SkyReels V4
SkyReels V4 is Skywork AI's unified multi-modal video model that jointly generates 1080p/32FPS video and synchronized audio from a single dual-stream diffusion transformer.

Overview
SkyReels V4 is a unified multi-modal video foundation model from Skywork AI (a division of Chinese internet company Kunlun). Released February 25, 2026 with an accompanying arXiv paper (arXiv:2602.21818), it claims to be the first model to simultaneously support multi-modal input, joint video-audio generation, and a unified treatment of generation, inpainting, and editing in a single pipeline.
TL;DR
- Joint video and audio generation at 1080p/32FPS - one model, not two chained together
- Reached #1 on Artificial Analysis T2V (With Audio) arena on March 19, 2026 before HappyHorse-1.0 surpassed it; currently Elo 1,104 (4th place, tied with Kling 3.0 1080p Pro)
- Priced at $7.20/min with audio and $8.40/min without, with a commercial license included
What distinguishes V4 from the previous SkyReels lineup isn't just a quality bump. V1 through V3 targeted avatar animation and image-to-video workflows. V4 restructures the entire architecture around a dual-stream system that produces video and audio as a single joint output rather than sequential or parallel post-processing. That architectural shift matters more than any benchmark position.
On March 19, 2026, Artificial Analysis announced that SkyReels V4 had taken the #1 spot in the Text to Video (With Audio) category of its Video Arena, surpassing Kling 3.0 and Veo 3.1. HappyHorse-1.0 subsequently took the top position after its surprise release in early April 2026. As of June 2026, V4 sits at Elo 1,104, tied with Kling 3.0 1080p Pro at 4th place in the with-audio ranking.
Key Specifications
| Specification | Details |
|---|---|
| Provider | Skywork AI (Kunlun) |
| Model Family | SkyReels |
| Parameters | Not disclosed |
| Max Resolution | 1080p (also 720p, 480p) |
| Frame Rate | 32 FPS |
| Max Duration | 15 seconds |
| Aspect Ratios | 16:9, 9:16, 4:3, 3:4, 1:1 |
| Input Types | Text, image, video clip, mask, audio reference |
| Output Format | MP4 |
| Pricing (with audio) | $7.20/min (~$0.12/sec) |
| Pricing (without audio) | $8.40/min (~$0.14/sec) |
| Release Date | 2026-02-25 |
| Open Source | Weights not yet released; previous V1-V3 are open |
| License | Commercial license included |
Architecture
SkyReels V4 uses a dual-stream Multimodal Diffusion Transformer (MMDiT). One branch handles video synthesis. The other generates temporally aligned audio. Both branches share a text encoder based on a Multimodal Large Language Model (MLLM), which means the same semantic understanding of a prompt drives both streams in parallel.
The architecture uses a hybrid approach: early layers in each branch use separate parameters but attend to each other via bidirectional cross-attention; later layers share parameters for efficiency. Temporal alignment between video frames and audio tokens uses Rotary Positional Embeddings (RoPE) scaled to the respective temporal resolutions (21 video frames vs. 218 audio tokens per clip).
The efficiency strategy for reaching 1080p/32FPS at 15 seconds is worth noting. Rather than running a single expensive diffusion pass at full resolution, the model jointly creates low-resolution full sequences and high-resolution keyframes, then applies dedicated super-resolution and frame interpolation models. The paper reports this Video Sparse Attention approach cuts compute by roughly 3x compared to a naive full-resolution pass.
Training followed a progressive multi-stage approach spanning six video pretraining stages (text-to-image foundation, video learning, inpainting capabilities, mixed-resolution scaling, high-resolution training, and multi-modal conditioning), followed by audio pretraining on hundreds of thousands of hours of speech data, then joint T2V/T2AV/T2A fine-tuning on 5M videos and a final quality gate on 1M curated clips.
Benchmark Performance
The paper's evaluation used SkyReels-VABench, a proprietary human benchmark covering 2000+ prompts across multiple languages. Fifty professional evaluators rated each output on a 5-point Likert scale across five dimensions, plus pairwise Good-Same-Bad (GSB) comparisons against four competitors.
