VibeThinker-3B
WeiboAI's 3B dense reasoning model fine-tuned from Qwen2.5-Coder-3B, posting AIME 2026 scores that match DeepSeek V3.2 (671B) using the Spectrum-to-Signal training pipeline.

VibeThinker-3B is a 3 billion parameter dense language model from WeiboAI, the AI research team at Sina Weibo. It's fine-tuned from Alibaba's Qwen2.5-Coder-3B base and trained via a four-stage post-training pipeline the authors call "Spectrum-to-Signal." The model targets verifiable reasoning - mathematics, competition coding, and STEM problems with deterministic answers - not general-purpose chat or knowledge retrieval.
TL;DR
- A 3B specialist for math and code reasoning, not a general-purpose model
- 64K context window, MIT license, fits in 6.7 GB VRAM at FP16
- AIME 2026 score of 94.3 matches DeepSeek V3.2 (671B) - but all scores are self-reported and await independent replication
The paper, submitted to arXiv on June 16, 2026, claims scores on math olympiad benchmarks that approach or match systems 200 times its size. VibeThinker-3B scored 94.3 on AIME 2026 (the same as DeepSeek V3.2's 94.2) and a 80.2 Pass@1 on LiveCodeBench v6. On recent LeetCode weekly and biweekly contests from late April through May 2026, it passed 123 of 128 first-attempt submissions - a 96.1% acceptance rate on unseen problems.
The catch, and it's an important one: every number here is self-reported from the authors' own evaluation harness. No independent lab has replicated these results at time of writing.
Key Specifications
| Specification | Details |
|---|---|
| Provider | WeiboAI (Sina Weibo) |
| Model Family | VibeThinker |
| Base Model | Qwen2.5-Coder-3B |
| Parameters | 3B |
| Context Window | 64K tokens |
| Max Output Tokens | 102,400 |
| Input Price | Free (open weights) |
| Output Price | Free (open weights) |
| Release Date | 2026-06-16 |
| License | MIT |
| VRAM (FP16) | ~6.7 GB |
| VRAM (INT4) | ~1.7 GB |
Benchmark Performance
All scores below are from the authors' technical report unless otherwise noted. No independent third-party replication has been published at time of writing.
| Benchmark | VibeThinker-3B | VibeThinker-3B + CLR | DeepSeek V3.2 (671B) | GPT-OSS (120B) | GLM-5 (744B) |
|---|---|---|---|---|---|
| AIME 2026 | 94.3 | 97.1 | 94.2 | 93.2 | 95.8 |
| HMMT 2025 | 89.3 | 95.4 | 90.2 | 90.0 | 97.9 |
| BruMO 2025 | 93.8 | 99.2 | 96.7 | - | - |
| IMO-AnswerBench | 76.4 | 80.6 | 78.3 | 75.6 | 82.5 |
| GPQA Diamond | 70.2 | 72.9 | 82.4 | 80.1 | 86.0 |
| LiveCodeBench v6 | 80.2 | - | 80.8 | 81.9 | 85.5 |
| IFEval | 93.4 | - | - | - | - |
| IFBench | 74.5 | - | - | - | - |
CLR = Claim-Level Reliability Assessment (test-time scaling method).
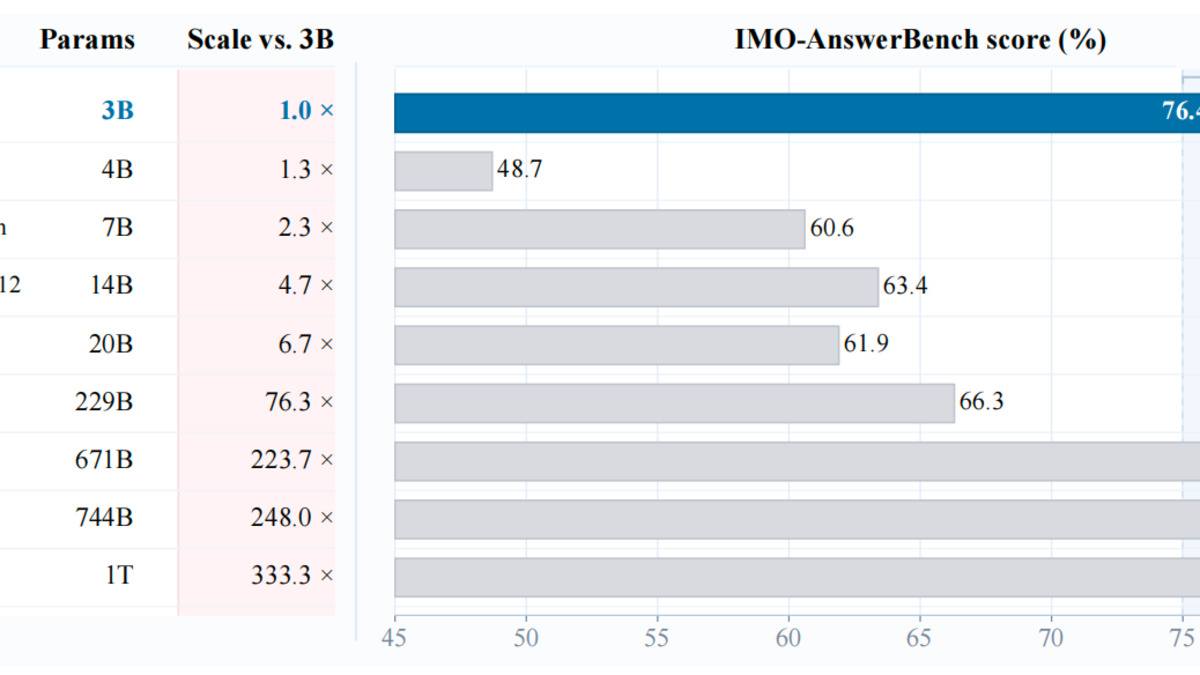 Accuracy and test-time scaling results from the VibeThinker-3B technical report.
Source: github.com/WeiboAI/VibeThinker
Accuracy and test-time scaling results from the VibeThinker-3B technical report.
Source: github.com/WeiboAI/VibeThinker
The math scores are competitive. On AIME 2026, the 3B model comes within 0.1 points of DeepSeek V3.2 and ahead of GPT-OSS. The gap is visible on GPQA Diamond - 70.2 versus 82.4 for DeepSeek V3.2 and 87.6 for Kimi K2.5. GPQA Diamond tests graduate-level science knowledge, not structured reasoning. A 3 billion parameter model simply can't store the breadth of factual coverage a 671B system carries. That trade-off is exactly what the authors argue is by design.
See our reasoning benchmarks leaderboard and coding benchmarks leaderboard for how VibeThinker-3B fits into the broader field.
Key Capabilities
The Spectrum-to-Signal pipeline has four stages. First, a curriculum-based two-stage supervised fine-tuning phase uses diversity-exploring distillation, where strong teacher models create multiple candidate reasoning traces per problem. The best traces are selected via n-gram deduplication, LLM quality scoring, and answer verification through code sandbox execution.
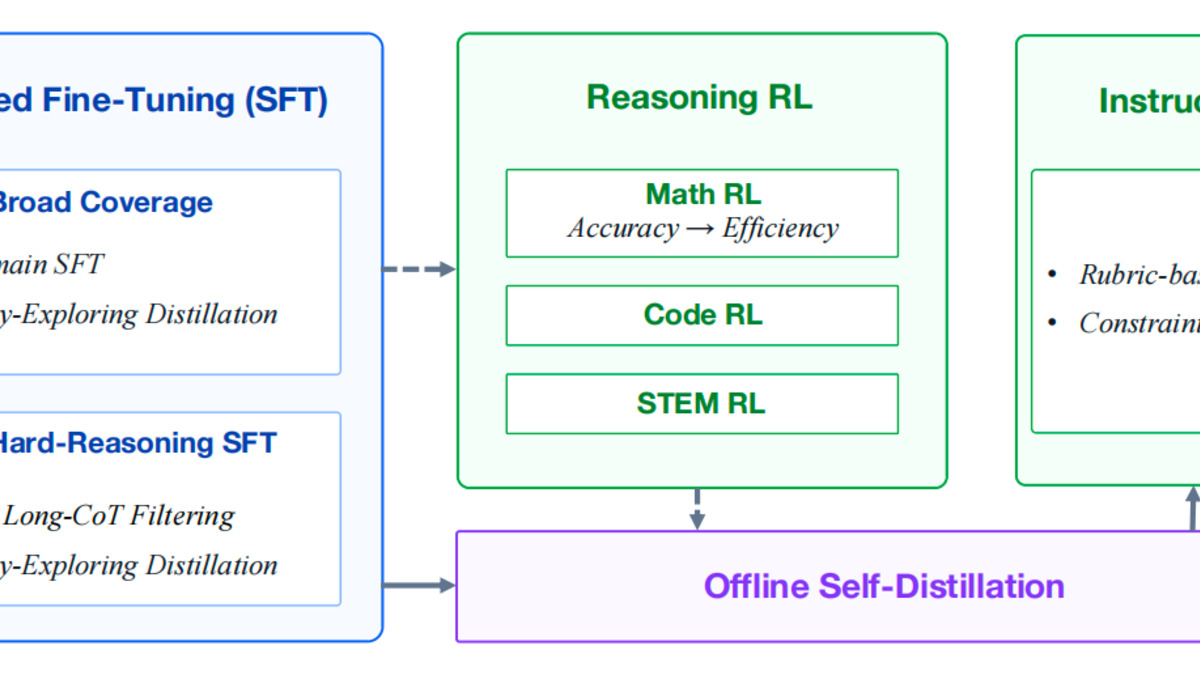 The Spectrum-to-Signal post-training architecture, showing the four pipeline stages.
Source: github.com/WeiboAI/VibeThinker
The Spectrum-to-Signal post-training architecture, showing the four pipeline stages.
