Voxtral TTS
Mistral's first open-weight text-to-speech model: 4B parameters, 70ms latency, voice cloning from 3 seconds of audio, and a 68.4% win rate over ElevenLabs Flash v2.5 in blind tests.

Mistral's Voxtral TTS is the company's first text-to-speech model, and it lands with two things most TTS releases don't offer together: competitive benchmark numbers and open weights you can run yourself. Released on March 23, 2026 under CC BY-NC 4.0, the 4B parameter model targets the same voice-agent and narration workloads where ElevenLabs and OpenAI dominate, but it does so at a price point that undercuts both and with a self-hosting path that neither offers.
TL;DR
- Open-weight TTS model with zero-shot voice cloning from as little as 3 seconds of reference audio
- 4B parameters, 70ms time-to-first-audio on H200, $16/M characters via API or free to self-host (CC BY-NC 4.0)
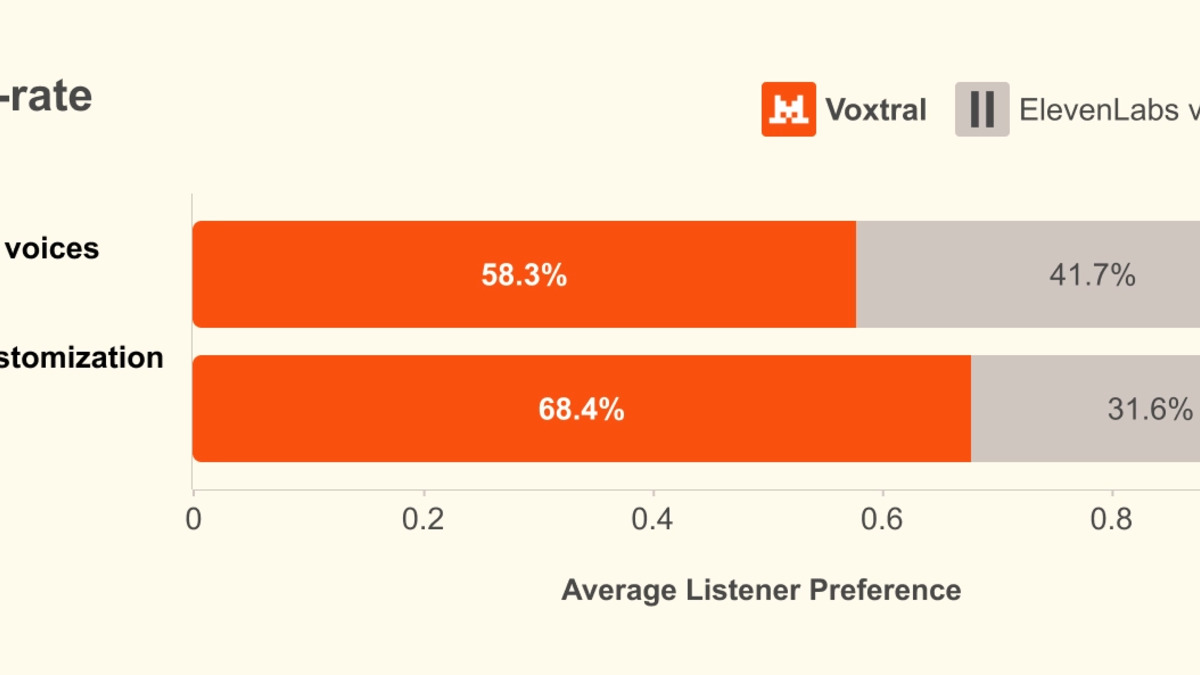
- 68.4% win rate over ElevenLabs Flash v2.5 in blind human tests across 9 languages; parity with ElevenLabs v3 on quality
The model architecture is a three-stage pipeline. A 3.4B-parameter transformer decoder backbone based on Ministral 3B produces semantic tokens from text and voice input. A 390M-parameter flow-matching acoustic transformer converts those tokens into continuous audio representations. A 300M-parameter neural audio codec - built from scratch by Mistral - handles the final audio encoding at 12.5 Hz with 80ms frames and a 2.14 kbps bitrate. The codec uses a 8,192-size VQ codebook for semantic tokens and 36 acoustic dimensions with finite scalar quantization.
Key Specifications
| Specification | Details |
|---|---|
| Provider | Mistral AI |
| Model Family | Voxtral |
| Parameters | 4B (3.4B backbone + 390M acoustic + 300M codec) |
| Context Window | 4K tokens |
| Supported Languages | 9 (English, French, German, Spanish, Dutch, Portuguese, Italian, Hindi, Arabic) |
| Input Price | $16.00/M characters |
| Output Price | $16.00/M characters |
| Self-Hosted | Free (CC BY-NC 4.0) |
| Model ID (API) | voxtral-mini-tts-2603 |
| Release Date | 2026-03-23 |
| License | CC BY-NC 4.0 (open weights); commercial use requires separate agreement |
| VRAM (self-hosted) | 16 GB min (BF16); ~3 GB with quantization |
Benchmark Performance
Mistral used human preference evaluations across 9 languages with native-speaker annotators, comparing Voxtral TTS against ElevenLabs Flash v2.5 (its primary competitor at similar latency) and ElevenLabs v3 (the premium tier). All benchmark data is self-reported; no independent third-party evaluations have been published yet.