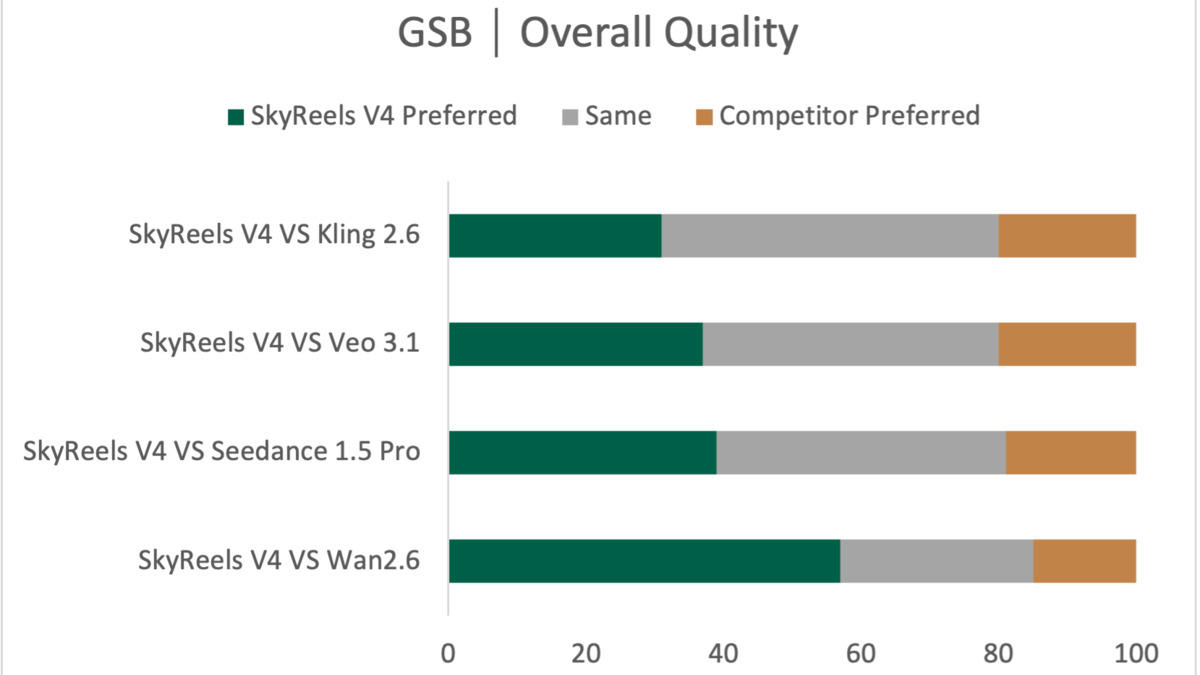 SkyReels V4 GSB (Good-Same-Bad) pairwise preference results from the paper's human evaluation against four competitor models. Green indicates SkyReels V4 preferred; orange indicates competitor preferred.
Source: arxiv.org
SkyReels V4 GSB (Good-Same-Bad) pairwise preference results from the paper's human evaluation against four competitor models. Green indicates SkyReels V4 preferred; orange indicates competitor preferred.
Source: arxiv.org
SkyReels V4 hits the highest overall average score on VABench against its four baselines (Kling 2.6, Seedance 1.5 Pro, Veo 3.1, and Wan 2.6). Its strongest dimensions are Instruction Following and Motion Quality. Its weakest relative advantage is Audio-Visual Synchronization, where the margins are narrower.
On the Artificial Analysis Video Arena at time of paper publication (February 24, 2026), the model ranked third among T2V-with-audio systems, behind Kling 3.0 and Veo 3.1 in that snapshot. It subsequently climbed to #1 briefly in March before current leaders arrived.
