Wan 2.7
Alibaba's open-source video generation model with MoE architecture, native audio, first-and-last-frame control, and 1080p output up to 15 seconds.

Wan 2.7 is Alibaba's Tongyi Lab's latest open-source video generation model, released in April 2026 as both a hosted cloud service and an open-weight download under Apache 2.0. It sits at rank 4 on the Artificial Analysis Image-to-Video leaderboard (with audio), holding an Elo of 1,090 - just three points behind Google's Veo 3.1 at 1,087, while costing a fraction of the price.
TL;DR
- Open-source video generation (Apache 2.0): 27B-parameter MoE model, 14B active per pass, 1080p up to 15 seconds
- API pricing at $0.10/s on fal.ai; weights available on HuggingFace and ModelScope
- Ranks 4th on Artificial Analysis Image-to-Video (with audio) leaderboard at Elo 1,090, edging out Veo 3.1 (1,087)
Wan 2.7 covers four distinct video workflows in a single release: text-to-video, image-to-video with first-and-last-frame control, reference-to-video with character and voice cloning, and instruction-based video editing. That breadth in an Apache 2.0 package is what makes it notable. Closed models like Veo 3.1 and Sora 2 lead on individual quality axes, but neither is self-hostable, and neither costs $0.10 per second.
The model is the fifth generation in Alibaba's Wan series. Wan 2.1 (February 2025) established the base, Wan 2.2 introduced the MoE diffusion transformer, Wan 2.6 added multi-shot narrative and extended duration to 15 seconds, and Wan 2.7 brings native 1080p output, Thinking Mode, voice cloning, and improved motion smoothness.
Key Specifications
| Specification | Details |
|---|---|
| Provider | Alibaba (Tongyi Lab) |
| Model Family | Wan Video |
| Parameters | 27B total, 14B active (MoE) |
| Context Window | N/A (video generation) |
| Output Resolution | 720p and 1080p |
| Max Duration | 15 seconds |
| Aspect Ratios | 16:9, 9:16, 1:1, 4:3, 3:4 |
| Output Price | $0.10/s of video (fal.ai) |
| Release Date | April 6, 2026 |
| License | Apache 2.0 |
Benchmark Performance
Wan 2.7 sits at rank 4 on the Artificial Analysis Image-to-Video leaderboard (with audio category) with an Elo score of 1,090. Scores come from blind pairwise comparisons: a user sees two videos side by side, doesn't know which model produced which, and picks a winner. Elo updates from those votes.
| Rank | Model | Creator | Elo | API Price |
|---|---|---|---|---|
| 1 | Dreamina Seedance 2.0 720p | ByteDance Seed | 1,194 | $9/min |
| 2 | HappyHorse-1.1 | Alibaba-ATH | 1,121 | $9/min |
| 3 | grok-imagine-video-1.5-preview | xAI | 1,111 | $8/min |
| 4 | Wan 2.7 | Alibaba | 1,090 | $6/min ($0.10/s) |
| 5 | HappyHorse-1.0 | Alibaba-ATH | 1,089 | $13/min |
| 6 | Veo 3.1 | 1,087 | $24/min |
Source: Artificial Analysis Image-to-Video Leaderboard (With Audio), June 2026
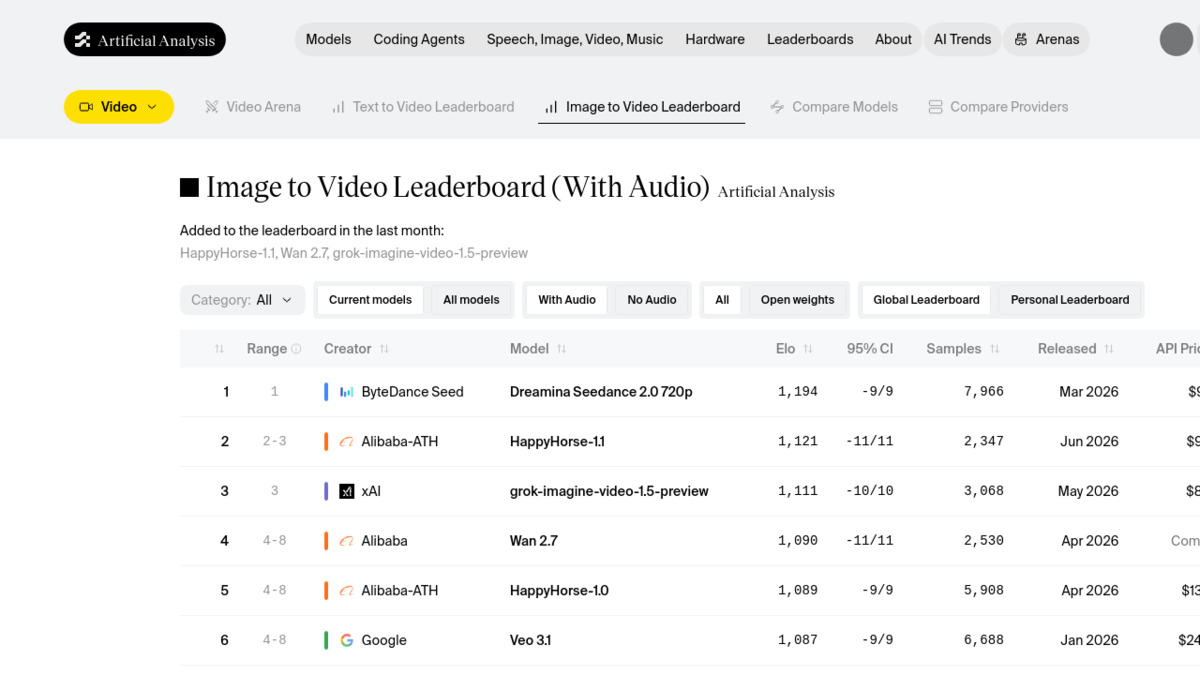 Wan 2.7 holds 4th place on the Artificial Analysis Image-to-Video (With Audio) leaderboard as of June 2026, ahead of Veo 3.1 at a fraction of the cost.
Source: artificialanalysis.ai
Wan 2.7 holds 4th place on the Artificial Analysis Image-to-Video (With Audio) leaderboard as of June 2026, ahead of Veo 3.1 at a fraction of the cost.
Source: artificialanalysis.ai
The benchmark position deserves some context. Wan 2.7's Elo of 1,090 reflects the image-to-video (with audio) category only. It hasn't been added to the text-to-video arena yet. The leaderboard also weights audio synthesis heavily, which is one of Wan 2.7's genuine strengths. Users who only need silent video should run their own comparisons rather than relying on this ranking alone.
Key Capabilities
Architecture: MoE Diffusion Transformer
The 27B model uses a Mixture-of-Experts diffusion transformer where only 14B parameters activate per inference pass. The two-expert design assigns a high-noise expert to early denoising stages (handling overall layout and composition) and a low-noise expert to later refinement stages (sharpening detail and aesthetics). The switch between them happens automatically based on the signal-to-noise ratio threshold during diffusion.
This isn't the first MoE video model - Wan 2.2 introduced the same architecture in mid-2025. Wan 2.7 extends it with improved attention mechanisms and a longer effective prompt window. The result is better prompt adherence at high noise levels and more stable fine detail at low noise levels compared to 2.2.
Thinking Mode
Before creating frames, Thinking Mode runs a planning pass: the model interprets the prompt, maps out composition, camera movement, and pacing, then produces. Standard mode takes roughly 30-60 seconds for a 10-second clip. Thinking Mode adds 15-30 seconds on top. For simple prompts with clear subjects and camera moves, standard mode is fine. For complex multi-action scenes with specific spatial requirements, Thinking Mode measurably reduces subject drift and incoherent motion.
First-and-Last-Frame Control
The first-and-last-frame mode (FLF2V) accepts a start image and an end image. The model produces the transition between them. This is useful for product shots where you want a specific opening and closing frame, or for chaining clips where the last frame of one clip becomes both the "last" reference of an old clip and the "first" of the next. The best frame pairs share consistent light direction, matching depth of field, and a subject that's spatially plausible in both positions.
Reference-to-Video and Voice Cloning
The reference-to-video pipeline accepts up to five reference materials (images or short video clips). It locks each character's visual appearance across camera angles and lighting changes, and it clones their voice from a 1-10 second sample. Multi-speaker scenes with stable vocal timbre are supported. This is the most technically ambitious feature of Wan 2.7 and the most variable in quality - results degrade when reference images are inconsistent in lighting or angle.
Native Audio
Audio is generated jointly with the video, not added as a post-processing step. Background music, ambient sound, and character vocals are synchronized to the visual output timing. The system doesn't require separate audio prompts - it infers appropriate sound from the video content and text prompt. You can also preserve audio from an input video when using instruction-based editing.
 The Wan 2.7 Image-to-Video playground on fal.ai. The API supports JavaScript and Python SDKs with pay-per-second billing.
Source: fal.ai
The Wan 2.7 Image-to-Video playground on fal.ai. The API supports JavaScript and Python SDKs with pay-per-second billing.
Source: fal.ai
Pricing and Availability
Wan 2.7 is available through several hosted APIs. The fal.ai endpoint charges $0.10 per second of produced video - a 10-second 1080p clip costs $1.00, with no minimums or subscriptions. Some other platforms charge $0.15/s. Wan 2.7 isn't yet listed on all API aggregators; fal.ai and Alibaba Cloud's DashScope are the most reliably maintained endpoints today.
