AutoKernel - AI Agents That Write Faster GPU Kernels
RightNow AI releases AutoKernel, an open-source MIT-licensed framework that runs an autonomous LLM agent loop overnight to produce optimized Triton kernels for any PyTorch model.

You point it at a PyTorch model, tell it to run, and go to sleep. By morning it hands you a set of Triton kernels tuned specifically for your hardware. That is the pitch behind AutoKernel, a framework released today by RightNow AI that applies an autonomous LLM agent loop to GPU kernel optimization - no CUDA expertise required.
The project drops with an arXiv paper from authors Jaber Jaber and Osama Jaber and already has roughly 1,000 GitHub stars within hours of the release post going up on Hacker News.
TL;DR
- AutoKernel runs an iterative edit-benchmark-revert agent loop on GPU kernels for ~300-400 experiments overnight per kernel
- Beats
torch.compileon 12 of 16 tested configurations; reaches 5.29x over PyTorch eager on RMSNorm - Supports 9 kernel types (matmul, softmax, layernorm, RMSNorm, Flash Attention, SwiGLU, cross-entropy, RoPE, parallel reduction) via Triton and CUDA C++
- MIT licensed, runs on NVIDIA H100/A100/L40S and AMD MI300X/MI350X; also tested on RTX 4090
- Lags clearly behind cuBLAS on compute-bound matmul - the authors are transparent about this
How the Agent Loop Works
Unlike one-shot kernel generators, AutoKernel runs a closed feedback loop. There are three phases.
Phase A: Profiling
The system uses torch.profiler with shape recording to capture per-kernel GPU time across the full forward pass. It detects the target GPU automatically and ranks each kernel by runtime contribution using Amdahl's law - the bottleneck kernels get the agent's attention first.
Phase B: The Edit Loop
This is the core. The agent adjusts a single file - kernel.py - and a fixed benchmark harness assesses the change through five correctness checks before measuring performance. If the new kernel is faster and correct, the change is kept. Otherwise it reverts. Each iteration takes roughly 90 seconds.
At that rate you get about 40 experiments per hour, or 300-400 over an overnight run. The agent keeps working on a kernel until one of four conditions triggers a move-on: five consecutive reverts, 90% peak GPU utilization, two hours elapsed, or a 2x speedup reached.
The entire strategy the agent draws from is encoded in program.md, a 909-line document that RightNow calls the "research org code." It's basically a ranked playbook of GPU optimization techniques across six tiers:
- Block size tuning (10-50% gains) - power-of-2 tile dimensions, warp counts, pipeline stages
- Memory access (10-30%) - coalesced loads, software prefetching, L2 swizzling, shared memory padding
- Compute (5-15%) - TF32 accumulation, epilogue fusion, loop invariant hoisting
- Advanced (5-20%) - split-K, persistent kernels, Triton autotune, warp specialization
- Architecture-specific (5-15%) - TMA on Hopper, cp.async on Ampere
- Kernel-specific - online softmax for attention, Welford's algorithm for normalization
The agent reads from this document, applies a change, sees the benchmark result, and adapts. It isn't doing anything architecturally exotic - but the playbook encoding real expert knowledge is the part that makes it work better than naive sampling.
Phase C: Verification
After optimization completes, AutoKernel runs end-to-end correctness and speedup validation against the original model. The results log everything to a plain results.tsv capturing experiment number, throughput in TFLOPS or GB/s, speedup, correctness status, and VRAM usage.
 The AutoKernel benchmark suite was run on a NVIDIA H100, though the framework supports A100, L40S, and AMD MI300X/MI350X targets as well.
Source: commons.wikimedia.org
The AutoKernel benchmark suite was run on a NVIDIA H100, though the framework supports A100, L40S, and AMD MI300X/MI350X targets as well.
Source: commons.wikimedia.org
Getting Started
Running AutoKernel against a model is a few lines:
git clone https://github.com/RightNow-AI/autokernel
cd autokernel
pip install -r requirements.txt
from autokernel import optimize
# Point at any PyTorch model
optimize(
model=your_model,
sample_inputs=sample_inputs,
backend="triton", # or "cuda"
target_gpu="H100", # auto-detected if omitted
budget_hours=8, # overnight run
)
The framework handles profiling, kernel extraction, the agent loop, and validation. Outputs land in an optimized_kernels/ directory with drop-in replacements for the original PyTorch ops.
Benchmark Results
Tested on a H100 against PyTorch 2.x eager mode and torch.compile with max-autotune:
| Kernel | Size | vs PyTorch Eager | vs torch.compile |
|---|---|---|---|
| RMSNorm | 8192 x 8192 | 5.29x | 2.83x |
| Softmax | 8192 x 8192 | 2.82x | 3.44x |
| Cross-Entropy | 8192 x 32k vocab | 2.21x | 2.94x |
| LayerNorm | 8192 x 4096 | 1.25x | 3.21x |
AutoKernel beats torch.compile on 12 of 16 configurations tested. Memory-bound operations - normalization, reduction, loss kernels - see the biggest gains because AutoKernel's loop can tune memory access patterns more aggressively than the one-shot compiler heuristics. The framework also claimed first place on a community vector sum reduction benchmark on B200, hitting 44.086 microseconds.
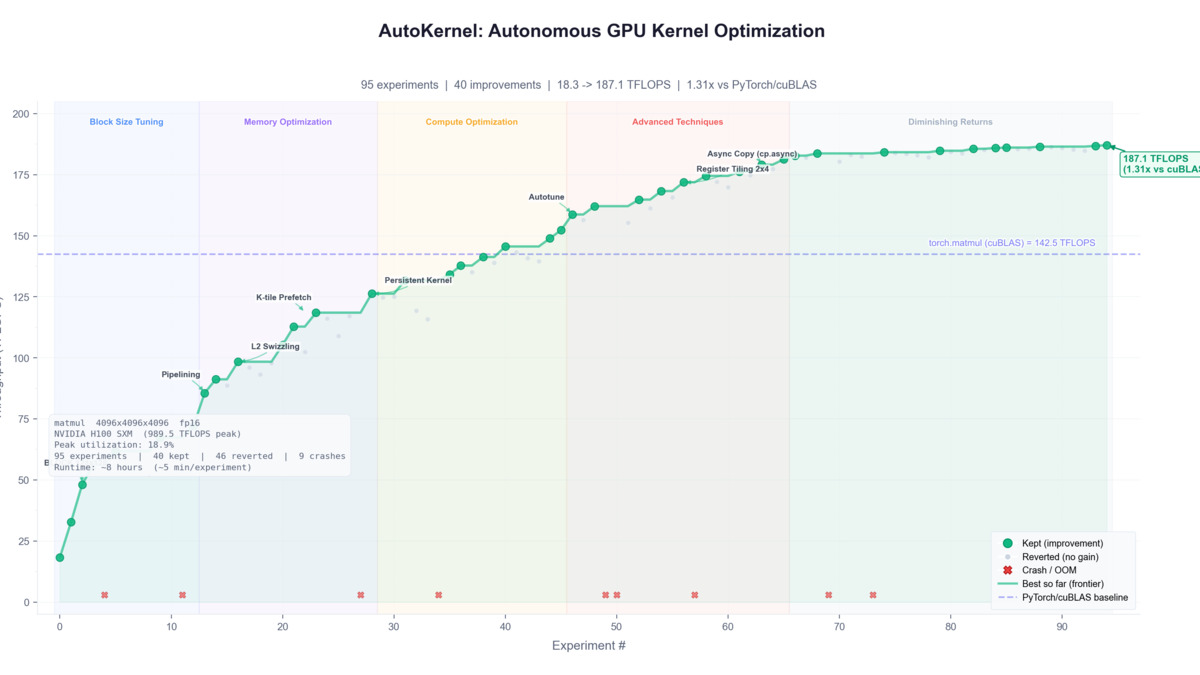 AutoKernel's progress.png from the GitHub README shows how speedup builds across the agent's iterative experiment loop.
