Alibaba's Qwen3.6-Max Ships Closed - Tops Six Coding Evals
Alibaba released Qwen3.6-Max-Preview on April 20 as its first closed-weights flagship, ranking third globally on the Artificial Analysis Intelligence Index while topping six coding benchmarks.

Alibaba has crossed a line it never crossed before. Qwen3.6-Max-Preview, released April 20, ships without weights - no Hugging Face upload, no self-hosting path. For the first time in Qwen's history, the flagship tier is proprietary.
Key Specs
| Spec | Value |
|---|---|
| Released | April 20, 2026 |
| Context window | 256k tokens |
| Input modalities | Text only (no images) |
| API endpoint | qwen3.6-max-preview |
| API compatibility | OpenAI + Anthropic specs |
| Weights available | No |
| Pricing | Undisclosed (preview) |
| Intelligence Index | 52 (rank #3 of 203 models) |
The model tops six coding benchmarks - SWE-bench Pro, Terminal-Bench 2.0, SkillsBench, QwenClawBench, QwenWebBench, and SciCode - and sits third on the Artificial Analysis Intelligence Index with a score of 52, behind only the very top closed models from OpenAI and Anthropic.
Alibaba also shut down the free tier of Qwen Code on the same day. This wasn't accidental timing.
The Closed-Weights Pivot
Qwen has been one of the most aggressively open families in the frontier model space. Qwen3.6-Plus launched in April with a 1-million-token context window and landed on OpenRouter for free access. Qwen3.6-35B-A3B, released April 16, is still fully open-source on Hugging Face under Apache 2.0 and runs on consumer hardware with 24GB of RAM.
Max is different. The weights stay with Alibaba. Developers get API access through Qwen Studio or Alibaba Cloud Model Studio - that's it. You can route traffic to qwen3.6-max-preview but you can't pull the model and run it yourself.
What the Tier Split Looks Like
The strategy is now clear: open-source at the mid tier, closed at the top. Qwen3.6-35B-A3B gives the developer community a capable open alternative. Max-Preview captures the enterprise and production workloads where performance matters more than deployment flexibility. Alibaba gets adoption data from the open tier and revenue from the closed tier.
This is the same playbook Meta adopted with Muse Spark earlier this month. It took longer to arrive at Alibaba, given Qwen's identity as the open challenger to Western proprietary labs, but the economics eventually won out.
Qwen Code Free Tier Gone
Qwen Code, Alibaba's coding-focused API product, dropped its free plan the same day Max-Preview launched. The coincidence is too clean to be coincidence. Free access seeded adoption; paid access now captures the value. Developers who built workflows on the free tier will need to either pay up or drop down to the 35B open model.
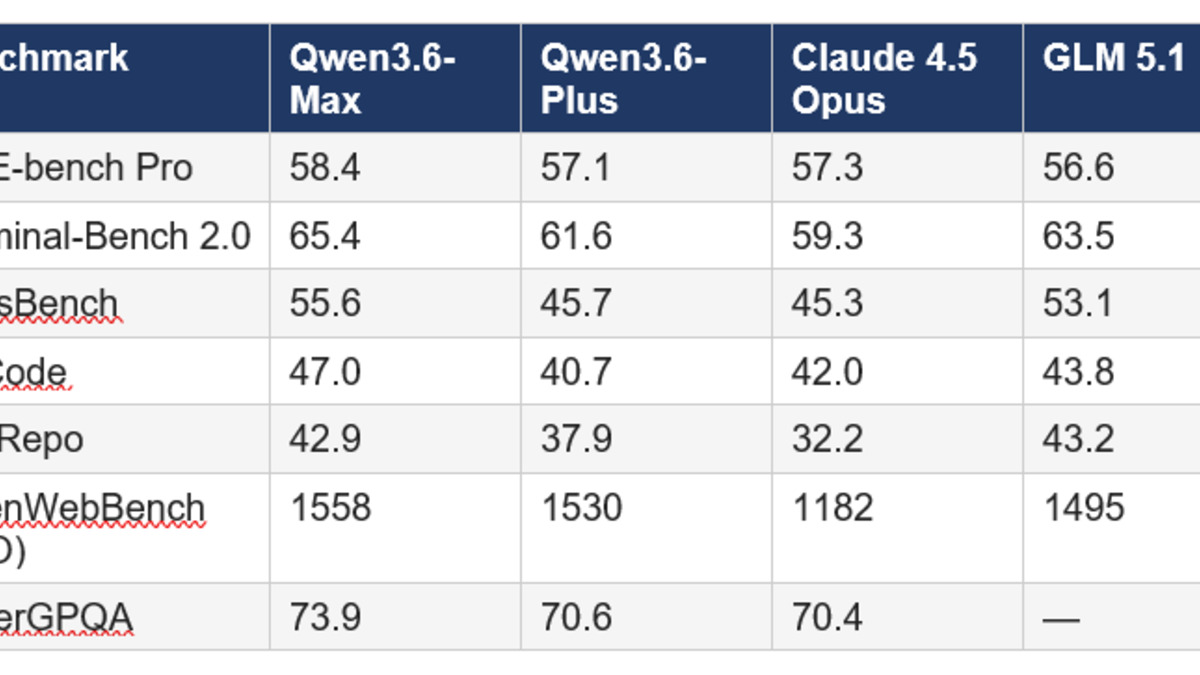 Qwen3.6-Max-Preview topped six major coding benchmarks including SWE-bench Pro and Terminal-Bench 2.0 on release day, April 20, 2026.
Source: buildfastwithai.com
Qwen3.6-Max-Preview topped six major coding benchmarks including SWE-bench Pro and Terminal-Bench 2.0 on release day, April 20, 2026.
Source: buildfastwithai.com
Benchmark Performance
Coding Benchmarks
The six benchmark wins paint a consistent picture: Qwen3.6-Max-Preview is the strongest available model for agentic coding tasks at the moment. The improvements over its predecessor Qwen3.6-Plus are not marginal:
| Benchmark | Improvement vs Qwen3.6-Plus |
|---|---|
| SkillsBench | +9.9 points |
| SciCode | +10.8 points |
| Terminal-Bench 2.0 | +3.8 points |
| QwenWebBench | New top score (ELO 1558) |
| SWE-bench Pro | Ranked first |
| NL2Repo | +5.0 points |
Kimi K2.6 dropped a day earlier with its own frontier-class coding claims. Two Chinese labs releasing flagship coding models within 24 hours of each other is striking. The open-weights race and the closed-API race are now running in parallel.
General Capabilities
The Artificial Analysis Intelligence Index score of 52 is composite - it covers reasoning, knowledge, mathematics, and coding. A score of 52 against a field median of 14 is a sizable gap. The model is explicitly reasoning-capable, with a preserve_thinking parameter that maintains chain-of-thought traces across multi-turn conversations, which matters for production agentic workflows where context continuity is critical.
One flag from the evaluation: Qwen3.6-Max-Preview generated 74M output tokens during assessment versus a field median of 24M. Verbosity at 3x the median isn't a disqualifier, but it does affect latency and token costs for anything in production. High verbosity in preview models sometimes gets dialed back post-launch; it's something to watch.
