ARC-AGI-3 Launches - AI Agents Must Learn, Not Memorize
ARC Prize Foundation launched ARC-AGI-3 today with a fully open-source agent toolkit. The best AI in the preview phase scored 12.58% against a human baseline of 100%.

TL;DR
- ARC-AGI-3 launched today at Y Combinator with a pip-installable, MIT-licensed Python toolkit
- First interactive AI benchmark - agents must explore video-game-like environments with no stated rules or goals
- Best AI agent in the 30-day preview scored 12.58%; frontier LLMs scored under 1%; humans score 100%
- Over $2 million in prizes across three tracks; all winning solutions must be open-sourced, no external APIs allowed
The ARC Prize Foundation launched ARC-AGI-3 today at Y Combinator in San Francisco, and it marks the most significant change to the ARC benchmark series since François Chollet introduced the original in 2019. Versions 1 and 2 tested static grid puzzles: show an AI a pattern, ask it to complete a new one. Version 3 tests something harder. Can an AI agent learn the rules of an unfamiliar environment by exploring it, with no instructions and no stated goals?
Based on four weeks of developer preview data: not really. The best system scored 12.58%. Frontier LLMs scored under 1%. Humans score 100%.
From Static Puzzles to Live Environments
ARC-AGI-1 and ARC-AGI-2 are image-in, image-out benchmarks. You present a grid showing an input/output pattern, and the system must produce the correct output for a new instance. They test abstraction and pattern recognition. By 2025, frontier models were hitting 90%+ on version 1, which pushed the ARC team to build version 2 with harder compositional puzzles where even the best systems score in the low teens.
ARC-AGI-3 changes the format completely.
What the Agent Sees
Each environment is a turn-based game with its own internal logic. There are no instructions, no descriptions, no stated win conditions. The agent sees a visual state, takes an action, sees the result, and must figure out what it's trying to do and how to do it - on the fly, without any prior exposure to the game.
The benchmark includes hundreds of handcrafted environments and thousands of levels. Each game contains 8-10 levels, with each successive level introducing new mechanics. Three games were available in the public preview: ls20 (map navigation with symbol transformations), ft09 (pattern matching across overlapping grids), and vc33 (volume adjustment to match target heights).
How Scoring Works
Scoring isn't binary pass/fail. The benchmark measures action efficiency - how efficiently does the agent reach the goal compared to a human player? A perfect score is 100%. Agents that wander, backtrack, or brute-force their way through levels get penalized accordingly.
This is the first AI benchmark that formally measures human vs. AI learning efficiency rather than just capability. The research team collected data from 1,200+ human players across 3,900+ games during the preview period. Those human runs are the baseline every AI agent is scored against.
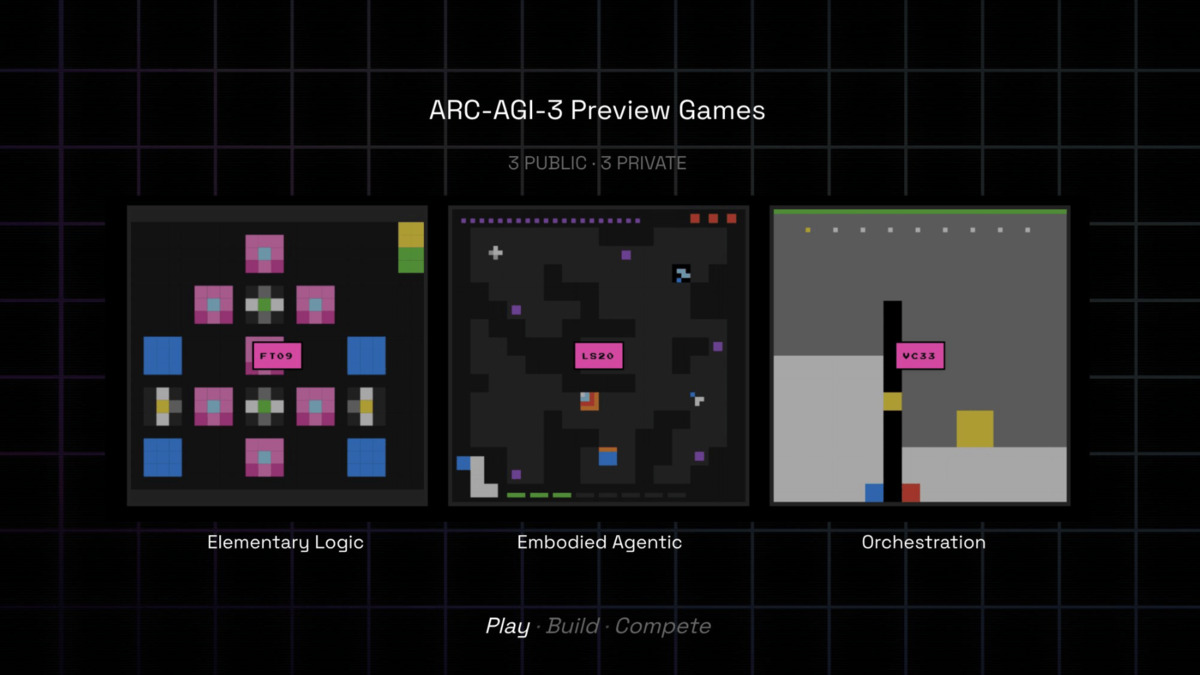 Three public preview environments from ARC-AGI-3. Agents must discover the rules and win conditions without any instructions.
Source: the-decoder.com
Three public preview environments from ARC-AGI-3. Agents must discover the rules and win conditions without any instructions.
Source: the-decoder.com
The Open-Source Toolkit
The benchmarking toolkit is on GitHub under the MIT license. Installation is straightforward:
pip install arc-agi
# or
uv add arc-agi
You need an ARC API key from arcprize.org to run evaluations, even locally. The CLI includes a --check flag to verify all connections before you start, --list-games to browse available environments, and --list-models to see which providers and models you can use.
Supported Inference Backends
The toolkit wraps most major inference providers out of the box:
| Provider | Models |
|---|---|
| OpenAI | GPT-4o, GPT-5.x series |
| Anthropic | Claude 3.5/4.x series |
| Gemini 3.x series | |
| OpenRouter | Multi-provider routing |
| Fireworks | Fast inference |
| Groq | Low-latency inference |
| DeepSeek | DeepSeek-V3, R1 series |
| Hugging Face | Open weights via Inference API |
Running an Agent
The core API is minimal. You instantiate a game environment, pass actions in, and read state back:
import arc
game = arc.make("ls20") # instantiate game environment by ID
state = game.reset() # get initial observation
# your agent logic here
action = arc.GameAction(...) # define an action
state, reward, done, info = game.step(action)
The runtime supports execution at over 2,000 frames per second with rendering disabled - important for training loops. A hosted API route and browser-based interface are also available for teams that want to test without local setup.
 François Chollet introduced ARC in 2019. He co-founded the ARC Prize Foundation with Mike Knoop in 2024 to fund and structure the competition.
Source: commons.wikimedia.org
François Chollet introduced ARC in 2019. He co-founded the ARC Prize Foundation with Mike Knoop in 2024 to fund and structure the competition.
Source: commons.wikimedia.org
What the Preview Numbers Show
The four-week developer preview ran before today's official launch. The private leaderboard tells a clear story:
| System | Approach | Score | Levels Completed |
|---|---|---|---|
| StochasticGoose | CNN + structured search | 12.58% | 18 |
| Blind Squirrel | State graph exploration | 6.71% | 13 |
| Explore It Till You Solve It | Frame graph | 3.64% | 12 |
| Best frontier LLM agent | LLM-based | <1% | ~2-3 |
| Human players | Human | 100% | varies |
The top three systems were all non-LLM approaches. Explicit graph search, state tracking, and systematic exploration outperformed every frontier language model by a substantial margin. A CNN-based agent doing structured exploration beat GPT-5.x series agents by over 12 percentage points.
A published arXiv paper from the preview period (Rudakov et al., arXiv:2512.24156) formalized this: a training-free graph-based exploration system ranked third on the private leaderboard, solving a median of 30 out of 52 levels across 6 games. Their conclusion is direct - systematic state tracking matters more than raw model size for this task.
Chollet's position on what this gap means: "AI can do many things, but it cannot have general intelligence as long as this fundamental divide exists."
For context on where ARC-AGI-3 fits within the broader agent evaluation landscape, see our agentic AI benchmarks leaderboard. If you're new to how AI benchmarks work, the understanding AI benchmarks guide is a good starting point before diving into the methodology.
