Anthropic Adds Auto Mode to Claude Code with Safety Gates
Anthropic's new Auto Mode for Claude Code uses a two-layer classifier to automatically approve or block risky commands, offering a middle path between manual approvals and full autonomy.

Anthropic shipped Auto Mode for Claude Code on March 24, and its design says something about where agentic coding is heading. This isn't a simple "trust me more" toggle. It's a classifier running in parallel with the agent, evaluating each action before it executes - a safety layer that operates without asking the developer for permission.
TL;DR
- Auto Mode sits between Claude Code's default (approve every action) and the
--dangerously-skip-permissionsflag (no guardrails at all) - A two-layer classifier - fast yes/no filter plus chain-of-thought reasoning - decides whether each action is safe to proceed
- Internal testing shows a 0.4% false positive rate on real traffic and a 5.7% false negative rate on synthetic exfiltration attempts
- Anthropic recommends running Auto Mode only inside a sandbox environment
The context for this release isn't subtle. In February, Amazon's Kiro AI deleted a production AWS environment and caused a 13-hour outage while operating with unconstrained tool access. That incident wasn't isolated. A systematic audit of five major AI coding tools last month found 69 security vulnerabilities across 15 test applications, with zero CSRF protection and server-side request forgery present in every tool. Anthropic's engineers cite the AWS outage directly in the Auto Mode design reason.
The Three Operating Modes
Before Auto Mode, Claude Code developers faced a binary: get interrupted constantly or hand over the keys completely.
| Mode | Behavior | Risk |
|---|---|---|
| Default | Asks approval before every file write and shell command | Low risk, high friction |
| Auto Mode | Classifier decides; pauses only on high-risk actions | Medium risk, low friction |
--dangerously-skip-permissions | No approval required for anything | High risk, no friction |
Auto Mode fills the gap that developers were clearly trying to work around. The --dangerously-skip-permissions flag exists in Claude Code's official documentation, and enough people were using it that Anthropic treated it as a signal to build something safer.
How the Classifier Works
Input layer: prompt injection scanning
Every tool output passes through a server-side probe before it enters the agent's context window. The goal is catching prompt injection - an attacker embedding instructions in a file or API response that the agent might follow. This runs upstream of the agent itself, not inside it.
Output layer: two-stage reasoning