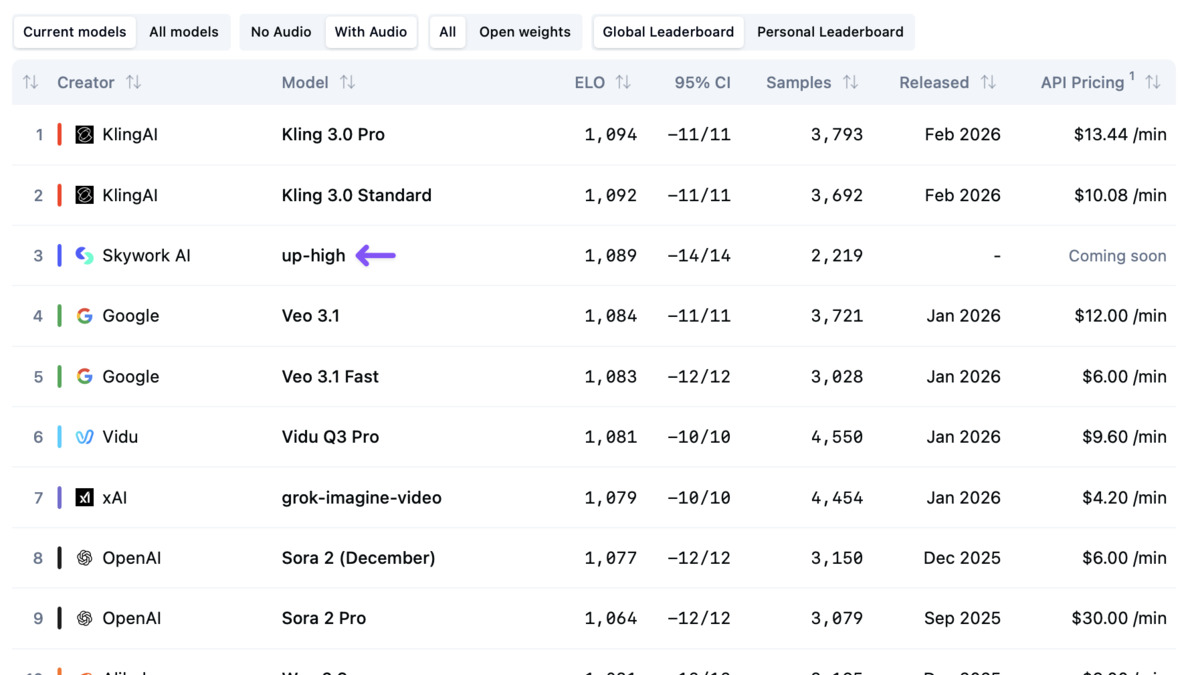 Artificial Analysis T2V (With Audio) Arena leaderboard from the SkyReels V4 paper (February 2026). The model is listed as "up-high" at Elo 1,089 in position 3, above Veo 3.1 (Elo 1,084) and Vidu Q3 Pro (Elo 1,081).
Source: arxiv.org
Artificial Analysis T2V (With Audio) Arena leaderboard from the SkyReels V4 paper (February 2026). The model is listed as "up-high" at Elo 1,089 in position 3, above Veo 3.1 (Elo 1,084) and Vidu Q3 Pro (Elo 1,081).
Source: arxiv.org
One thing to be clear about these numbers: the with-audio leaderboard scores video and audio quality together in human preference tests. Models that produce no audio don't appear on this track. That makes direct visual quality comparisons across the two leaderboard variants (No Audio vs. With Audio) misleading.
| Metric | SkyReels V4 (current) | Kling 3.0 1080p Pro | Seedance 2.0 720p | HappyHorse-1.0 |
|---|---|---|---|---|
| T2V With Audio Elo | 1,104 | 1,105 | 1,219 | 1,125 |
| T2V No Audio Elo | 1,244 | 1,243 | N/A | 1,290 |
| Max Resolution | 1080p | 1080p (native 4K) | 720p | Not disclosed |
| Max Duration | 15 sec | Not specified | Not specified | Not specified |
| Audio | Native joint | Separate | Separate | Separate |
Source: Artificial Analysis Video Arena, WaveSpeed blog, as of June 2026. Rankings shift frequently.
Key Capabilities
Joint Video-Audio Generation
V4's main differentiator isn't resolution or duration - it's the joint generation of video and audio in a single forward pass. Other models in this space produce video first and add audio as a post-processing step, which creates persistent sync issues at scene cuts and rapid motions. V4's bidirectional audio-video cross-attention means the two streams stay temporally coupled all through denoising.