Source: github.com/RightNow-AI/autokernel
AutoKernel's progress.png from the GitHub README shows how speedup builds across the agent's iterative experiment loop.
Source: github.com/RightNow-AI/autokernel
Hardware and Compatibility
| Requirement | Detail |
|---|---|
| Python | 3.9+ |
| PyTorch | 2.0+ |
| Triton backend | NVIDIA H100, A100, L40S, B200; AMD MI300X, MI350X; RTX 4090 |
| CUDA backend | Any CUDA 11.8+ GPU |
| LLM API | OpenAI, Anthropic, or local model with API compatibility |
| Minimum VRAM | 16 GB recommended (40 GB+ for large model runs) |
| License | MIT (code), CC BY 4.0 (paper) |
The benchmark harness is fixed. Only the kernel changes. That constraint is what makes the loop trustworthy - the agent can't cheat its own eval.
How It Compares
This isn't the first system to apply AI-driven iteration to GPU code. Google's AlphaEvolve hit 23% acceleration on specific kernels and reportedly cut 1% off Gemini training time. The difference is that AlphaEvolve is closed, internal to Google, and not configurable for arbitrary models. AutoKernel is MIT-licensed and runs against whatever you point it at.
Meta's KernelEvolve took a similar agentic approach but was built for Meta's internal production kernels and isn't publicly available. The AutoAgent framework from MIT applied self-optimizing loops to agent orchestration; AutoKernel brings the same concept down to the kernel level.
Andrej Karpathy's autoresearch concept - autonomous loops running overnight experiments - is clearly an intellectual ancestor here. RightNow AI is applying that pattern to a domain where iteration has historically required years of human expertise.
Where It Falls Short
The honest assessment is that matmul performance is a weak spot. AutoKernel's Triton starter reaches 278 TFLOPS on H100 against cuBLAS at 989.5 TFLOPS - roughly 28% of peak. On compute-bound workloads where cuBLAS and CUTLASS are dominant, the framework currently doesn't come close.
Hacker News commenters pushed back on this. User aviinuo noted that for 4kx4kx4k FP16 matmul, "cutlass is like 3x faster than this." User ademeure flagged inconsistency in the matmul benchmark claim, pointing out that a reported 18.9% peak use on H100 doesn't square with the claimed cuBLAS comparison numbers.
The framework also has hard scope limits: single-GPU only, no support for distributed kernels or multi-device memory management, and code generation limits mean the agent can't yet handle complex techniques like software pipelining or custom PTX emission.
At 40 experiments per hour, a difficult kernel may need multiple overnight runs to converge. RightNow AI is transparent about all of this in the paper.
 AutoKernel is designed for single-GPU optimization; multi-GPU distributed kernel support is on the roadmap.
Source: commons.wikimedia.org
AutoKernel is designed for single-GPU optimization; multi-GPU distributed kernel support is on the roadmap.
Source: commons.wikimedia.org
What To Watch
RightNow AI is a NVIDIA Inception Program member, and AutoKernel is closely integrated with their commercial AI code editor for CUDA/Triton development (free tier, $20/month Pro). The open-source release follows a pattern of using community visibility to drive paid-product adoption - the framework shows the technology, the editor is where you use it day-to-day.
The interesting question is whether the program.md playbook gets contributed to by the community over time. The six-tier optimization hierarchy is the intellectual core of the system. Opening it up to community improvements could make the agent meaningfully more capable without requiring changes to the loop architecture.
For teams running large training runs who already know their bottleneck kernels, this is worth testing today. For everyone else, the "go to sleep" pitch is real - the system runs unattended and gives you something concrete in the morning, even if it won't compete with cuBLAS on every workload.
Sources:

