Arcee's Trinity-Large: 398B Open Reasoning at $0.90
Arcee AI ships Trinity-Large-Thinking, a 398B sparse MoE reasoning model under Apache 2.0 that hits 91.9% on PinchBench for $0.85 per million output tokens on OpenRouter.

A 26-person startup just shipped a 398-billion-parameter open reasoning model that sits one slot below Claude Opus 4.6 on the most widely used agent benchmark - at roughly 96% less per token.
Key Specs
| Spec | Value |
|---|---|
| Total Parameters | 398B |
| Active per Token | ~13B |
| Architecture | Sparse MoE, 4-of-256 experts |
| Context Window | 512K tokens |
| License | Apache 2.0 |
| API Price (output) | $0.85/M tokens (OpenRouter) |
| PinchBench Score | 91.9 (vs. Opus 4.6 at 93.3) |
| Released | April 1, 2026 |
Arcee AI dropped Trinity-Large-Thinking on April 1, making weights freely available on Hugging Face under Apache 2.0 and the model accessible via their own API and OpenRouter. The company has about 26 people and no disclosed funding round that comes close to the compute budgets of the labs it's benchmarking against.
How 13B Active Parameters Carry 398B Total
The model sits on a hybrid sparse Mixture-of-Experts architecture. Each token activates only 4 of 256 available experts, so actual compute per forward pass is roughly 13B parameters - comparable to a mid-tier dense model - while the weight space holds knowledge across the full 398B.
Attention and Routing
Trinity-Large-Thinking uses Grouped Query Attention (GQA) across its expert layers, which cuts KV cache pressure relative to multi-head attention at the same parameter count. The 4-of-256 routing ratio is relatively tight; Mixtral-style models typically use 2-of-8, meaning far fewer experts compete here but each expert is much larger.
Reasoning Format
The model generates explicit chains of thought inside <think>...</think> blocks before producing output. For agentic loops, Arcee recommends keeping those thinking tokens in message history across turns - omitting them degrades multi-turn tool-call stability in their internal evaluations.
Training Scale
Pretraining ran across 2,048 NVIDIA B300 GPUs on 17 trillion tokens. Post-training - covering the extended chain-of-thought work and agentic reinforcement learning - used 1,152 H100s. Production inference runs on NVIDIA Dynamo with Blackwell Ultra GPUs and vLLM handling batching.
Benchmark Comparison
The numbers below come from Arcee's model card on Hugging Face, with all SWE-bench Verified scores measured under mini-swe-agent-v2.
| Benchmark | Trinity-Large-Thinking | Opus-4.6 | GLM-5 | MiniMax-M2.7 | Kimi-K2.5 |
|---|---|---|---|---|---|
| PinchBench | 91.9 | 93.3 | 86.4 | 89.8 | 84.8 |
| τ²-Bench (Telecom) | 94.7 | 92.1 | 98.2 | 84.8 | 95.9 |
| τ²-Bench (Airline) | 88.0 | 82.0 | 80.5 | 80.0 | 80.0 |
| LiveCodeBench / AIME25 | 96.3 | 99.8 | 93.3 | 80.0 | 96.3 |
| SWE-bench Verified | 63.2 | 75.6 | 72.8 | 75.4 | 70.8 |
| MMLU-Pro | 83.4 | 89.1 | 85.8 | 80.8 | 87.1 |
| GPQA-Diamond | 76.3 | 89.2 | 81.6 | 86.2 | 86.9 |
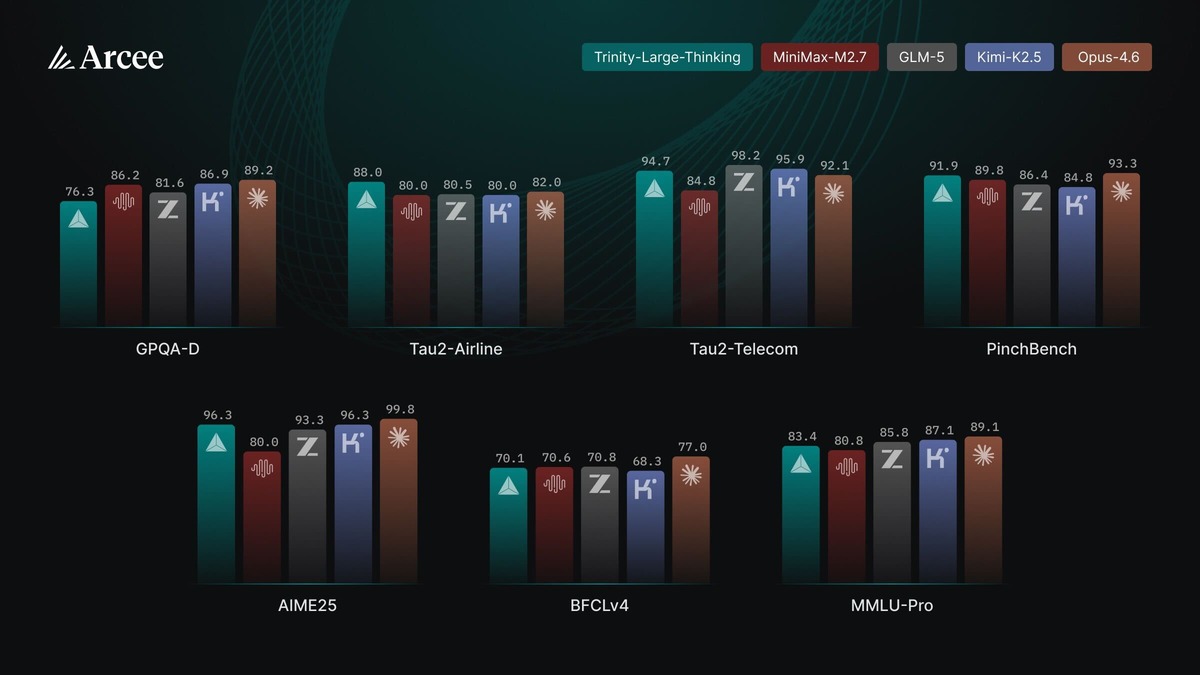 Benchmark comparisons across PinchBench, τ²-Bench, and coding evals from the official model card.