Source: github.com/WeiboAI/VibeThinker
Second, multi-domain reinforcement learning using MaxEnt-Guided Policy Optimization (MGPO) trains the model across math, code, and science domains simultaneously. MGPO weights training examples by difficulty - focusing gradient updates on problems where the model succeeds sometimes but not always. The third stage, offline self-distillation, merges RL checkpoints to stabilize training gains. A final Instruct RL stage improves instruction controllability, pushing the IFEval score to 93.4.
The authors made one standout design choice: they rejected progressive context-window expansion (a common technique) for a fixed 64K window all through RL training. Their experiments showed that early truncation degrades long-chain reasoning. The model also includes a Long2Short math RL stage that redistributes rewards to favor shorter correct solutions, reducing token waste without accuracy loss.
The CLR test-time scaling method is worth understanding separately. It extracts five decision-relevant claims from each reasoning trajectory and computes a reliability score across them. On AIME 2026, CLR lifts the score from 94.3 to 97.1 - a significant jump without any change to the model weights.
The authors propose the "Parametric Compression-Coverage Hypothesis" to explain why the 3B model can match much larger systems on math and code while lagging on general knowledge. Their argument: verifiable reasoning compresses efficiently into compact parameter space because it relies on search and constraint satisfaction rather than fact storage. General knowledge, by contrast, requires broad parameter coverage to hold long-tail facts and domain-specific concepts.
Pricing and Availability
VibeThinker-3B is fully open weight under the MIT license. Weights are on HuggingFace at WeiboAI/VibeThinker-3B and training code is on GitHub. There's no API and no usage fee. GGUF quantized variants for local inference are available from community contributors including prithivMLmods.
Running locally requires roughly 6.7 GB VRAM in FP16 precision - within reach of a single consumer GPU. In INT4 quantization that drops to about 1.7 GB, making it viable on lower-end hardware. The model requires transformers>=4.54.0. For production throughput, vLLM 0.10.1 or SGLang 0.4.9 are the recommended inference backends.
Cloud deployment is available via Featherless AI at flat-rate pricing and Spheron's GPU recommender tracks compatible instance types. The community has also spun up inference endpoints, though these vary in availability.
Strengths and Weaknesses
Strengths
- Matches or approaches 671B-scale models on AIME, HMMT, and LiveCodeBench using a 200x smaller model
- MIT license with full weights and training code - no commercial restrictions
- 6.7 GB VRAM FP16 footprint runs on a single consumer GPU
- CLR test-time scaling provides significant accuracy gains without weight changes
- Strong instruction following (IFEval 93.4) relative to its size
Weaknesses
- All benchmark scores are self-reported; no independent replication at time of writing
- GPQA Diamond score of 70.2 trails large models by 12-17 points - general knowledge is a genuine gap
- No tool-calling or agent-based training; not suitable for function-calling workflows or autonomous coding agents
- OJBench score of 38.6 suggests limitations on harder competitive programming problems
- Community users report real-world gaps: some report the model lacks awareness of common developer tooling
Benchmark Skepticism
VibeThinker-3B landed during a period of heightened community skepticism about self-reported benchmarks. The term "benchmaxxing" - models optimized specifically for benchmark metrics rather than real-world utility - came up frequently in X discussions and the Hacker News thread (356 points). One user who tested the model directly noted it wasn't aware of common Python tooling that every other major model knows.
The authors' AIME 2026 setup uses their own evaluation harness and decoding settings, which means prompt formatting, sampling parameters, and test-time scaling choices can all influence scores. The jump from 94.3 to 97.1 with CLR scaling illustrates how much the reported number depends on configuration. These aren't necessarily signs of bad faith - benchmark methodology variation is common across labs - but they do mean the numbers should be treated as upper-bound indicators until copied.
Related Coverage
- Reasoning Benchmarks Leaderboard
- Small Language Model Leaderboard
- Math Olympiad AI Leaderboard
- Coding Benchmarks Leaderboard
- DeepSeek V3.2 Model Card (primary comparison model)
FAQ
What is VibeThinker-3B best at?
Math competition problems, structured STEM reasoning, and competitive programming. It isn't a general-purpose assistant and lacks tool-calling capability.
Can I run VibeThinker-3B locally?
Yes. It needs about 6.7 GB VRAM in FP16 or 1.7 GB in INT4 quantization. Requires transformers 4.54.0 or later. GGUF variants are available for llama.cpp.
Is VibeThinker-3B free to use commercially?
Yes. It's released under the MIT license, which permits commercial use, modification, and redistribution without restrictions.
How was WeiboAI's 3B model compared to DeepSeek V3.2 671B?
On AIME 2026, VibeThinker-3B scored 94.3 versus DeepSeek V3.2's 94.2. On GPQA Diamond (knowledge-heavy), DeepSeek V3.2 leads 82.4 to 70.2.
Are the benchmark scores independently verified?
No. All scores in the June 2026 technical report are self-reported from the authors' own evaluation harness. Independent replication hadn't been published now.
What is the Parametric Compression-Coverage Hypothesis?
The authors' proposed explanation for why small models can match large ones on reasoning: verifiable tasks compress into compact parameter space, while broad factual knowledge requires large parameter counts.
Sources
✓ Last verified June 23, 2026