For self-hosting, the weights are available on HuggingFace and Alibaba's ModelScope under Apache 2.0. The minimum practical configuration is 16GB VRAM; 24GB is recommended for an usable workflow at 1080p. Community-contributed GGUF quantizations are available for sub-16GB setups, with the usual quality trade-offs from quantization. CPU inference is technically possible but generates a 5-second clip in hours.
Wan 2.7 is priced well below Veo 3.1 ($24/min, which works out to $0.40/s) and Sora 2 Pro. For high-volume video production where closed models are cost-prohibitive, Wan 2.7 is the most competitive open alternative right now. The open weights make it the only frontier-class video model that teams can self-host and fine-tune without a vendor relationship.
See our video generation benchmarks leaderboard for a full comparison of models across VBench and the Artificial Analysis arena. For a look at the open-source alternative for still image work, LTX-2.3 covers Lightricks' open 22B image model.
February 2025 - Wan 2.1 releases under Apache 2.0, establishing the series' open-source foundation.
July 2025 - Wan 2.2 introduces MoE diffusion transformer (A14B) in the first video model with that architecture.
Late 2025 - Wan 2.6 adds multi-shot narrative support, 15-second clip duration, and improved audio-visual synchronization.
April 6, 2026 - Wan 2.7 releases via Alibaba Cloud and fal.ai, adding Thinking Mode, FLF2V, voice cloning, native 1080p.
April 22, 2026 - Open weights made available on HuggingFace and ModelScope under Apache 2.0.
Strengths and Weaknesses
Strengths
- Open weights under Apache 2.0: self-hostable, fine-tunable, commercial use permitted
- Elo 1,090 on Artificial Analysis Image-to-Video (with audio) - fourth overall, ahead of Veo 3.1
- Four workflow modes in a single model: T2V, I2V, R2V (with voice cloning), and instruction-based editing
- $0.10/s API pricing is roughly 4x cheaper than Veo 3.1's $0.40/s
- First-and-last-frame control enables deterministic clip chaining
- Thinking Mode reduces prompt drift on complex multi-action scenes
- 15-second maximum duration and multi-shot support for longer narratives
Weaknesses
- 16-24GB VRAM minimum for local inference limits self-hosting to well-specced machines
- Voice cloning and multi-subject reference quality degrades with inconsistent input images
- Not benchmarked on text-to-video arena yet - rank 4 is image-to-video only
- Open weights arrived about two weeks after the API release, with no published roadmap
- Closed competitors like Veo 3.1 lead on phoneme-accurate lipsync and 4K output
Related Coverage
- Video Generation Benchmarks Leaderboard - full model rankings across VBench and Artificial Analysis
- Veo 3.1 - Google's competing video model, higher per-second cost, leads on lipsync
- LTX-2.3 - Lightricks' open 22B image model for comparison in the open-source video space
FAQ
What is Wan 2.7's Elo score?
Wan 2.7 holds an Elo of 1,090 on the Artificial Analysis Image-to-Video (With Audio) leaderboard as of June 2026, placing it 4th overall ahead of Veo 3.1 (1,087).
How much does Wan 2.7 cost per second?
fal.ai charges $0.10 per second of generated video. A 10-second 1080p clip costs $1.00. No subscription required.
Can I run Wan 2.7 locally?
Yes. Weights are on HuggingFace and ModelScope under Apache 2.0. You need at least 16GB VRAM; 24GB is recommended for 1080p. GGUF quantizations exist for lower-VRAM setups.
What is Thinking Mode in Wan 2.7?
Thinking Mode adds a planning pass before generation: the model reads the prompt, plans composition and camera movement, then renders. It adds 15-30 seconds to generation time but reduces drift on complex multi-action scenes.
How does first-and-last-frame control work?
You provide both a start image and an end image. The model generates the motion between them. Best results come from frame pairs with consistent lighting direction and spatially plausible subject positions.
What is Wan 2.7's license?
Apache 2.0. Commercial use, modification, and distribution are permitted without a separate licensing agreement.
Sources:
- Wan 2.7 on fal.ai
- Alibaba Launches Wan 2.7 - FinancialContent
- What Is Wan 2.7 - MindStudio
- Artificial Analysis Image-to-Video Leaderboard
- Wan 2.7 Release Date and Open Source
- Wan 2.7 Open Source Guide
- WAN 2.7 vs WAN 2.6 Feature Diff - WaveSpeed
- Wan 2.7 First and Last Frame Guide - WaveSpeed
- Wan 2.7 API Collection - Atlas Cloud
- Wan 2.7 Review - SeaArt
✓ Last verified June 24, 2026