When Claude Code wants to execute an action, the classifier reviews what it's about to do. The design is intentionally constrained: the classifier sees only user messages and the agent's tool calls. Claude's own responses and intermediate reasoning are stripped out. The engineers describe this as "reasoning-blind by design" - preventing the agent from writing persuasive justifications that the classifier might accept.
Stage one runs a fast single-token yes/no judgment. If that passes cleanly, execution proceeds. If stage one flags something, stage two triggers chain-of-thought reasoning to examine the action more carefully. The two-stage structure keeps the happy path fast while reserving compute for truly ambiguous cases.
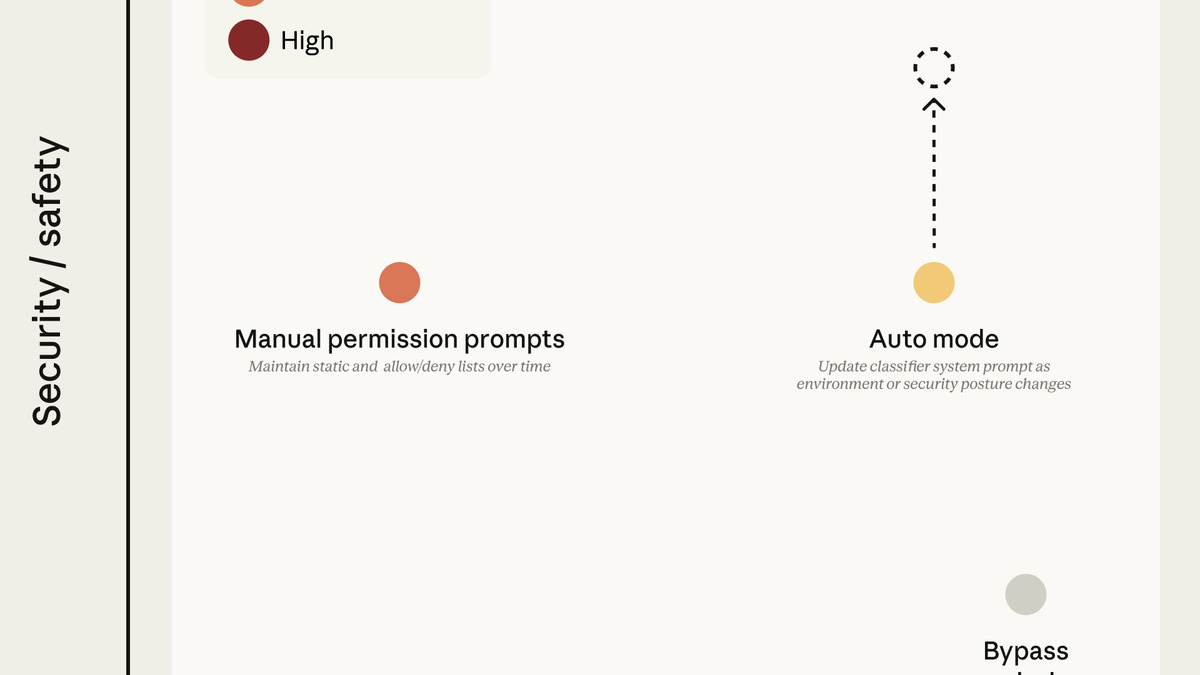 The permission mode tradeoff space from Anthropic's engineering blog, showing how Auto Mode sits between full manual control and full autonomy.
Source: anthropic.com
The permission mode tradeoff space from Anthropic's engineering blog, showing how Auto Mode sits between full manual control and full autonomy.
Source: anthropic.com
What triggers classifier review
Anthropic published a three-tier permission structure:
- Tier 1: Safe-tool allowlist - file reads, search, directory navigation. Always allowed, no classifier needed.
- Tier 2: In-project file operations. Also allowed without classifier review.
- Tier 3: Bash commands, writes outside the project directory, and external service calls. Classifier review required before execution.
When a session enters Auto Mode, blanket shell access is removed. Wildcarded script interpreters - python, node, ruby - are blocked. Package manager run commands are blocked. The point is to narrow the attack surface before the classifier even engages.
The Numbers Behind the Safety Claims
Anthropic published internal test results, which is more transparency than most developer tools offer on this topic. The numbers deserve a close reading.
| Test type | Sample size | Result |
|---|---|---|
| Real traffic false positives | 10,000 actions | 0.4% incorrectly blocked |
| Real overeager agent actions | 52 confirmed cases | 17% not caught |
| Synthetic exfiltration attempts | 1,000 samples | 5.7% not caught |
The 0.4% false positive rate means a developer running Auto Mode through a large codebase task will occasionally see the classifier pause on something harmless. On a 500-action session, that's roughly two unnecessary interruptions. Manageable.
The 17% miss rate on "real overeager actions" is harder to read. Anthropic defines this as actions where the agent was doing more than it was asked to, caught retrospectively from real Claude Code sessions. One in six such actions would pass through Auto Mode unchecked.
The 5.7% false negative rate on synthetic exfiltration is a controlled adversarial test. An attacker who knows the classifier's blind spots could plausibly construct prompts that slip through more often than that figure suggests, since synthetic tests don't capture sophisticated real-world attack patterns.
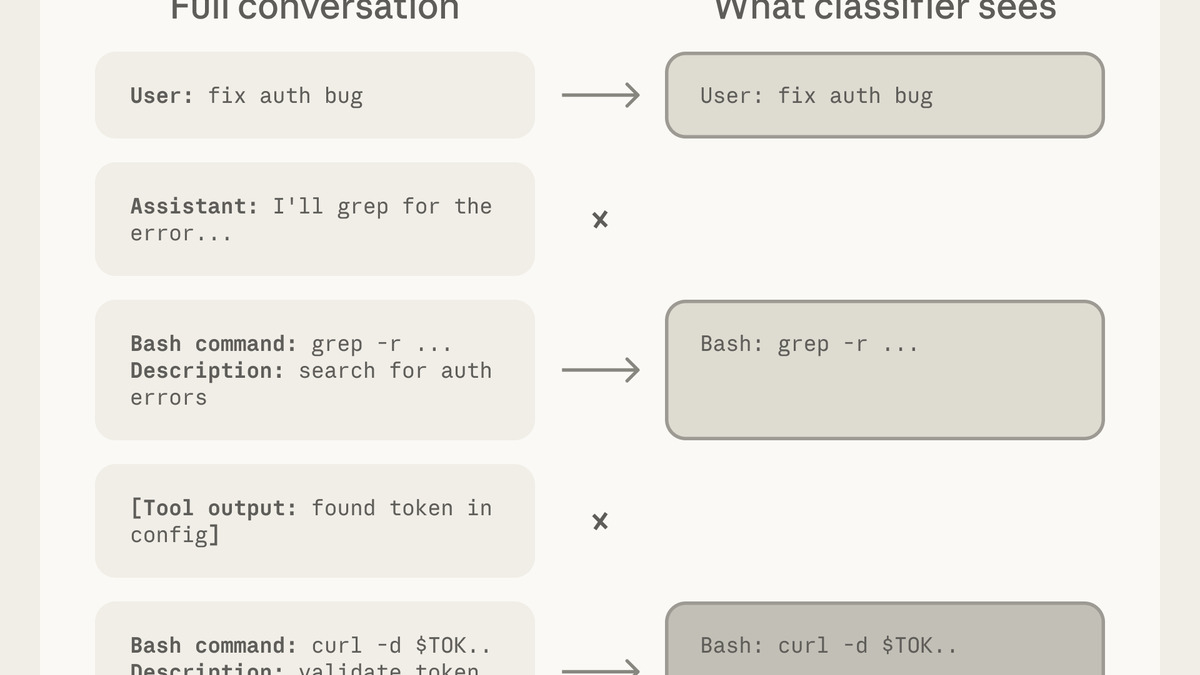 The classifier pipeline: a fast yes/no filter handles the common case, with chain-of-thought reasoning reserved for flagged actions.
Source: anthropic.com
The classifier pipeline: a fast yes/no filter handles the common case, with chain-of-thought reasoning reserved for flagged actions.
Source: anthropic.com
What It Does Not Tell You
Anthropic recommends running Auto Mode only inside a sandboxed environment. That recommendation does most of the heavy lifting here. If the classifier misses an exfiltration attempt inside a Docker container, the damage is bounded. If it misses one on a developer's primary machine with access to SSH keys, AWS credentials, and production configs, the miss rate numbers are less reassuring.
The classifier also can't reason about environmental context. It evaluates actions against what it knows about typical developer tasks, not against what your specific project's blast radius looks like. Deleting a test fixture and deleting a Terraform state file look similar at the tool-call level; the stakes are not.
Anthropic also hasn't said how the classifier improves over time. If it's a static model, its false negative rate on real adversarial prompts will likely increase as developers and researchers discover its boundaries. If it's updated regularly, that introduces its own supply-chain questions - the same ones that made the LiteLLM credential theft incident possible.
Auto Mode is available now in Claude Code for Team plan users, with Enterprise and API rollout in the days following launch. This follows Claude Code's Remote Control feature shipped in February, and signals that Anthropic is treating Claude Code as a serious agentic runtime rather than just a coding assistant.
"The classifier may still allow some risky actions: for example, if user intent is ambiguous, or if Claude doesn't have enough context about your environment to know an action might create additional risk."
- Anthropic, Claude Code Auto Mode documentation
Anthropic's own warning here is the most honest part of the release. Auto Mode is not a safety guarantee. It's a reasonable default that reduces friction without eliminating risk - which is probably the right trade for a developer tool in 2026. The developers who were already using --dangerously-skip-permissions will find Auto Mode meaningfully safer. The developers who were manually approving every action will find it meaningfully faster. Neither group should assume the classifier is infallible.
Sources: Anthropic Engineering Blog - Claude Code Auto Mode | Anthropic News | TechCrunch | Engadget