| Evaluation | Voxtral Win Rate |
|---|---|
| Zero-shot voice cloning vs. ElevenLabs Flash v2.5 | 68.4% |
| Preset voices vs. ElevenLabs Flash v2.5 | 58.3% |
| Spanish (voice cloning) | 87.8% |
| Hindi (voice cloning) | 79.8% |
| Arabic (voice cloning) | 72.9% |
| Dutch (voice cloning) | 49.4% |
| Quality vs. ElevenLabs v3 | Parity (per Mistral's eval) |
 Voxtral TTS human preference win rates per language, from Mistral's official release data.
Source: mistral.ai
Voxtral TTS human preference win rates per language, from Mistral's official release data.
Source: mistral.ai
The 68.4% figure comes from zero-shot voice cloning tests where Voxtral gets strongest - the model generalizes across unknown voices better than a system trained primarily on fixed speaker styles. The Dutch result at 49.4% is worth noting: below 50% means the model loses on that language pair. For anyone building Dutch-language applications, ElevenLabs currently wins.
Automatic metrics from the research paper: WER ranges from 0.63% to 4.99% across languages, with a reported micro-average of 1.59% on the MiniMax dataset. UTMOS-v2 naturalness scores range from 2.83 to 4.30 depending on language. Speaker similarity (cosine) hits 0.587 to 0.839. These are solid numbers - ElevenLabs Flash v2.5 beats Voxtral on most automated metrics, but the human preference direction reverses.
Key Capabilities
The core feature distinguishing Voxtral from other open-source TTS options is voice cloning quality. The model adapts to a reference voice using as little as 3 seconds of audio, though 5-25 seconds gives better results. It captures accent, inflection, intonation, and speech irregularities - including disfluencies like hesitations. Mistral calls this "voice-as-instruction": the reference clip implicitly sets tone and emotional delivery without requiring emotion tags in the input text.
Cross-lingual voice transfer is supported. You can apply a French speaker's accent to German-language output, or clone an Arabic voice and create English speech through it. This makes the model practical for dubbing and real-time translation workflows where speaker identity needs to stay consistent across language boundaries.
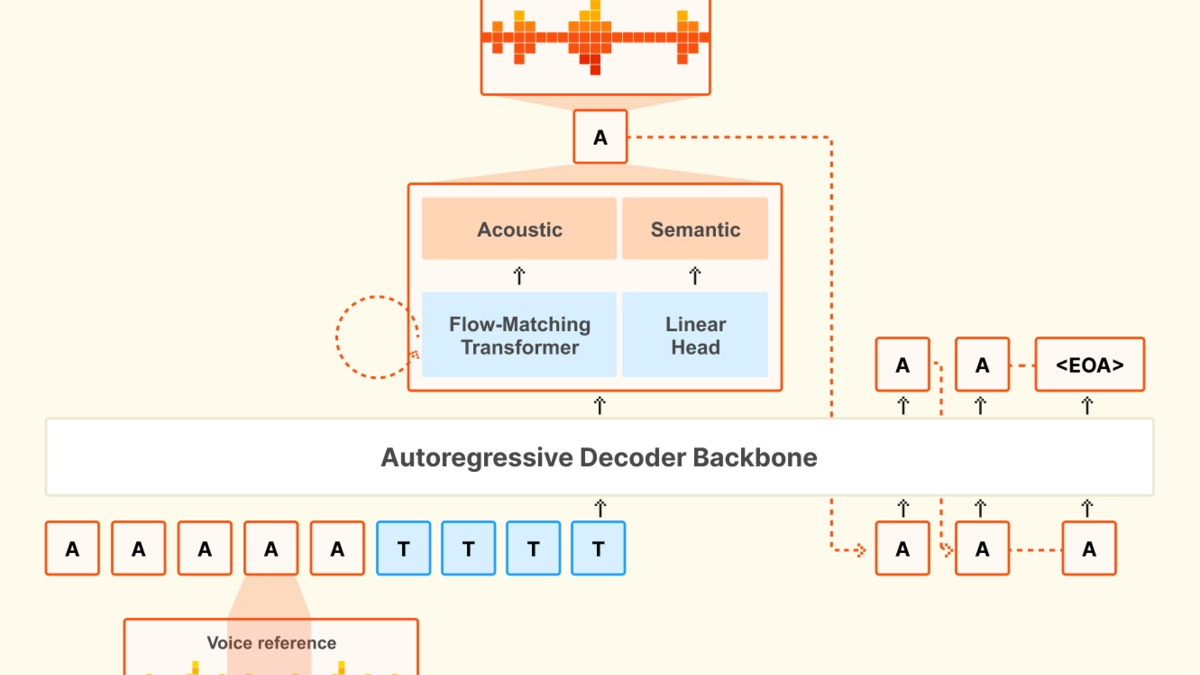 Voxtral's three-component architecture: decoder backbone, flow-matching acoustic transformer, and neural audio codec.