Source: huggingface.co
Benchmark comparisons across PinchBench, τ²-Bench, and coding evals from the official model card.
Source: huggingface.co
Trinity leads on both τ²-Bench airline scheduling and PinchBench among non-Opus models. It trails on coding (SWE-bench, GPQA), and its MMLU-Pro score of 83.4 puts it behind every proprietary frontier model in the table. The pattern is consistent: the model punches above its weight on tool-calling and multi-turn agent tasks, less so on pure knowledge and reasoning benchmarks.
PinchBench is built by Kilo and measures model performance specifically as the reasoning core of an OpenClaw agent - scheduling, tool selection, multi-step task completion. It's arguably the benchmark that most directly maps to where Trinity is targeted.
What the OpenRouter Numbers Say
Trinity-Large-Preview - the non-thinking predecessor - served 3.37 trillion tokens on OpenRouter in its first two months and became the most-used open model in the U.S. on OpenRouter's OpenClaw collection. That's a substantial usage base for a model from a company this small, and it suggests the audience for a cheaper, more capable follow-up is already there.
On OpenRouter, Trinity-Large-Thinking is priced at $0.22 per million input tokens and $0.85 per million output tokens, routed through Parasail with fp8 quantization. Opus 4.6 lists at $15 input / $75 output on most providers. The math is stark for teams running thousands of agent turns per day.
The available context on OpenRouter is 262,144 tokens rather than the 512K the full weights support - a consequence of the quantization and provider memory constraints. If you need the full window, you'll need to run the weights yourself.
Where It Runs
The weights are on Hugging Face. Apache 2.0 means you can fine-tune, modify, and ship commercially without asking anyone's permission.
Self-hosting 398B sparse parameters isn't trivial. At fp16 precision, the full model requires roughly 800GB of GPU memory - about 10 H100s at 80GB each, or 5-6 H200s at 141GB. The GGUF quantized version (arcee-ai/Trinity-Large-Thinking-GGUF) brings that down significantly, though Arcee hasn't published specific hardware benchmarks for the quantized variants.
For teams who don't want to manage their own cluster, the model runs on OpenRouter and DigitalOcean, with Arcee's own API as a third option.
The model is compatible with both OpenClaw and the Hermes Agent framework. Arcee published a setup guide for Hermes Agent with the release.
What To Watch
The benchmark gap is real in places. SWE-bench Verified at 63.2 puts Trinity 12 points behind Opus 4.6 and nearly 10 behind GLM-5. GPQA-Diamond at 76.3 trails Opus by 13 points. For codegen-heavy workloads or tasks requiring deep domain reasoning, the cost difference doesn't automatically justify the performance trade-off.
The 512K context window (262K in practice on OpenRouter) also limits use cases involving very long documents or extended conversation histories compared to models now offering 1M+ context.
Arcee has said the lessons from Trinity-Large's development will feed into Trinity-2-Nano and Mini through distillation. Smaller, faster, cheaper versions of this architecture would be worth watching for edge and local deployment scenarios - comparable to what NVIDIA Nemotron 3 is doing at the Super and Ultra tiers with a similar efficiency-first design.
The more interesting question is whether the agentic AI benchmark gap between Apache 2.0 open models and top proprietary models has narrowed enough for production use. On PinchBench, Trinity sits 1.4 points behind Opus 4.6. Whether that gap matters depends entirely on how many tasks in your agent loop fail at exactly that margin.
Sources:

