AutoAgent Builds Its Own Harness, Tops Two Benchmarks
Kevin Gu's MIT-licensed AutoAgent lets a meta-agent engineer and hill-climb its own agent harness overnight, claiming the top GPT-5 slot on TerminalBench and first place on SpreadsheetBench.

A new open-source library called AutoAgent flips the standard agent-development workflow on its head: instead of engineers hand-tuning a system prompt and tool list, the framework hands that job to another agent, runs it overnight, and iterates until scores stop climbing.
The project, released this week under the MIT license by Kevin Gu - co-founder of Y Combinator W25 startup ThirdLayer - claims to have reached 96.5% on SpreadsheetBench (first place overall) and a 55.1% GPT-5 score on TerminalBench (first among GPT-5 runs), according to Gu's announcement. Every other entry on both leaderboards was human-engineered. The AutoAgent runs weren't.
TL;DR
- MIT-licensed meta-agent framework that engineers and optimizes its own agent harness autonomously overnight
- Claims 96.5% on SpreadsheetBench (#1) and 55.1% on TerminalBench (top GPT-5 score), per the creator's announcement
- Three-file architecture:
agent.py(harness),program.md(directive),tasks/(benchmarks) - humans only editprogram.md - All task execution is Docker-sandboxed; meta-agent reads scores and hill-climbs the harness
- Benchmark scores come from creator's own announcement and don't yet appear on the official leaderboards
How the Self-Optimization Loop Works
The core mechanic is simple but the effects are broad. AutoAgent centers on three files.
The Three-File Architecture
agent.py is a single-file harness containing tool definitions, routing logic, an agent registry, and configuration. A fixed "Harbor adapter" section at the bottom is immutable - everything above it is fair game for the meta-agent to rewrite.
program.md is the only file a human ever edits. It contains the meta-agent's directive: what kind of agent to build, what domain it should operate in, and the instructions governing the engineering loop.
tasks/ holds benchmark tasks in Harbor format. Each task produces a score between 0.0 and 1.0. That score is the signal the meta-agent hill-climbs.
The Overnight Loop
Once started, the process runs without human input:
1. Read directive from program.md
2. Inspect the current harness in agent.py
3. Run benchmark tasks from tasks/ directory
4. Diagnose failures in the task outputs
5. Modify agent.py to address them
6. Discard changes that regress the score
7. Repeat from step 2
All task execution happens inside Docker containers. If a produced tool causes a crash or runaway process, it can't reach the host. That's a sensible design for a framework that encourages running arbitrary LLM-produced code.
# Quick start: point AutoAgent at a task set and let it run
git clone https://github.com/kevinrgu/autoagent
cd autoagent
# Edit program.md to describe what agent you want
# Add your tasks to tasks/
python run.py --overnight
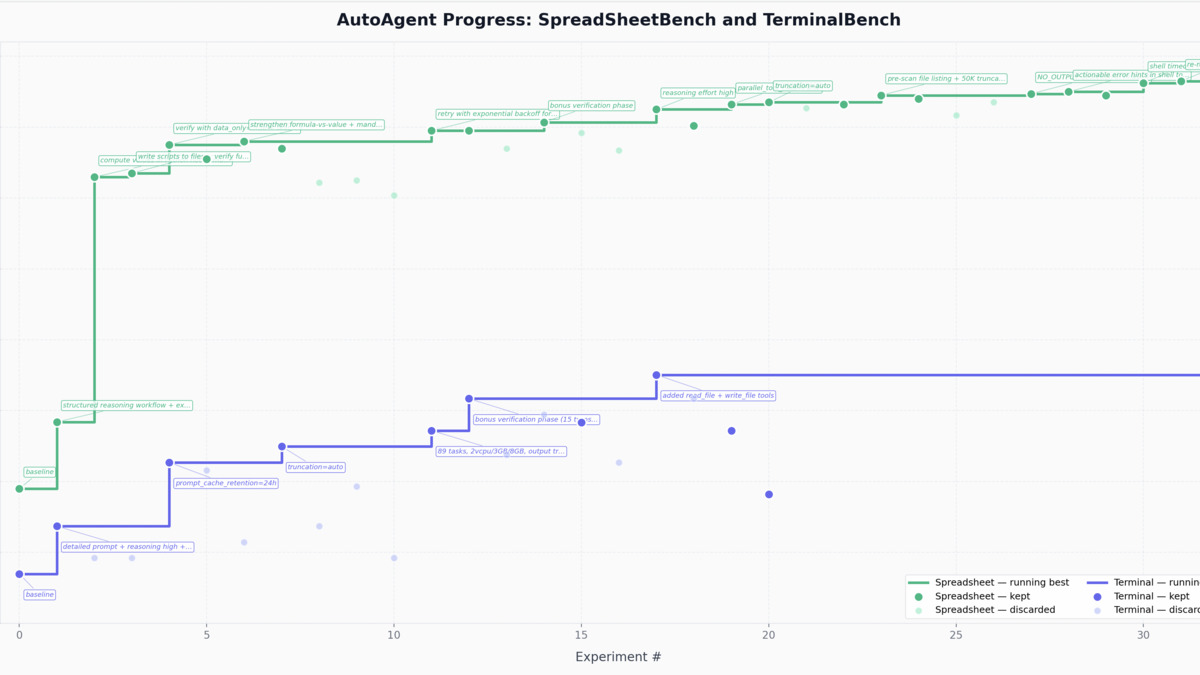 AutoAgent's benchmark scores during an autonomous overnight harness engineering run, showing the hill-climbing progression as the meta-agent iterates.
Source: github.com/kevinrgu/autoagent
AutoAgent's benchmark scores during an autonomous overnight harness engineering run, showing the hill-climbing progression as the meta-agent iterates.
Source: github.com/kevinrgu/autoagent
Benchmark Claims - With Caveats
The headline numbers are striking, but they need context before you act on them.
Gu's announcement states 96.5% on SpreadsheetBench and 55.1% on TerminalBench (top GPT-5). Those figures come from his X announcement post. As of April 5, the official SpreadsheetBench leaderboard at spreadsheetbench.github.io shows its highest verified entry at 34.89% (Claude Opus 4.6). The AutoAgent entry doesn't appear there yet. The TerminalBench leaderboard at tbench.ai similarly doesn't list it - the current leader, ForgeCode, sits at 81.8% overall.
This gap could mean the AutoAgent run targeted a specific task subset, a benchmark variant, or a prior leaderboard snapshot. It could also mean the submissions are pending verification. Gu hasn't clarified publicly today.
That said, even verified partial-subset dominance on SpreadsheetBench would be a real result. The benchmark covers genuinely hard Excel/spreadsheet tasks - debugging formulas, building financial models, creating charts from templates.
 SpreadsheetBench V2 task categories. AutoAgent claims 96.5% on this benchmark, though the score hasn't yet appeared on the official leaderboard.
Source: spreadsheetbench.github.io
SpreadsheetBench V2 task categories. AutoAgent claims 96.5% on this benchmark, though the score hasn't yet appeared on the official leaderboard.
Source: spreadsheetbench.github.io
What the Numbers Do Show
Even setting aside leaderboard position, the hill-climbing mechanic is provably real. The progress visualization in the repo shows scores rising over multiple iterations during an overnight run. The meta-agent is truly adjusting the harness, not just picking from a preset menu of configurations.
If you're building an agent for a narrow, well-specified domain and you have a working test suite, that progression is directly applicable. You hand it a task set, let it run, and come back to a harness that's been stress-tested and refined against your actual workload.
Requirements
| Requirement | Details |
|---|---|
| License | MIT |
| Language | Python |
| Container runtime | Docker (required for task sandboxing) |
| Supported models | Any that support the Harbor adapter interface |
| Input format | program.md (natural language directive), tasks/ (Harbor-format benchmark tasks) |
| Cost | API costs for the LLM powering the meta-agent + task agent |
For context on how this fits into the broader agent framework ecosystem, the best AI agent frameworks guide covers the incumbent options AutoAgent aims to replace the engineering overhead of.
 TerminalBench tests agents on real terminal tasks. AutoAgent claims the top GPT-5 score at 55.1%.
Source: tbench.ai
TerminalBench tests agents on real terminal tasks. AutoAgent claims the top GPT-5 score at 55.1%.
Source: tbench.ai
Where It Falls Short
Self-optimization works when you have a clean scoring function. Most real-world agent tasks don't have one. If your agent handles customer support tickets, generating leads, or doing open-ended research, writing a Harbor-format benchmark that actually captures production quality is non-trivial work - and it's entirely on you.
There's also a model-pairing effect worth watching. Gu's repo notes that a Claude meta-agent tuning a Claude task agent appears to diagnose failures more accurately than when tuning a GPT-based task agent. If that holds up with more data points, it introduces a constraint that complicates cost optimization - you can't just use the cheapest meta-agent available.
The Docker requirement is sensible for safety but adds friction for teams not already running containerized workflows. And the framework is truly early: the repo has minimal documentation beyond the README, no published reliability numbers beyond the claimed benchmark scores, and no examples outside the SpreadsheetBench and TerminalBench cases.
For teams already maintaining test suites for their agents - something like the setups discussed in the best LLM eval tools guide - the lift to try AutoAgent is low. For teams who haven't invested in evaluation infrastructure, the framework won't solve that problem for you.
AutoAgent is available now at github.com/kevinrgu/autoagent under the MIT license. ThirdLayer's primary commercial product, Dex - described as a browser AI copilot for knowledge work - is separate, though the self-tuning harness work clearly informs how the company thinks about agent reliability at scale.
Sources:

