Inside Amazon's Trainium Lab - How It Beat NVIDIA
An exclusive TechCrunch tour of Amazon's Trainium chip lab reveals how AWS is training Claude for Anthropic and now holds an $138B commitment from OpenAI.

Amazon's custom AI chips are training Claude. They're also the foundation of a $138 billion commitment from OpenAI. TechCrunch got an exclusive tour of the Trainium lab in Austin this weekend, and the picture that emerged is of a company that quietly built a credible alternative to NVIDIA - not by matching raw compute numbers, but by engineering around them.
TL;DR
- Anthropic is running over 1 million Trainium2 chips to train Claude models; Amazon has rolled out 1.4 million Trainium chips total across all generations
- As part of its $50B investment in OpenAI, Amazon secured an $138 billion chip commitment from OpenAI over eight years and 2 gigawatts of compute capacity
- Trainium2 delivers 667 TFLOP/s - less than NVIDIA's GB200 at 2,500 - but costs 30-40% less per unit of useful work for training workloads
- Trainium3 (current generation) runs on 3nm process with 2.52 PFLOPS FP8 and is 50% cheaper for inference than H100 clusters
The Numbers Behind the Win
Amazon CEO Andy Jassy put it plainly in a statement accompanying the TechCrunch report: "The two largest AI labs are both significantly betting on Trainium." That's not marketing copy. Anthropic has deployed more than one million Trainium2 chips for Claude training. OpenAI has now committed, as part of the Amazon $50B investment deal, to spend $138 billion on Amazon chips over the next eight years.
The raw specs tell only part of the story. Trainium2, the previous-generation chip, sits well below NVIDIA's top hardware on peak compute:
| Chip | Peak Compute | Memory | Memory Bandwidth | Price-Performance vs H100 |
|---|---|---|---|---|
| NVIDIA GB200 | 2,500 TFLOP/s | 192 GB HBM3e | 8 TB/s | baseline |
| Amazon Trainium3 | 2,520 TFLOP/s FP8 | 144 GB HBM3e | 4.9 TB/s | +50% lower inference cost |
| Amazon Trainium2 | 667 TFLOP/s | ~96 GB HBM | 2,900 GB/s | 30-40% better vs H100 P5e |
Trainium2 losing to GB200 on raw TFLOP/s sounds damning until you read the SemiAnalysis breakdown: the chip's memory bandwidth per dollar is the variable that matters for large-scale reinforcement learning, and Amazon wins that comparison. Reinforcement learning - the method powering modern reasoning models - is memory-bound, not compute-bound.
 Inside the Amazon Trainium lab in Austin, where Anthropic's Claude models are trained. Amazon built this facility faster than any data center in its history.
Source: techcrunch.com
Inside the Amazon Trainium lab in Austin, where Anthropic's Claude models are trained. Amazon built this facility faster than any data center in its history.
Source: techcrunch.com
Inside the Trainium Architecture
Trainium3 - What Amazon Is Shipping Now
The current generation runs on a 3-nanometer process and delivers 2.52 PFLOPS of FP8 compute per chip, a 4.4x improvement over Trainium2. Memory has grown to 144 GB HBM3e per chip with 4.9 TB/s of bandwidth. Amazon's UltraServer configuration packs 144 Trainium3 chips into a single rack unit with 20.7 TB of aggregate HBM3e and 706 TB/s of aggregate memory bandwidth.
Scale matters. Amazon says these UltraServers can be linked up to one million chips - a figure that would represent a ten-fold jump from the previous generation's maximum cluster size.
The networking story is also new. NeuronLinkv3 is an all-to-all scale-up fabric that mirrors what NVIDIA built with NVLink, placing four switch trays in the center of each rack. Inter-chip communication latency sits below 10 microseconds. For the distributed training jobs running across hundreds of thousands of chips, that number directly affects training throughput.
Where Anthropic Sits in This Picture
According to the SemiAnalysis report published alongside the TechCrunch tour, Amazon is building more than 1.3 gigawatts of IT capacity across three AWS campuses specifically for Anthropic's training needs. Anthropic has "heavy involvement in all Trainium design decisions" - a co-design relationship that SemiAnalysis compares to Google DeepMind's deep integration with TPUs.
That's not a vendor-customer relationship. It's a hardware partnership where one of the world's most safety-focused AI labs is shaping the silicon roadmap of the world's largest cloud provider.
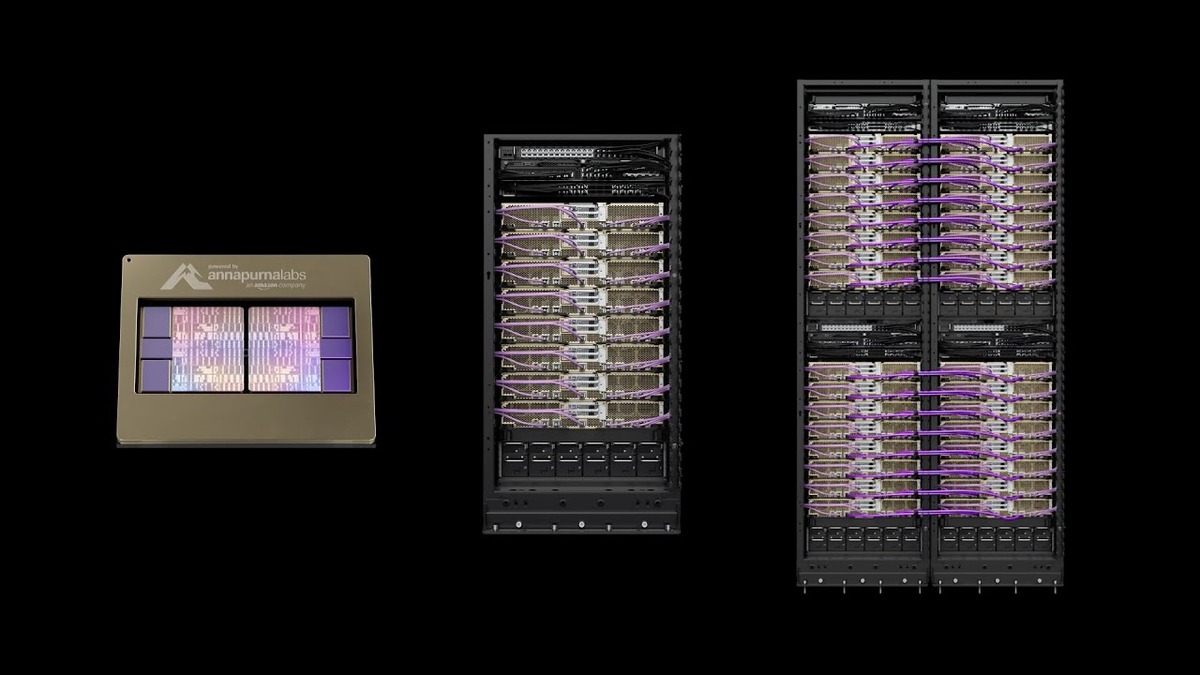 Amazon Trainium - Amazon's custom AI training silicon, now rolled out across more than 1.4 million chips in AWS data centers.
Source: aws.amazon.com
Amazon Trainium - Amazon's custom AI training silicon, now rolled out across more than 1.4 million chips in AWS data centers.
Source: aws.amazon.com
How OpenAI Fits In
The OpenAI dimension is newer and structurally different. OpenAI didn't co-design Trainium the way Anthropic did. The commitment comes as part of the larger $50 billion investment deal, and it's mostly a procurement agreement: $138 billion over eight years in exchange for 2 gigawatts of Trainium3 and Trainium4 compute capacity. OpenAI becomes, in effect, a large customer rather than a hardware partner.
Trainium4 - scheduled for late 2026 or early 2027 - promises a 6x improvement in FP4 performance, 3x in FP8, and a 4x jump in memory bandwidth over Trainium3. If those numbers hold, OpenAI will be training on hardware that didn't exist when the deal was signed.
The Microsoft lawsuit over the exclusivity terms of the OpenAI deal adds a complication to this picture. Microsoft has alleged that the AWS agreement violates terms of its own agreements with OpenAI. Whatever the outcome, Amazon has already secured commitments that no chip manufacturer outside NVIDIA has come close to.
What It Does Not Tell You
The TechCrunch tour wasn't an arms-length inspection. It was an invited tour, which means Amazon controlled what journalists saw and what context they received. No third-party benchmarks from this specific facility have been published. The 30-40% price-performance advantage over H100 P5e instances is Amazon's own figure, and the comparison is against H100, not GB200 - the chip NVIDIA is currently shipping.
NVIDIA's Vera Rubin platform, announced at GTC 2026, promises 50 PFLOPS of inference per GPU and claims 10x lower token cost than Blackwell. If that holds at scale, the Trainium3 cost advantage narrows sharply. Amazon's own Trainium4 roadmap is built in part as a response.
The deeper question is software. NVIDIA's CUDA ecosystem has decades of optimization work behind it. Amazon's Neuron SDK is improving - Anthropic's co-design work has pushed it forward - but the software stack still requires meaningful porting effort for teams that built on CUDA. The chips being cheaper doesn't automatically mean they're easier to use.
For now, the scorecard reads: Anthropic trains on Trainium, OpenAI has committed to doing the same. Amazon has two of the four major frontier AI labs running their most expensive workloads on its custom silicon, with a third - Apple - reportedly assessing Trainium for on-device inference work, according to the TechCrunch report. NVIDIA remains the dominant player by installed base and by software ecosystem, but Amazon has made the case that you can build a serious alternative. The Trainium2 deployment numbers from Anthropic are proof it runs at scale. The $138 billion from OpenAI is proof someone is willing to bet on it.
Sources: TechCrunch - Exclusive tour of Amazon's Trainium lab · SemiAnalysis - Amazon's AI Resurgence · Yahoo Finance - Anthropic 1M Trainium2 chips · About Amazon - AWS OpenAI strategic partnership