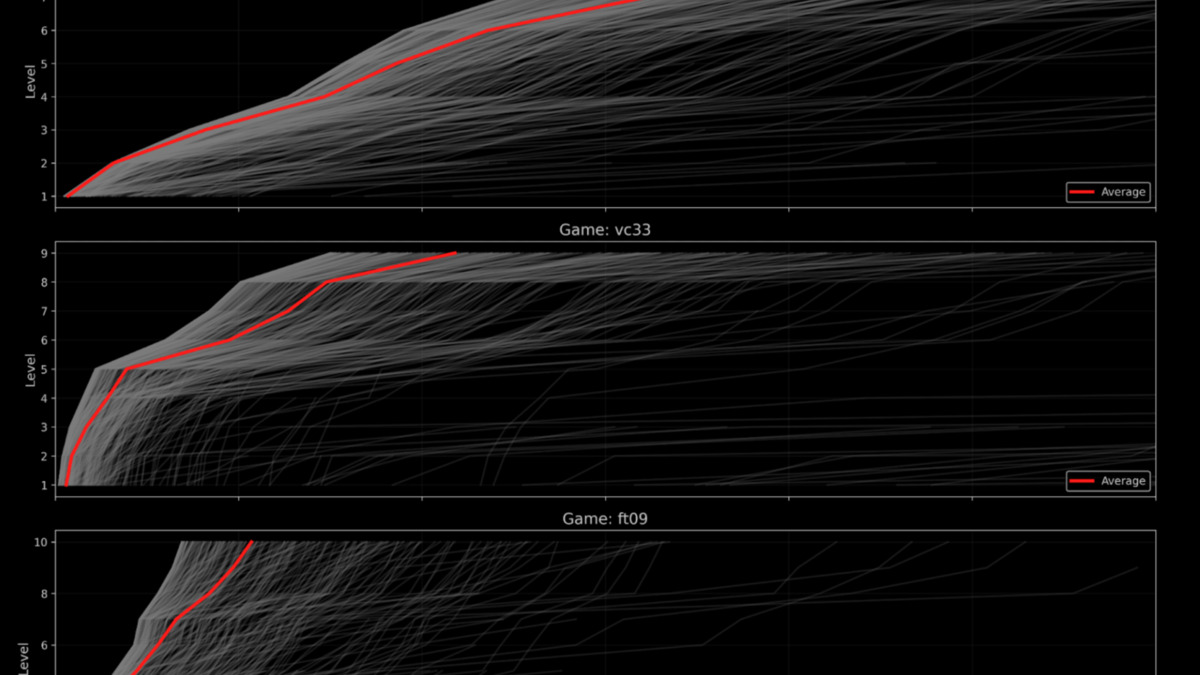 Human player data from the 30-day preview showing level completion as a function of actions taken. This data sets the baseline AI agents must beat.
Source: arcprize.org
Human player data from the 30-day preview showing level completion as a function of actions taken. This data sets the baseline AI agents must beat.
Source: arcprize.org
Competition Structure
ARC Prize 2026 runs three parallel tracks with a total prize pool over $2 million, all managed through the competition page.
The ARC-AGI-3 track is the new addition. Milestone checkpoints fall on June 30 and September 30, with submissions closing November 2. Results are announced December 4. All participants must open-source their solutions under permissive licenses (MIT or CC0). Kaggle evaluation runs with no internet access, meaning no API calls to external inference endpoints during scoring. If your agent requires a frontier model call to function, it won't qualify.
The ARC-AGI-2 grand prize continues with it - a separate award for the best open-source solution to the static compositional benchmark, which went unclaimed in 2025.
This structure is similar in spirit to what Ai2 did with MolmoWeb last month - open-source the tooling, force solutions to be reproducible, and let the community benchmark honestly. ARC Prize takes it further by making open-sourcing a competition requirement rather than a bonus.
Where It Falls Short
The API Key Gate
The toolkit requires an ARC API key even for local execution. ARC-AGI-1 and ARC-AGI-2 were fully offline datasets you could download and run without registering anywhere. Adding a registration requirement raises the friction for researchers at smaller institutions or in regions where account creation is harder. It's not a blocking issue, but it's a step backward in accessibility compared to the prior versions.
No External Inference During Competition
The no-internet rule on Kaggle is technically clean but creates an awkward split. The toolkit supports OpenAI, Anthropic, and Google as backends - but none of those work during official evaluation. Teams that want to compete seriously must either run open weights locally or build non-LLM systems like the preview leaderboard winners. The benchmark's stated goal is to test general intelligence, but the competition format may end up selecting for efficient search algorithms rather than genuinely adaptive agents.
Handcrafted Environments Don't Scale
The environments are manually designed, which means they're expensive to produce and carry their designers' assumptions. The 150+ environments at launch is a reasonable starting set, but a well-engineered search system could saturate the available games over a 12-month competition window. The ARC team will need to add new environments continuously, or publish a clear methodology for doing so, to keep the leaderboard meaningful past the first milestone.
Scoring Opacity
The action-efficiency scoring methodology is described in the technical report, but the specific weighting across game types isn't fully transparent in the public documentation. If different games contribute differently to the total score, teams will optimize toward high-weight games rather than building general-purpose agents. Transparent per-game weights would help the community understand what's actually being measured.
The toolkit ships today at docs.arcprize.org. The benchmark's central claim - that you can't fake general intelligence with memorization - is worth taking seriously. The preview data backs it up. Whether the competition's self-hosted-only evaluation rule produces agents that are genuinely interesting or just better graph search is the question the June milestone should start to answer.
Sources:

