Claude Opus 4.8 Leads SWE-Bench Pro, Adds Parallel Agents
Anthropic's Claude Opus 4.8 scores 69.2% on SWE-bench Pro and ships hundreds of parallel subagents in Claude Code, with pricing unchanged at $5 per million input tokens.

Claude Opus 4.8 scores 4.9 percentage points higher than its predecessor on SWE-bench Pro, landing at 69.2% and sitting second on the public leaderboard behind the still-unreleased Mythos Preview at 77.8%. That gap matters because SWE-bench Verified - the easier variant - is approaching saturation at 88.6%. Pro is where real headroom remains, and Anthropic is closing it.
TL;DR
- SWE-bench Pro: 69.2% (up from 64.3% on Opus 4.7); second only to unreleased Claude Mythos Preview (77.8%)
- Honesty training cuts silent code-flaw acceptance by 4x; model now catches its own bugs instead of declaring success early
- Dynamic Workflows ships in Claude Code research preview - runs hundreds of parallel subagents per session for large codebase migrations
- Pricing unchanged: $5/$25 per million tokens; fast mode is now $10/$50, three times cheaper than before
- Context window: 1 million tokens; model ID
claude-opus-4-8
Benchmark Comparison
The numbers across six benchmarks paint a consistent picture: Opus 4.8 leads on knowledge work and coding, trails only GPT-5.5 on terminal-based tasks, and loses to a much smaller Gemini model on finance-specific evals.
| Benchmark | Opus 4.8 | Opus 4.7 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-bench Pro | 69.2% | 64.3% | 58.6% | 54.2% |
| SWE-bench Verified | 88.6% | 87.6% | - | - |
| Terminal-Bench 2.1 | 74.6% | 66.1% | 78.2% | - |
| Humanity's Last Exam | 57.9% | 54.7% | 52.2% | 51.4% |
| GDPval-AA | 1,890 | 1,753 | 1,769 | 1,314 |
| Finance Agent v2 | 53.9% | - | - | 57.9% (3.5 Flash) |
Artificial Analysis ranked Opus 4.8 first on their Intelligence Index with a score of 61.4, one point above GPT-5.5. One detail buried in their analysis: the model reached that position with 15% fewer turns per task and 35% fewer output tokens than Opus 4.7. That efficiency gain doesn't show up on any headline leaderboard, but it directly affects real-world API costs for long agentic runs.
The Ablation: What Actually Moved
Anthropic didn't publish a formal ablation study with this release. But the change log and benchmark deltas are specific enough to identify the contributing factors.
| Change | Evidence | Estimated Impact |
|---|---|---|
| Honesty training | 4x reduction in silent code-flaw acceptance | SWE-bench Pro +4.9pp, Super-Agent clean sweep |
| Agentic tool-call cleanup | Resolved comment-verbosity feedback from Cognition/Devin | Fewer wasted turns per task |
| Multi-step reasoning | HLE: 54.7% to 57.9% | +3.2pp on Humanity's Last Exam |
| Knowledge-work tuning | GDPval-AA: 1,753 to 1,890 | +137 points, 121-point lead on next competitor |
| Fast mode efficiency | 2.5x speed, 3x cost reduction | No accuracy change reported |
Honesty Training
Anthropic describes honesty improvements as the single most significant change in Opus 4.8. The model is around four times less likely than Opus 4.7 to skip past a flaw in code it created and declare the task complete. In benchmark terms, that's the difference between an agent that finishes the job and one that finishes the prompt.
The practical upshot shows on the Legal Agent Benchmark: Opus 4.8 is the first model to break 10% on the all-pass standard - a threshold that requires completing every sub-task in a multi-step legal workflow without any shortcuts. It's also the only model to complete every case end-to-end on the Super-Agent benchmark at equivalent cost to GPT-5.5.
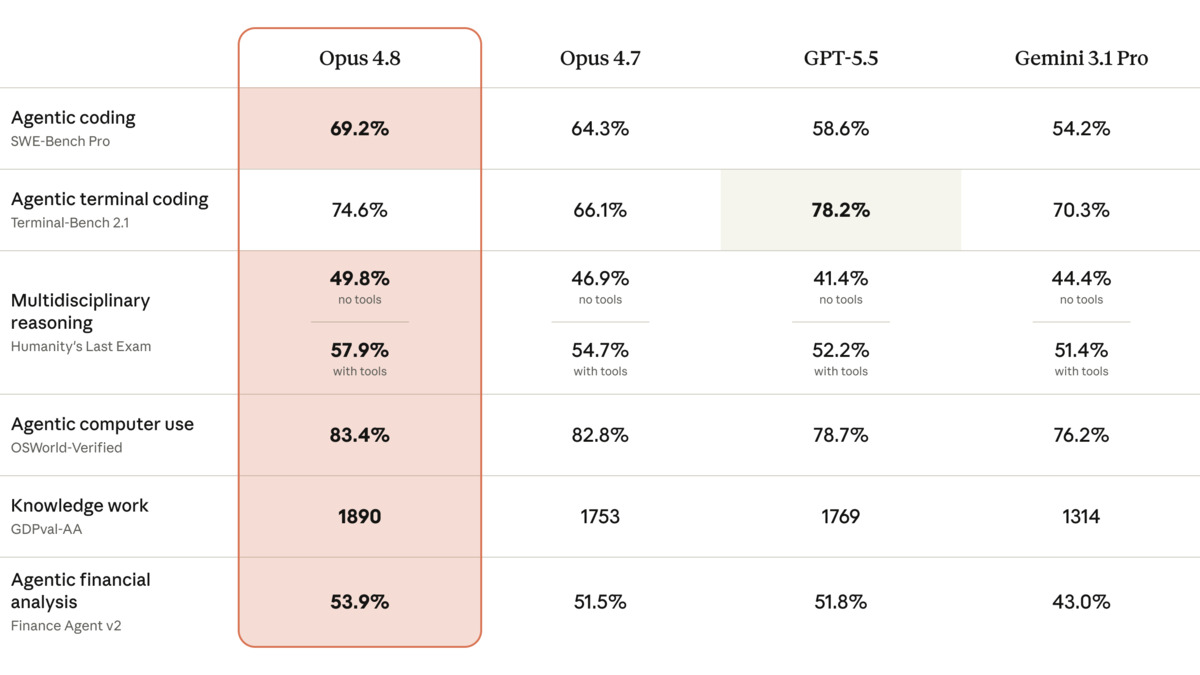 Opus 4.8 leads GPT-5.5 on most benchmarks but trails on Terminal-Bench 2.1, where GPT-5.5 scores 78.2% vs 74.6%.
