AI Scrapers Are DDoSing Self-Hosted GitLab Servers
AI training crawlers from Anthropic, Google, and OVHcloud knocked a French national research institute's GitLab server offline for hours - nobody at CNRS's Institute of Complex Systems could work.
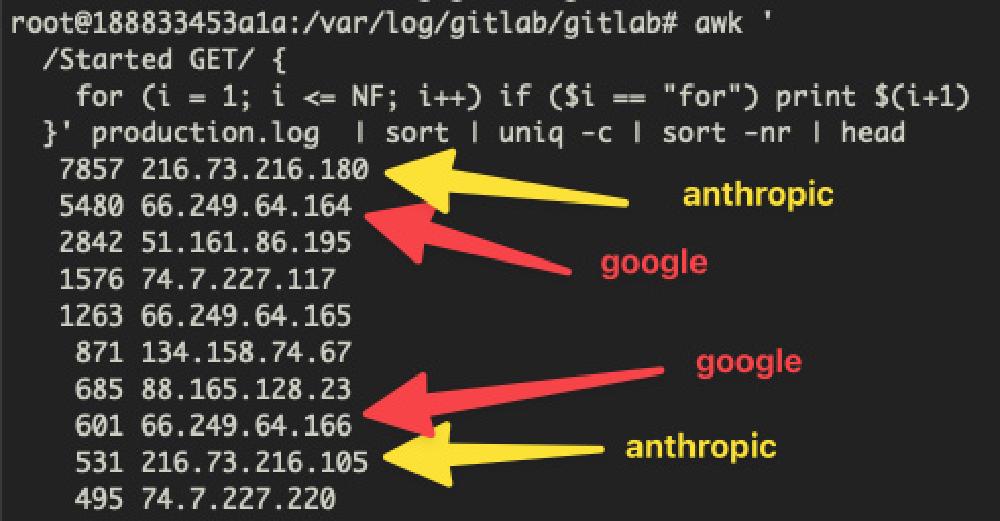
"Our local GitLab server has been under attack by @AnthropicAI, @Google, @OVHcloud and more! These companies have been hammering our GitLab server, trying to scrape every Haskell commit we made in our lab, resulting in the whole server becoming unresponsive!"
- Maziyar Panahi, Big Data Engineer at CNRS (French National Centre for Scientific Research)
The GitLab server that went down was not a personal side project. It serves the entire Institute of Complex Systems of Paris (ISCPIF), a research lab within CNRS - France's largest public research organization. AI training crawlers from Anthropic, Google, and OVHcloud scraped every Haskell commit in the institute's repositories, producing enough request volume to knock the server offline for hours. Nobody at the institute could work. This is not a sophisticated attack. It's a brute-force crawl by companies that should know better.
Impact Assessment
| Stakeholder | Impact | Timeline |
|---|---|---|
| Research institutions (CNRS/ISCPIF) | Hours of lost work across entire institute | Immediate |
| Open source infrastructure | Bandwidth costs, maintainer burden | Escalating since 2025 |
| AI companies (Anthropic, Google) | Reputational damage, potential access blocks | Immediate |
| FOSS community | Infrastructure strained by parasitic crawling | Systemic |
The Incident
Panahi - who has over 16 years in public research at CNRS, led the team behind John Snow Labs' Spark NLP (the most widely used enterprise NLP library), and founded OpenMed for open-source medical AI - manages the institute's infrastructure. His access logs tell the story: bots identified as belonging to Anthropic, Google, and OVHcloud hammered the server with requests targeting every commit in the repository's Haskell codebase. One community member who analyzed similar logs reported 283 successful requests versus 3,607 blocked requests through nftables and nginx protections - meaning the defensive infrastructure caught most of the traffic, but the sheer volume still degraded performance.
The scraping wasn't targeted at a specific file or branch. It was an exhaustive crawl of the entire commit history - every diff, every file version, every commit message. For a GitLab instance serving an entire research institute, that volume of requests is indistinguishable from a denial-of-service attack. Researchers across the institute lost access to their repositories for hours.
This Is Not an Isolated Case
The GNOME project - one of the largest open-source desktop environments - has been fighting the same battle. GNOME sysadmin Bart Piotrowski shared that only 3.2% of requests to their GitLab instance (2,690 out of 84,056) passed their challenge system. The remaining 97% was automated bot traffic, primarily from AI companies.
GNOME has deployed two layers of defense:
- Anubis - an open-source Web AI Firewall that uses proof-of-work challenges to filter bots. Launched in January, it has been downloaded nearly 200,000 times and is used by GNOME, FFmpeg, and UNESCO
- Fastly - GNOME migrated to Fastly's edge bot management (sponsored via Fastly's Fast Forward program) to offload mitigation before traffic reaches their servers
Some open-source projects have resorted to blocking entire countries to manage the crawler load. The situation prompted 404 Media to report on Anubis as "the open-source software saving the internet from AI bot scrapers."
Companies Involved
Simon Willison, developer and AI commentator, responded to Panahi's post:
"This is poor form Anthropic and especially from Google - crawlers really need to get better at not overloading applications like self-hosted GitLab. There are a ton of misbehaving crawlers out there these days, but I'd hope the big players at least could do better than this."
The criticism highlights an asymmetry: Anthropic doesn't publish IP addresses for its crawlers, making it nearly impossible to verify traffic claiming to be from Claude's training infrastructure. Google at least publishes its crawler IPs, but the crawlers themselves don't respect the capacity of small self-hosted instances.
OVHcloud's involvement suggests that some scraping is done from rented cloud infrastructure rather than the AI companies' own networks, making attribution harder and blocking less precise.
What Happens Next
For Self-Hosted Admins
The Hacker News discussion surfaced several defensive strategies:
- Block HTTP/1.x traffic - Most legitimate users connect via HTTP/2.0 or higher; blocking lower versions filters out the majority of bots outside headless Chrome
- Require SSH for repository access - Restrict git clone/fetch to SSH clients, removing web-based scraping completely
- Deploy Anubis - The proof-of-work challenge system is specifically designed for this threat
- CIDR block management - Maintain blocklists of known AI crawler IP ranges at the firewall level
For the AI Companies
The pattern is unsustainable. AI companies are training on open-source code while simultaneously degrading the infrastructure that hosts it. If enough self-hosted instances go behind authentication walls or Anubis challenges, the accessible training data shrinks - which hurts the very models the crawlers are feeding.
Google and Anthropic have the engineering talent to build rate-limited, respectful crawlers that check robots.txt, honor Crawl-delay directives, and adapt request rates to server response times. The fact that they haven't done so for self-hosted GitLab instances is a choice, not a limitation.
A French national research institute's GitLab server went down - taking an entire lab's productivity with it for hours - because Anthropic and Google wanted its Haskell commits. That sentence should be embarrassing for companies that collectively employ thousands of engineers and have raised tens of billions of dollars. The open-source infrastructure that AI companies depend on for training data is being degraded by the very process of collecting that data. GNOME's 97% bot traffic ratio is the number that should concern everyone building on open-source foundations. The crawlers are eating the commons.
Sources:
- Maziyar Panahi on X - GitLab Server Under Attack
- Simon Willison on X - Criticism of Anthropic and Google
- Hacker News Discussion Thread
- GNOME Infrastructure Now Battling Bots Using Fastly - Phoronix
- FOSS Infrastructure Is Under Attack by AI Companies - OSnews
- The Open-Source Software Saving the Internet From AI Bot Scrapers - 404 Media
- Anubis - GitHub

