Claude Opus 4.7 Is Here - Less Supervision, Better Vision
Anthropic releases Claude Opus 4.7 with 3x higher resolution vision, a new xhigh effort level, task budgets for cost control, /ultrareview in Claude Code, and cyber safeguards that automatically block high-risk requests.
TL;DR
- Claude Opus 4.7 is live today across claude.ai, the API ($5/$25 per M tokens - same as 4.6), Bedrock, Vertex AI, and Foundry
- 3x higher resolution vision (2,576px long edge, ~3.75 megapixels) produces better interfaces, slides, and document understanding
- New xhigh effort level between high and max gives finer reasoning-latency control; now the default in Claude Code
- Task budgets (beta) let Claude manage token spend across long-running tasks
- /ultrareview in Claude Code runs a dedicated review session that flags what a careful human reviewer would catch
- Cyber safeguards automatically detect and block high-risk cybersecurity requests - the Mythos-class guardrails we were told to expect
The model Anthropic warned was coming during the Glasswing announcement shipped today. Claude Opus 4.7 is the production release that carries the cybersecurity safeguards Anthropic built before bringing Mythos-level capabilities to general availability.
It's available now on claude.ai, the Claude Platform API, Amazon Bedrock, Google Cloud Vertex AI, and Microsoft Foundry.
What's actually better
Vision: 3x the pixels
Opus 4.7 accepts images up to 2,576 pixels on the long edge (~3.75 megapixels) - more than three times the resolution of previous Claude models. This matters for anyone working with diagrams, code screenshots, design mockups, or document analysis. Higher resolution means the model can read smaller text, identify finer details in charts, and produce better-quality interfaces and presentations.
Long-running task reliability
The headline claim: "You can hand off your hardest work with less supervision." Opus 4.7 is designed to handle complex, multi-step tasks with more consistency than 4.6. It verifies its own outputs before reporting back and follows instructions more precisely.
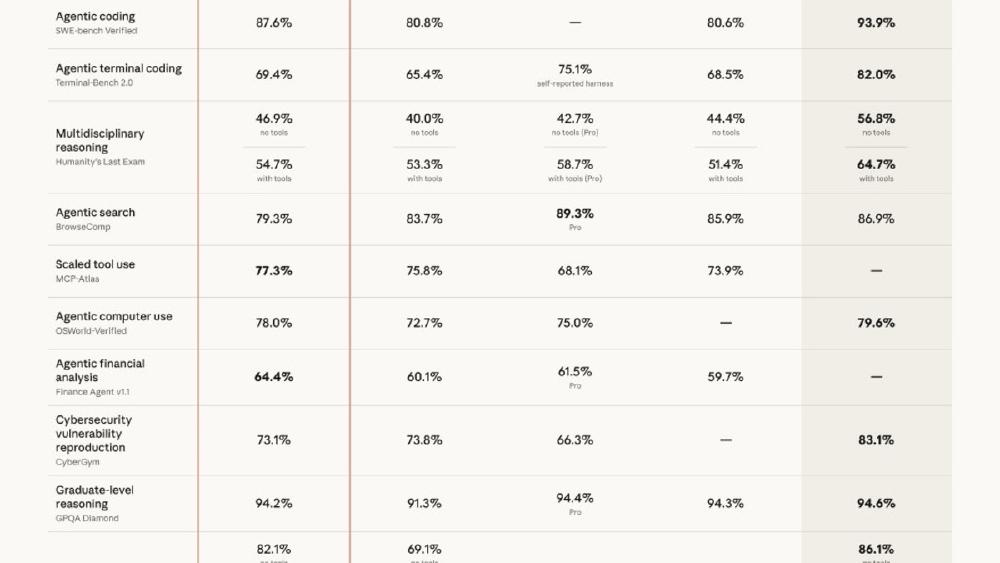
The benchmark evidence:
| Benchmark | Opus 4.7 | Opus 4.6 | Improvement |
|---|---|---|---|
| GitHub AI 93-task coding | - | - | +13% |
| CursorBench (Cursor) | 70% | 58% | +12pts |
| Rakuten-SWE-Bench | - | - | 3x more tasks resolved |
| Finance Agent (General) | 0.813 | 0.767 | +6% |
| BigLaw Bench (Harvey) | 90.9% | - | - |
The CursorBench and Rakuten numbers are third-party evaluations (from Cursor and Rakuten respectively), which carries more weight than self-reported benchmarks.
Effort levels: xhigh
A new xhigh effort level sits between high and max, giving developers finer control over the reasoning-latency tradeoff. Claude Code now defaults to xhigh for all plans.
The effort hierarchy: low -> medium -> high -> xhigh -> max
For API users, this means you can get most of max's reasoning depth at lower latency and cost. For Claude Code users, the default bump from high to xhigh means better results out of the box.
Task budgets (beta)
A new API feature that lets you set token spend limits across long-running tasks. Claude prioritizes work within the budget and manages cost allocation. This directly addresses the quota exhaustion problem that Max users have been documenting - giving Claude awareness of resource constraints rather than burning through tokens blindly.
Claude Code changes
/ultrareview
A new command that runs a dedicated review session: Claude reads through your changes and flags what a careful reviewer would catch. Three free ultrareviews per session for Pro and Max users.
This is Anthropic's answer to the "Claude wrote the code but who reviews it" problem. Instead of copying diffs into a separate chat, /ultrareview creates a focused review context that evaluates the work the current session produced.
Auto mode for Max
Auto mode - where Claude makes tool decisions without asking for permission on every step - is now extended to all Max users. This means longer tasks run with fewer interruptions. Previously, Claude paused for confirmation on file writes, command execution, and other actions. Auto mode lets it work through multi-step tasks continuously.
Combined with the desktop redesign for parallel sessions shipped yesterday, Max users can now run multiple autonomous Claude Code sessions simultaneously from the desktop app.
The cyber safeguards
This is the piece that Glasswing promised. Opus 4.7 includes built-in safeguards that "automatically detect and block high-risk cybersecurity requests." This is the production implementation of the safety measures Anthropic said they'd build before bringing Mythos-class capabilities to broader release.
A separate Cyber Verification Program lets legitimate security professionals apply for access that bypasses these restrictions for authorized vulnerability research, penetration testing, and red-teaming work.
The safety report notes Opus 4.7 is "better on honesty and prompt injection resistance" while being "modestly weaker on harm-reduction advice for controlled substances." Anthropic characterizes it as "largely well-aligned and trustworthy, though not fully ideal in its behavior."
Pricing and tokenizer
Same pricing as Opus 4.6: $5 input / $25 output per million tokens.
One important change: Opus 4.7 uses an updated tokenizer that processes text more efficiently. The same input maps to 1.0-1.35x more tokens depending on content type. This means your token counts will be slightly higher for the same text, but Anthropic says the net effect is favorable on coding evaluations despite the higher token usage.
Model ID: claude-opus-4-7
Migration note
Anthropic warns that Opus 4.7's improved instruction following "may produce unexpected results with prompts written for earlier models." If you have carefully tuned prompts for 4.6, test them before switching. The model is more literal, which means ambiguous instructions that 4.6 interpreted charitably may be interpreted differently.
Sources:
Last updated