Source: anthropic.com
Opus 4.8 leads GPT-5.5 on most benchmarks but trails on Terminal-Bench 2.1, where GPT-5.5 scores 78.2% vs 74.6%.
Source: anthropic.com
Agentic Reliability
The tool-call cleanup addressed specific complaints from Cognition and Devin, two of the more demanding agentic coding environments. The model was generating verbose comments mid-execution that broke downstream parsing and inflated output token counts. The fix doesn't register as a benchmark category but it's the kind of friction that makes production deployments unreliable.
Multi-Step Reasoning and Knowledge Work
Humanity's Last Exam with tools went from 54.7% to 57.9%. GDPval-AA, which measures economic value across professional knowledge tasks, jumped 137 points. The GDPval-AA gap between Opus 4.8 and Gemini 3.1 Pro is now 576 points - the largest performance differential in that benchmark across any two published models.
Dynamic Workflows: Architecture of Parallel Agents
The most architecturally interesting addition to Opus 4.8 is Dynamic Workflows in Claude Code, currently in research preview for Enterprise, Team, and Max plan users.
The feature adds a three-layer orchestration model to Claude Code's parallel session infrastructure. At the top, an orchestrator agent - usually Opus 4.8 itself - handles task decomposition and planning. Below it, sub-agents (which can be Haiku, Sonnet, or Opus depending on task complexity) execute independent subtasks in parallel. Each sub-agent has its own tool access layer.
In practice, that means a single Claude Code session can now carry out a codebase migration across hundreds of thousands of lines from kickoff through merge, with the existing test suite as its acceptance bar. The orchestrator decomposes the migration, spawns parallel workers for independent modules, and verifies each before assembling the result.
 Dynamic Workflows in Claude Code allow hundreds of parallel subagents in a single session, with the orchestrator verifying outputs before reporting back.
Source: anthropic.com
Dynamic Workflows in Claude Code allow hundreds of parallel subagents in a single session, with the orchestrator verifying outputs before reporting back.
Source: anthropic.com
The concurrency limit is about 20 agents per batch before rate limits apply, so teams handling "dozens to a few hundred parallel agents per workflow run" is the realistic ceiling for most API tiers. Cost control matters here: Anthropic recommends using Haiku for simple classification steps, Sonnet for moderate analysis, and Opus sparingly at the orchestrator level.
The new Messages API also accepts system entries mid-array, which lets orchestrators update agent instructions during a run without resetting the prompt cache. For long sessions, that's a meaningful improvement over the previous approach of appending instruction updates to the user turn.
Where It Still Fails
Two benchmarks keep Opus 4.8 off the "best model for everything" podium.
On Terminal-Bench 2.1, GPT-5.5 scores 78.2% to Opus 4.8's 74.6%. Terminal-Bench tests long-horizon command-line tasks that require maintaining context across shell sessions - something that appears to favor GPT-5.5's architecture.
On Finance Agent v2, Gemini 3.5 Flash - a model in a completely different tier by size and price - scores 57.9% vs Opus 4.8's 53.9%. Anthropic hasn't explained why, but specialized financial tool-calling may favor different training-data distributions than Opus 4.8 was optimized for.
Hallucination metrics from Artificial Analysis put Opus 4.8 at 46.6% accuracy with 35.9% hallucination rate, which is better than GPT-5.5 and Gemini 3.1 Pro but still not close to a level where long-running agents can go unsupervised on high-stakes tasks.
Opus 4.8 is a genuine step forward on the benchmarks that matter most for software engineering. The dynamic workflows feature changes what Claude Code can tackle - not by making individual agents smarter, but by letting them work in parallel at a scale that wasn't practical before. The more useful measure of the release will come from whether the honesty improvements hold up in production deployments, where silent failures are harder to catch than in controlled eval settings. Anthropic's commitment to maintaining the same $5/$25 pricing while shipping these gains narrows the cost argument that has kept GPT-5.5 competitive on certain tasks.
Sources:
Last updated