In practice this means prompts like "heavy rain on a tin roof" or "a woman speaking at a podium" produce audio that was generated knowing exactly which frames were being synthesized, not audio that was retrofitted afterward. For content where lip sync or event-driven sound effects matter, that's a real difference from chained pipelines.
Inpainting and Editing
SkyReels V4 unifies generation, inpainting, and video editing through a channel concatenation formulation. All three tasks share the same MMDiT backbone rather than relying on separate fine-tuned models. A masked region in existing footage goes through the same architecture as a fresh text-to-video generation, which means the model can use its full understanding of scene context when filling gaps.
Supported editing operations include object removal, background replacement, selective region modification, and temporal extension of existing clips. The vision-referenced inpainting respects existing texture and lighting when filling masked areas.
Grid Reference (Character Consistency)
Grid Reference lets users upload up to nine keyframe images to define a plot's visual arc. The model extracts character features, wardrobe, and art style from this grid and applies them consistently across the created sequence. This addresses one of the persistent failure modes in AI video - the character morphing or identity drift that happens when prompts alone can't anchor visual specifics across multiple shots.
Omni-Modal Reinforcement Learning
The model includes a reinforcement learning system with a semantic reward model that assesses whether entire video sequences make logical sense, not just individual frame quality. The RL training progressed from simple tasks (5-second static objects) up to complex multi-shot narratives (15-second multi-character scenes), targeting common failure modes like inconsistent emotional states and jump-cut artifacts between shots.
Pricing and Availability
SkyReels V4 is available via the skyreels.ai platform (direct consumer/creator access) and through API providers including WaveSpeed, Runware, and others. All access tiers include a commercial license.
Pricing at the skyreels.ai API is $7.20/min with audio and $8.40/min without audio, which works out to roughly $0.12/sec and $0.14/sec respectively. For a 15-second 1080p clip with audio, that's $1.80 per generation. Video-guided workflows (using an existing clip as reference input) cost more - approximately $0.25/sec at 720p.
For comparison, Veo 3.1 lists at $0.40/sec ($24/min) for Standard 1080p via the Vertex AI API, making SkyReels V4 materially cheaper per minute of output. Kling 3.0 Pro comes in around $13.44/min per the Artificial Analysis data shown in the paper.
The main availability gap: V4 weights haven't been released publicly as of June 2026, unlike V1-V3 which have open weights on Hugging Face. Skywork has an open-source track record with prior versions, but V4 remains API-only for now.
Strengths and Weaknesses
Strengths
- Native joint video-audio generation eliminates the sync issues from post-processing audio pipelines
- Competitive T2V visual quality - statistically tied with Kling 3.0 Pro in no-audio blind tests (Elo 1,244 vs. 1,243)
- More affordable per-minute pricing than Veo 3.1 or Kling 3.0 Pro
- Unified architecture covering generation, inpainting, and editing in one model
- Grid Reference for character consistency across multi-shot sequences
- Commercial license included at all pricing tiers
- Strong open-source lineage (V1-V3 available on Hugging Face/GitHub)
Weaknesses
- 15-second duration ceiling limits use in longer-form production workflows
- V4 model weights not yet released publicly; API-only access
- Image-to-video performance is absent from top-five rankings on Artificial Analysis
- Short operational history compared to Kling 3.0, which has two months of API stability data
- Newer than competitors in the with-audio segment, so third-party testing is still thin
Related Coverage
- Video Generation Benchmarks Leaderboard - current rankings across all major video models
- Best AI Video Generators in 2026 - comparison guide including SkyReels V4, Kling 3.0, and others
- Veo 3.1 model page - Google's competing audio-video model
- LTX-2.3 model page - open-source alternative with native 4K
Sources:
- SkyReels V4 paper (arXiv:2602.21818)
- SkyReels official pricing
- Artificial Analysis Video Leaderboard
- Artificial Analysis announcement on X
- WaveSpeed: What Is SkyReels V4?
- WaveSpeed: HappyHorse vs Kling 3.0 vs SkyReels V4 Builder's Guide
- Z.Tools: SkyReels V4 vs Veo 3.1
- Runware SkyReels V4 model page
- HuggingFace paper page
✓ Last verified June 24, 2026
