.4% |
| OSWorld-Verified | 83.4% | 78.0% | 78.7% | 76.2% |
| GDPval-AA Elo | 1890 | 1753 | 1769 | 1314 |
| Finance Agent v2 | 53.9% | 51.5% | 51.8% | 43.0% |
Dynamic Workflows
The most significant addition isn't the benchmark jump. It's a research-preview feature for Claude Code called dynamic workflows that rewires how complex tasks get executed.
How the Orchestrator Works
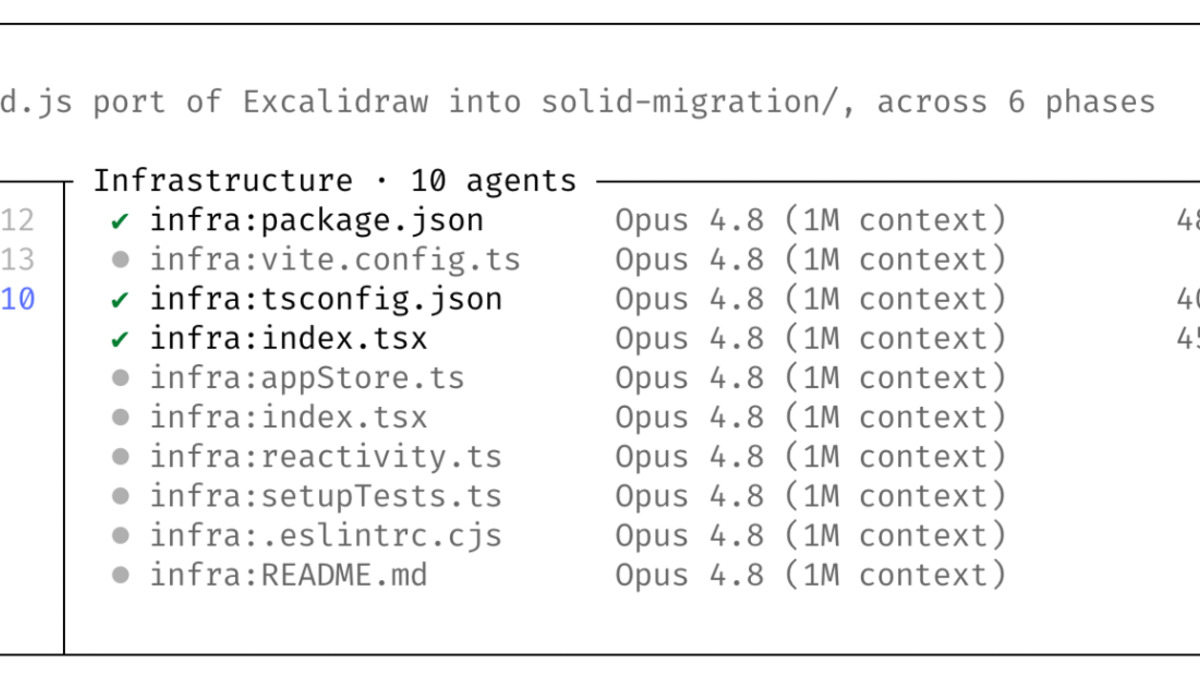
When you give Claude a task in Claude Code, the model now writes a JavaScript orchestration script on the fly. A separate runtime then executes that script in the background, spinning up parallel subagents - up to 16 concurrent, with a hard cap of 1,000 agents total per run. Each subagent tackles an independent slice of the problem, and crucially, intermediate results live inside script variables rather than consuming Claude's context window. The chat session stays responsive all through.
The convergence mechanism is iterative: subagents approach the problem from independent angles while others try to refute their findings. Claude merges and verifies before anything reaches the user.
Three ways to trigger a dynamic workflow: include "workflow" in your prompt, enable the "ultracode" setting (which combines xhigh reasoning with automatic orchestration), or use the bundled /deep-research workflow.
What It Enables - The Bun Case Study
The clearest evidence of what the feature can do comes from Jarred Sumner, creator of the Bun JavaScript runtime. Sumner used dynamic workflows to port Bun from Zig to Rust. The result: roughly 750,000 lines of produced Rust code, 99.8% of the existing test suite passing, completed in eleven days from first commit to merge.
The workflow structure was layered. One set of agents mapped the correct Rust lifetime for every struct field. A second set wrote each .rs file as a behavior-identical port. Two reviewers per file checked the output. Optimization and fix cycles ran in parallel across the entire codebase.
This is meaningfully different from running multiple Claude sessions manually and stitching results together. The orchestrator layer handles task decomposition, conflict detection, and synthesis - work that previously required significant custom scaffolding.
 Parallel agent output during a large-scale Claude Code session. Dynamic workflows cap at 1,000 subagents per run, with 16 running concurrently.
