SubQ
SubQ is the first LLM built on a fully subquadratic attention architecture, achieving a 12M-token research context and 52x faster inference than FlashAttention at 1M tokens.

Subquadratic, a Miami-based startup, launched SubQ on May 5, 2026, with $29M in seed funding and a specific architectural claim: it has built the first frontier LLM where attention compute scales linearly with context length rather than quadratically. The production model, SubQ 1M-Preview, ships with a 1M-token context window and three products in private beta.
TL;DR
- First LLM with fully subquadratic attention: 52x faster than FlashAttention at 1M tokens, ~1,000x less attention compute at 12M tokens
- Production API supports 1M tokens; research model verified to 12M (roughly 120 books in a single pass)
- SWE-Bench Verified 81.8%, RULER 128K 95.0% - competitive with Claude Opus 4.6 and Gemini 3.1 Pro, with all benchmarks self-reported
Every transformer-based model runs into the same ceiling: attention compute scales with the square of input length. Doubling the context window means roughly four times the compute. That relationship is why even the strongest frontier models top out at 1-2M tokens despite years of engineering effort against it. SubQ's SSA (Subquadratic Sparse Attention) architecture attacks the problem differently. For each query token, SSA selects a small subset of candidate positions based on content, then computes exact attention only over those. The result is O(n) scaling instead of O(n²), with the team's technical blog reporting a 7.2x prefill speedup over FlashAttention-2 at 128K tokens and 52.2x at 1M tokens - both measured in wall-clock time on NVIDIA B200s.
The research model runs reliably at 12 million tokens - roughly 9 million words or about 120 books. The production API currently caps at 1M tokens, the same limit as Gemini 3.1 Pro, but the claim is that scaling that ceiling forward won't carry the usual cost explosion. Independent verification of either the benchmarks or the throughput claims hasn't happened yet; the company hasn't released weights, a full technical paper, or external audit results.
 SubQ launched on May 5, 2026 with an early-access API, a CLI coding agent, and a free search product.
Source: subq.ai
SubQ launched on May 5, 2026 with an early-access API, a CLI coding agent, and a free search product.
Source: subq.ai
Key Specifications
| Specification | Details |
|---|---|
| Provider | Subquadratic |
| Model Family | SubQ |
| Parameters | Not disclosed |
| Context Window | 1M tokens (API); 12M tokens (research) |
| Input Price | Not disclosed |
| Output Price | Not disclosed |
| Release Date | 2026-05-05 |
| License | Proprietary |
Benchmark Performance
All benchmark numbers below come from Subquadratic's own technical blog and launch materials. No third-party results are available yet. That caveat matters especially for the competitive comparisons, where Subquadratic's press figures for rival models differ from those models' own published numbers sometimes.
| Benchmark | SubQ 1M-Preview | Claude Opus 4.6 | Gemini 3.1 Pro | GPT-5.5 |
|---|---|---|---|---|
| RULER 128K | 95.0% | 94.8% | n/a | n/a |
| MRCR v2 (1M tokens) | 65.9% | 32.2%* | 26.3% | 74.0% |
| SWE-Bench Verified | 81.8% | 80.8%* | 80.6% | n/a |
*Competitor figures reflect Subquadratic's press release numbers. Claude Opus 4.6's internally published SWE-Bench Verified score is higher (87.6%) in some references, and MRCR v2 shows similar discrepancies. Take the competitive framing accordingly.
On RULER 128K, SubQ matches Claude Opus 4.6 within 0.2 percentage points - a strong result on the long-context benchmarks that test retrieval accuracy across large windows. The MRCR v2 result at 1M tokens is more complicated: SubQ's 65.9% trails GPT-5.5 (74.0%) outright, and sits above or below Claude depending on which Claude number is correct. On coding benchmarks, SWE-Bench Verified at 81.8% is slightly above Gemini 3.1 Pro (80.6%) and the press-release figure for Claude Opus 4.6 (80.8%), but within noise on any realistic evaluation.
The efficiency story is more concrete. Subquadratic reports that hitting 95% on RULER 128K costs $8 with SubQ, versus roughly $2,600 with Claude Opus at comparable accuracy - a 300x cost difference they attribute directly to SSA's linear scaling advantage at that context length.