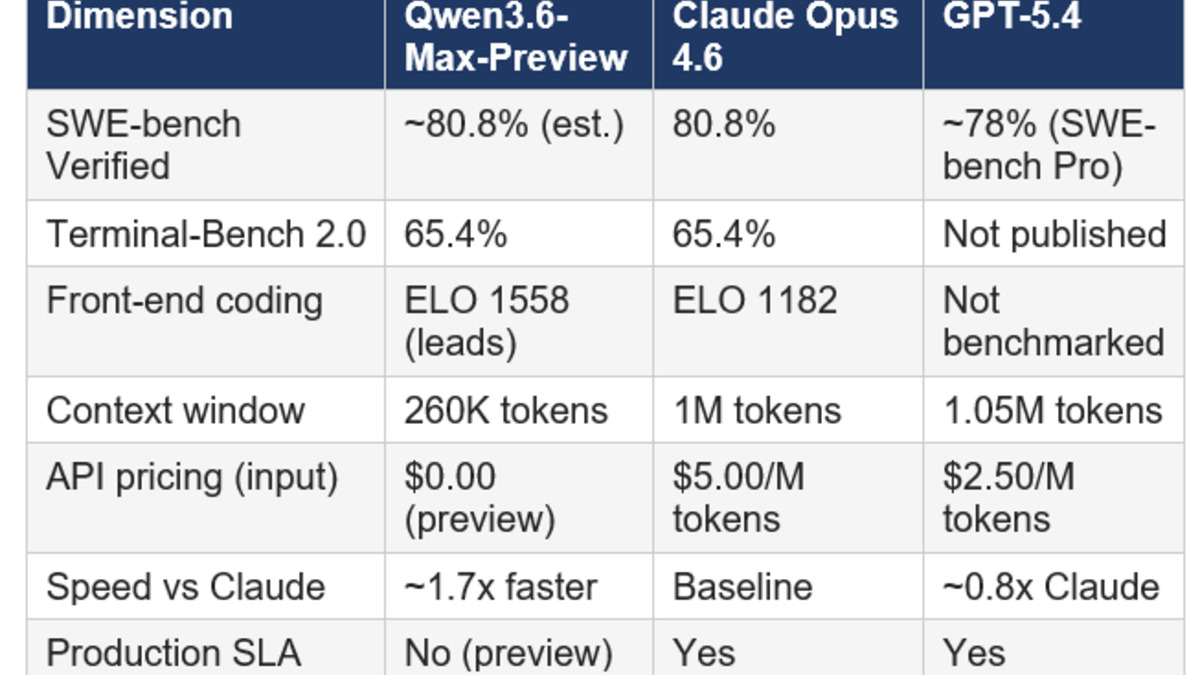 Qwen3.6-Max-Preview scored 52 on the Artificial Analysis Intelligence Index, placing it third among 203 evaluated models as of April 20, 2026.
Source: buildfastwithai.com
Qwen3.6-Max-Preview scored 52 on the Artificial Analysis Intelligence Index, placing it third among 203 evaluated models as of April 20, 2026.
Source: buildfastwithai.com
Under the Hood
Architecture and Context
Max-Preview is undisclosed-parameter, text-only at launch, with a 256k token context window - the same as Qwen3.6-Plus but substantially smaller than Plus's 1M context offering. Whether the context limit reflects a deliberate product choice or a pre-launch constraint isn't clear from the available information. For most agentic coding tasks, 256k is more than enough; for large codebase ingestion it's a step down from Plus.
The model has extended thinking capabilities built in. Chain-of-thought reasoning runs by default for complex queries, and the API exposes the full reasoning trace if you want to inspect it.
API Compatibility
The most immediately useful engineering detail: the qwen3.6-max-preview endpoint accepts both OpenAI chat-completions format and the Anthropic messages format. Teams already using either SDK can drop this in with a baseURL change and nothing else. This is getting more common among Chinese labs - GLM-5.1 and Kimi K2.6 both did the same - but it's still worth calling out because it meaningfully lowers the switching cost.
Access is through Qwen Studio (chat interface) and Alibaba Cloud Model Studio (production API). There's no third-party availability announced yet; OpenRouter or Fireworks access would expand reach to developers who don't want Alibaba Cloud accounts.