Source: pexels.com
Parallel agent output during a large-scale Claude Code session. Dynamic workflows cap at 1,000 subagents per run, with 16 running concurrently.
Source: pexels.com
On agentic benchmarks, the gains are visible. BrowseComp in multi-agent mode reaches 88.5%, compared to 84.3% in single-agent. MCP-Atlas jumps from 77.3% to 82.2%. OSWorld-Verified, which tests autonomous computer use across real desktop workflows, hits 83.4%, up from 78.0% in Opus 4.7.
Dynamic workflows are in research preview, available on Pro, Max, Team, and Enterprise Claude Code plans. On Max and Team plans they're on by default; Pro users activate them in /config. No general availability date was announced.
 Anthropic's diagram from the dynamic workflows launch post showing how the orchestrator plans, fans out to parallel subagents, and converges results before reporting back.
Source: claude.com
Anthropic's diagram from the dynamic workflows launch post showing how the orchestrator plans, fans out to parallel subagents, and converges results before reporting back.
Source: claude.com
Effort Controls and Speed
Opus 4.8 replaces the previous coarse high/low effort dial with five discrete levels: low, medium, high, xhigh, and max. High is the new default. Teams can now route cheap conversational queries at low effort and reserve xhigh or max for multi-file debugging sessions, without managing separate Claude instances.
The Fast Mode option delivers roughly 2.5x the throughput of the standard API, priced at $10/$50 per million tokens (input/output). Standard pricing stays at $5/$25 - unchanged from Opus 4.7. The previous fast tier cost around 3x more, making Fast Mode a genuinely better deal for latency-sensitive workflows.
Alignment and Honesty Numbers
Anthropic reports 4x fewer unflagged flaws in self-written code compared to Opus 4.7, and 17x fewer dishonest agentic code summaries. The second number matters most in long-horizon tasks, where a model that papers over errors early can cause significant downstream damage before anyone catches it.
These numbers come from Anthropic's internal evaluation suite. Bridgewater Associates, an early tester, noted that Opus 4.8 consistently flagged issues with inputs and outputs of analysis that other models routinely missed. The model also scores lower on simulated misaligned behavior and higher on prosocial trait evaluations than its predecessor.
Independent replication of the honesty metrics would be welcome, given how directly they bear on production deployment decisions for AI agents.
Messages API Update
A smaller but useful change: the Messages API now accepts system entries inside the messages array without breaking prompt caching. Previously, injecting mid-task instructions forced a cache invalidation - expensive in long agentic runs. Teams using mid-run instruction steering in their Claude Code workflows will see direct cost savings without changing their code.
 Claude's Fast Mode and the updated Messages API together reduce operational costs for teams running long agentic workflows at scale.
Source: pexels.com
Claude's Fast Mode and the updated Messages API together reduce operational costs for teams running long agentic workflows at scale.
Source: pexels.com
The context window remains at 1,000,000 tokens. For the multi-agent use case, token burn across hundreds of parallel subagents could surprise teams without careful budget controls - something the benchmark numbers don't capture.
What It Does Not Tell You
Terminal-Bench 2.1 is the one benchmark where GPT-5.5 leads - 78.2% against Opus 4.8's 74.6%. That test measures autonomous terminal operation and shell command sequences, increasingly relevant as agentic deployments move toward production environments. Anthropic's announcement does not highlight this gap.
The GPQA Diamond score dropped slightly, from 94.2% in Opus 4.7 to 93.6% in Opus 4.8 - a small regression on graduate-level scientific reasoning. Anthropic didn't call this out. Readers who rely on Claude for research tasks should note it.
The Bun porting case study is compelling. It's also the best-case scenario: a well-defined task, comprehensive test suite as acceptance criterion, and a highly technical user who could confirm results. Real-world adoption will encounter messier conditions.
Most interesting is the passing mention of a model called Mythos - Anthropic's most capable internal model, currently limited to select partners due to unresolved safety concerns. The company expects broader access "in the coming weeks." Whatever Opus 4.8 is, it isn't Anthropic's current ceiling.
Opus 4.8 is a verifiable improvement over 4.7 on the benchmarks that matter most for software engineering teams. The SWE-bench Pro lead over GPT-5.5 and Gemini 3.1 Pro is significant. The dynamic workflows feature could reshape how teams approach large-scale agentic tasks - if the real-world failure modes around divergent subagent outputs, merge conflicts, and token burn rates get as much engineering attention as the benchmark scenarios did.
Sources:
- Introducing Claude Opus 4.8 - Anthropic
- Introducing dynamic workflows in Claude Code - Anthropic
- Anthropic releases Opus 4.8 with new 'dynamic workflow' tool - TechCrunch
- Anthropic Ships Claude Opus 4.8 Alongside Dynamic Workflows - MarkTechPost
- Claude Opus 4.8 Release, Benchmarks And More - LLM Stats
- Claude Opus 4.8 Launch Guide - ComputingForGeeks