Key Capabilities
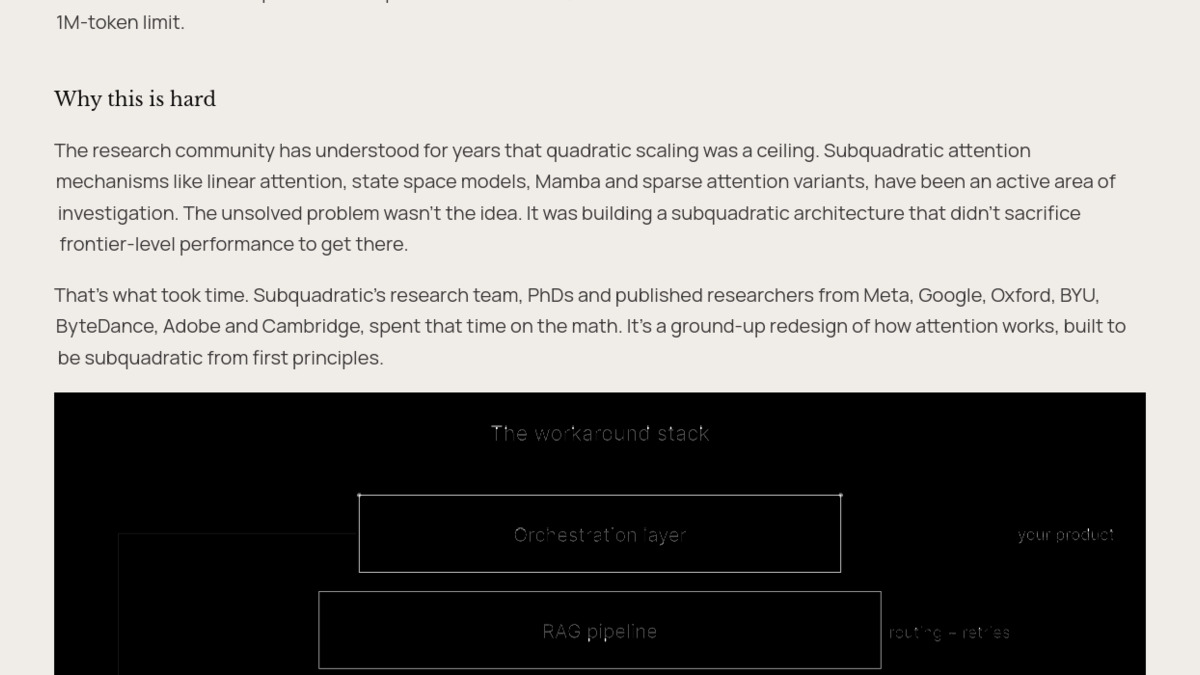 The "workaround stack" that SubQ aims to replace: when models can't hold full context, teams build RAG pipelines and orchestration layers on top.
Source: subq.ai
The "workaround stack" that SubQ aims to replace: when models can't hold full context, teams build RAG pipelines and orchestration layers on top.
Source: subq.ai
The argument for SubQ isn't a raw benchmark win - it's that the benchmark wins are reached at a cost structure that makes long-context practical rather than a special-case budget item. Teams working with large codebases, legal document sets, or long customer interaction histories have historically built retrieval pipelines, chunking strategies, and orchestration layers specifically because no single model call could hold everything. With linear cost scaling and a 1M-token production window, SubQ targets those workloads directly.
SSA Architecture
SSA differs from other sparsity approaches like sliding window attention or fixed-block sparsity. Rather than attending to a predetermined local region, SSA scores candidate positions dynamically based on content and attends only to the selected subset. The company claims this preserves accuracy at long distances while removing the O(n²) compute growth. The team includes 11 PhD researchers from Meta, Google, Oxford, Cambridge, ByteDance, Adobe, and Microsoft. CTO Alex Whedon was previously a software engineer at Meta and led generative AI implementations at TribeAI; CEO Justin Dangel is a five-time founder with background in health tech and insurance tech.
"Building a subquadratic architecture that didn't sacrifice frontier-level performance - that's what took time. It's a ground-up redesign of how attention works, built to be subquadratic from first principles." - Subquadratic launch materials
Products in Private Beta
Three offerings launched simultaneously. The SubQ API provides OpenAI-compatible endpoints with tool use and full context access. SubQ Code is a CLI agent built for repository-level analysis, positioning itself against agentic coding tools that struggle when a codebase exceeds their effective context window. SubQ Search is a free consumer-facing research tool. All three require waitlist registration at subq.ai.
Pricing and Availability
Specific per-token pricing isn't public. Subquadratic's claim is roughly one-fifth the cost of frontier models at comparable accuracy. The $8 vs. $2,600 RULER comparison is the most concrete data point, though it compares at a specific context length where SSA's advantage is maximized.
Unlike most frontier models, there's no free tier, no direct consumer access, and no self-hosting option at launch. The model is closed-source, though the company has showed it will support customer-specific fine-tuning. The OpenAI-compatible API lowers integration friction for developer teams already using standard SDK tooling.
For teams mainly tuning on standard shorter-context workloads where models like DeepSeek V4 Flash dominate on the cost efficiency leaderboard, SubQ's advantage is less clear. The pitch is specifically for the segment where context length itself is the binding constraint.
Funding comes from Javier Villamizar (former SoftBank Vision Fund partner), Justin Mateen (Tinder co-founder, JAM Fund), Grant Gittlin of Lasagna, Jaclyn Rice Nelson of Coalition Operators, and early investors in Anthropic, OpenAI, Stripe, and Brex.
Strengths and Weaknesses
Strengths
- Linear attention scaling solves the quadratic compute ceiling for long-context workloads
- 52x faster than FlashAttention at 1M tokens, verified in wall-clock time on B200s
- SWE-Bench Verified 81.8% is competitive with the frontier on agentic coding
- OpenAI-compatible API reduces adoption friction
- Architecture addresses a real cost problem in production long-context deployments
Weaknesses
- No independent benchmark verification; all numbers are self-reported by Subquadratic
- 12M-token research result not yet available in the production API
- Pricing not disclosed, making cost claims unverifiable before API launch
- No open weights, no technical paper, no reproducibility path for researchers
- MRCR v2 at 65.9% trails GPT-5.5 (74%) on one of the key long-context accuracy tests
- Private beta only; no public access as of May 2026
Related Coverage
- Long-Context Benchmarks Leaderboard
- Coding Benchmarks Leaderboard
- Cost Efficiency Leaderboard
- What Is an AI Context Window?
- Claude Opus 4.6
- Gemini 3.1 Pro
FAQ
What is SubQ's architecture?
SubQ uses SSA (Subquadratic Sparse Attention), a content-based sparse attention mechanism that scales linearly with context length instead of quadratically. It selects a subset of positions to attend to per query token, then runs exact attention over those positions only.
What is SubQ's context window?
The production API supports 1M tokens. The research model has been verified at 12M tokens (roughly 120 books), but that capacity isn't available in the API as of May 2026.
Is SubQ open source?
No. SubQ is proprietary and closed-source. No weights have been released. The company has indicated it will support customer-specific fine-tuning but hasn't published a timeline.
How does SubQ's cost compare to Claude or GPT-5.5?
Per-token pricing hasn't been disclosed. Subquadratic claims roughly one-fifth the cost of frontier models at comparable accuracy, with a specific data point: 95% RULER 128K accuracy for $8 vs. roughly $2,600 with Claude Opus.
Can I use SubQ now?
As of May 2026, SubQ is in private beta. You can request access at subq.ai for the API, SubQ Code (CLI agent), and SubQ Search (free).
Who built SubQ?
Subquadratic, based in Miami. CEO Justin Dangel is a five-time founder; CTO Alex Whedon is a former Meta engineer who led generative AI at TribeAI. The research team includes 11 PhDs from Meta, Google, Oxford, Cambridge, and ByteDance.
Sources:
- Introducing SubQ: The First Fully Subquadratic LLM
- How SSA Makes Long Context Practical
- Subquadratic launches with $29M to bring 12M-token context windows to AI
- The context window has been shattered: Subquadratic debuts a 12-million-token window
- SubQ Review: The First Subquadratic LLM with a 12 Million Token Context
- SubQ: SSA sparse attention, 12M context, and long-context evals
- SubQ: The First Sub-Quadratic Frontier LLM and What It Means for Long-Context AI
Last updated
✓ Last verified May 12, 2026