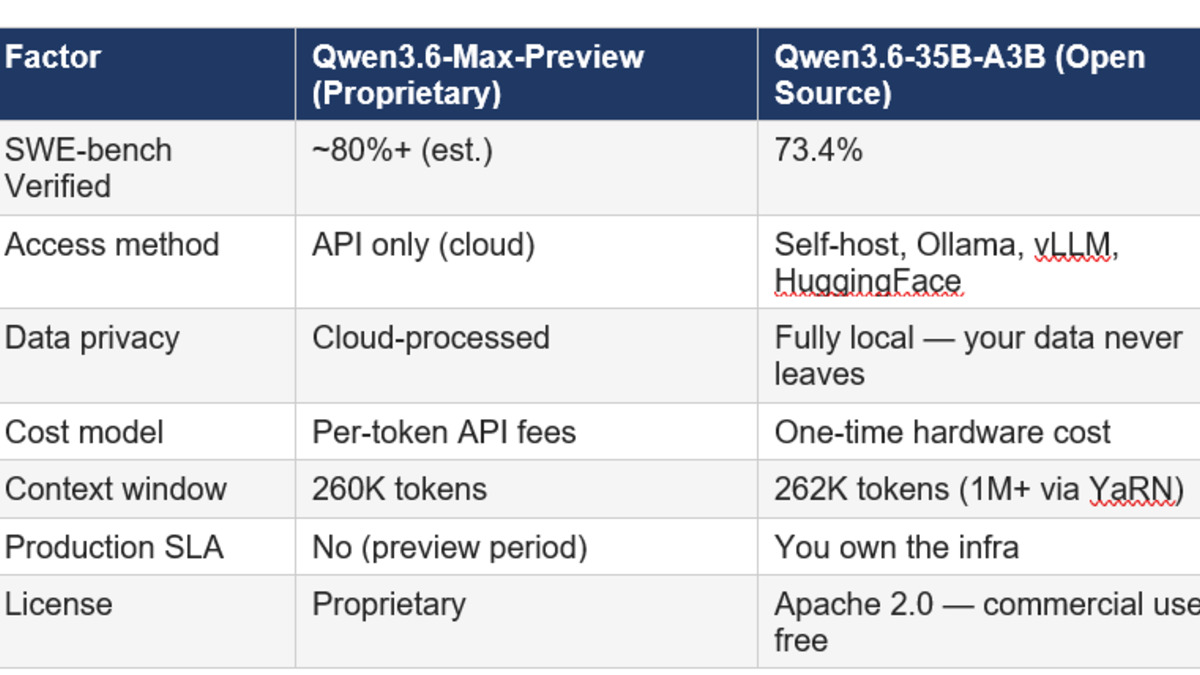 Alibaba now runs a tiered strategy: Qwen3.6-35B-A3B stays open-source on Hugging Face; the Max-Preview flagship is API-only with no weight release.
Source: buildfastwithai.com
Alibaba now runs a tiered strategy: Qwen3.6-35B-A3B stays open-source on Hugging Face; the Max-Preview flagship is API-only with no weight release.
Source: buildfastwithai.com
What To Watch
Pricing disclosure. The model is labeled "preview" and current evaluation costs show $0.00 per token, but that's preview pricing and will change. Production pricing hasn't been announced, and without it, cost comparisons against Claude Opus 4.7 or GPT-5.4 are incomplete. For enterprise teams evaluating this seriously, the rate card matters as much as the benchmark.
Data residency. Routing customer data through Alibaba Cloud Model Studio creates compliance questions for US and EU deployments that didn't exist when you could self-host the weights. Legal review is required before pointing client-data production traffic at this endpoint. The GDPR exposure is real.
Verbosity in production. Three times the output tokens at equivalent quality is a latency and cost problem at scale. If Alibaba doesn't tune this down between preview and GA, it'll hurt the model's competitiveness on high-throughput workloads despite the benchmark scores.
The trend line. Alibaba joining Meta in closing the frontier tier changes what "Chinese open source" means. Qwen3.6-35B-A3B remains truly open, and it's a strong model. But the gap between what's open and what's best just widened. Leaderboards tracking open-source model performance will need to treat the Max tier as a proprietary model from now on, not an open one.
Sources: Qwen3.6-Max-Preview review and benchmarks - buildfastwithai.com | Qwen3.6-Max closed-weights pivot analysis - digitalapplied.com | Alibaba drops Qwen3.6-Max-Preview - decrypt.co | Artificial Analysis Intelligence Index - artificialanalysis.ai | CnTechPost: Qwen3.6-35B-A3B open source release - cntechpost.com | Qwen3.6-Max vs Kimi K2.6 comparison - lushbinary.com