Source: mistral.ai
Voxtral's three-component architecture: decoder backbone, flow-matching acoustic transformer, and neural audio codec.
Source: mistral.ai
Latency on Mistral's cloud API runs around 90ms TTFA in practice (the 70ms figure is model-only latency on a H200 measured at 500 characters with a 10-second reference clip). The real-time factor is about 0.302 for the model itself, meaning a 10-second audio clip renders in about 3 seconds end to end. Maximum generation length per request is capped at two minutes, with "smart interleaving" available for longer documents. Output formats include MP3, WAV, PCM, FLAC, and Opus.
For self-hosting, inference runs via vLLM-Omni 0.18.0+ using the --omni flag. The BF16 weights on Hugging Face are 8 GB; quantized versions bring this down to roughly 3 GB. You need at least 16 GB VRAM for the full BF16 model. A single H200 handles 1,430 characters per second at 32 concurrent users, which covers most small-scale production deployments.
Voxtral appears in our best open-source TTS models roundup with Kokoro, Chatterbox, and Fish Speech - read that for a hardware-focused comparison of your self-hosting options.
Pricing and Availability
The API is available via Mistral's platform and through OpenRouter at a flat $16 per million characters. There's a free tier. At that rate, Voxtral matches Google Cloud Neural2 and Amazon Polly Neural pricing and undercuts ElevenLabs' developer tiers significantly - ElevenLabs runs $25-110 per million characters depending on tier.
The open-weight version is on Hugging Face at mistralai/Voxtral-4B-TTS-2603 under CC BY-NC 4.0. Non-commercial use is free. Commercial self-hosting requires a separate agreement with Mistral. This is the only major Mistral 2026 release not under Apache 2.0 - an unusual licensing choice given the company's open-source positioning.
Our Voxtral TTS review covers the full hands-on results including audio quality samples and a practical latency test on consumer hardware.
For comparison, Gemini 3.1 Flash TTS covers over 70 languages and offers more than 200 inline audio tags - it's the right pick if language breadth matters more than open weights. Voxtral's 9-language coverage is its clearest weakness against that model.
Strengths
- Zero-shot voice cloning from 3-25 seconds of audio with competitive naturalness
- Self-hostable open weights, 16 GB VRAM minimum
- 68.4% human preference win rate over ElevenLabs Flash v2.5 in voice cloning tests
- CC BY-NC 4.0 license - free for non-commercial use
- Cross-lingual voice transfer: clone one accent, produce in a different language
- API pricing matches mid-tier cloud TTS, undercuts ElevenLabs by 60-80%
Weaknesses
- Only 9 languages, versus 70+ for ElevenLabs and Google
- All benchmark data is self-reported; no independent evaluation yet
- Dutch performance below ElevenLabs Flash v2.5 (49.4% win rate)
- CC BY-NC 4.0 commercial restriction - unusual for a "open" model
- Max 2-minute generation per request limits long-form narration use cases
- vLLM-Omni dependency adds infrastructure complexity for self-hosting
FAQ
What languages does Voxtral TTS support?
Nine: English, French, German, Spanish, Dutch, Portuguese, Italian, Hindi, and Arabic. ElevenLabs supports 70+ languages, making Voxtral a stronger pick for targeted European and South Asian deployments rather than global coverage.
Can I run Voxtral TTS locally?
Yes, on a GPU with at least 16 GB VRAM using vLLM-Omni 0.18.0+. Quantized versions fit in roughly 3 GB. The license is CC BY-NC 4.0, so commercial use requires a separate agreement with Mistral.
How does the 68.4% win rate compare to ElevenLabs?
That figure is from Mistral's own blind listening tests comparing Voxtral voice cloning against ElevenLabs Flash v2.5. It's a self-reported number - no independent audit exists yet. On preset voices the win rate drops to 58.3%. The Dutch language result (49.4%) means Voxtral loses that head-to-head.
What is the time-to-first-audio latency?
70ms is the model-only latency on H200 hardware for a 500-character input with a 10-second voice reference. In practice, API TTFA is closer to 90ms including network overhead. End-to-end generation of a 10-second audio clip takes roughly 1.5-2 seconds depending on format.
How does Voxtral TTS compare to Gemini 3.1 Flash TTS?
Voxtral is open-weight and cheaper per character; Gemini 3.1 Flash TTS covers more than 70 languages and offers 200+ inline emotion tags. If you need self-hosting or 9-language zero-shot voice cloning, Voxtral wins. If you need broad language coverage or fine-grained emotion control, Gemini wins.
Does Voxtral support streaming?
Yes, the API supports streaming with roughly 90ms TTFA. PCM format delivers the first audio faster (around 800ms total) than MP3 (1.5-2 seconds), because PCM skips re-encoding.
Related Coverage
- Voxtral TTS Review: Mistral Takes On ElevenLabs
- Mistral Ships Voxtral - Open-Weights Voice AI Platform
- Best Open-Source TTS Models for Self-Hosting in 2026
- Gemini 3.1 Flash TTS
- AI Voice and Speech Leaderboard
Sources:
✓ Last verified June 17, 2026
