Dreamina Seedance 2.0
ByteDance's top-ranked AI video generation model with native joint audio-video synthesis, multi-shot support, and multimodal reference inputs across up to 12 files per generation.

Dreamina Seedance 2.0 is ByteDance's flagship AI video generation model, built by the company's Seed research team. It topped the Artificial Analysis image-to-video arena leaderboard at launch and has held the #1 position for the "with audio" category. The model is striking for creating video and audio in a single pass - not as a two-step pipeline where audio is bolted on afterward - using a dual-branch Diffusion Transformer architecture that treats sound design as a first-class output with the visuals.
TL;DR
- Leads the Artificial Analysis image-to-video leaderboard (Elo 1,194 with audio) and text-to-video arena
- Generates up to 15-second multi-shot video clips with synchronized stereo audio from text, images, video, and audio references in a single call
- Available globally via fal.ai API at $0.247/s Pro and $0.022/s Fast; access uncertain in the US following Senate pressure and Hollywood studio legal action in early 2026
ByteDance officially launched Seedance 2.0 in China on February 12, 2026 through its Dreamina consumer platform and Jimeng app. The global API followed on April 9, 2026 via fal.ai, with Volcengine's enterprise API entering public beta on April 2, 2026. The model is also available inside CapCut for creators in select markets, following a phased geographic rollout that expanded across South America, Africa, the Middle East, Europe, and eventually the US.
The backdrop to that rollout was messy. Within days of the China launch, Hollywood studios - Disney, Paramount, Warner Bros., Netflix, Sony, and Universal - issued cease-and-desist letters. The Motion Picture Association described the situation as copyright infringement "a feature, not a bug." US Senators Marsha Blackburn and Peter Welch sent a letter to ByteDance CEO Liang Rubo in March 2026 demanding a shutdown, citing the model's ability to create content featuring real actors like Tom Cruise and Brad Pitt with licensed franchise characters. ByteDance has pledged safeguards and restricted some face-generation capabilities, but the legal situation remains unresolved.
Key Specifications
| Specification | Details |
|---|---|
| Provider | ByteDance (Seed team) |
| Model Family | Seedance |
| Parameters | Not disclosed |
| Architecture | Dual-branch Diffusion Transformer |
| Max Output Duration | 15 seconds per generation |
| Output Resolution | 480p, 720p (standard); 1080p and 2K via Volcengine |
| Audio | Native dual-channel stereo, produced jointly with video |
| Max Reference Inputs | 9 images + 3 video clips + 3 audio files |
| Supported Aspect Ratios | 21:9, 16:9, 4:3, 1:1, 3:4, 9:16 |
| Multi-shot Support | Yes - coherent scene cuts in a single generation |
| Lip-sync Languages | 8+ (English, Mandarin, Cantonese, Japanese, Korean, Spanish, French, German) |
| License | Proprietary |
| Release Date | February 12, 2026 (China); April 9, 2026 (global API) |
Benchmark Performance
Seedance 2.0 controls the Artificial Analysis video arena, which uses blind pairwise voting to derive Elo scores.
| Leaderboard Category | Seedance 2.0 Elo | Next Best |
|---|---|---|
| Image-to-video (with audio) | 1,194 | HappyHorse-1.1 at 1,121 |
| Image-to-video (without audio) | ~1,344 | Veo 3.1 at ~1,087 |
| Text-to-video (with audio) | 1,219 | Competitors below 1,100 |
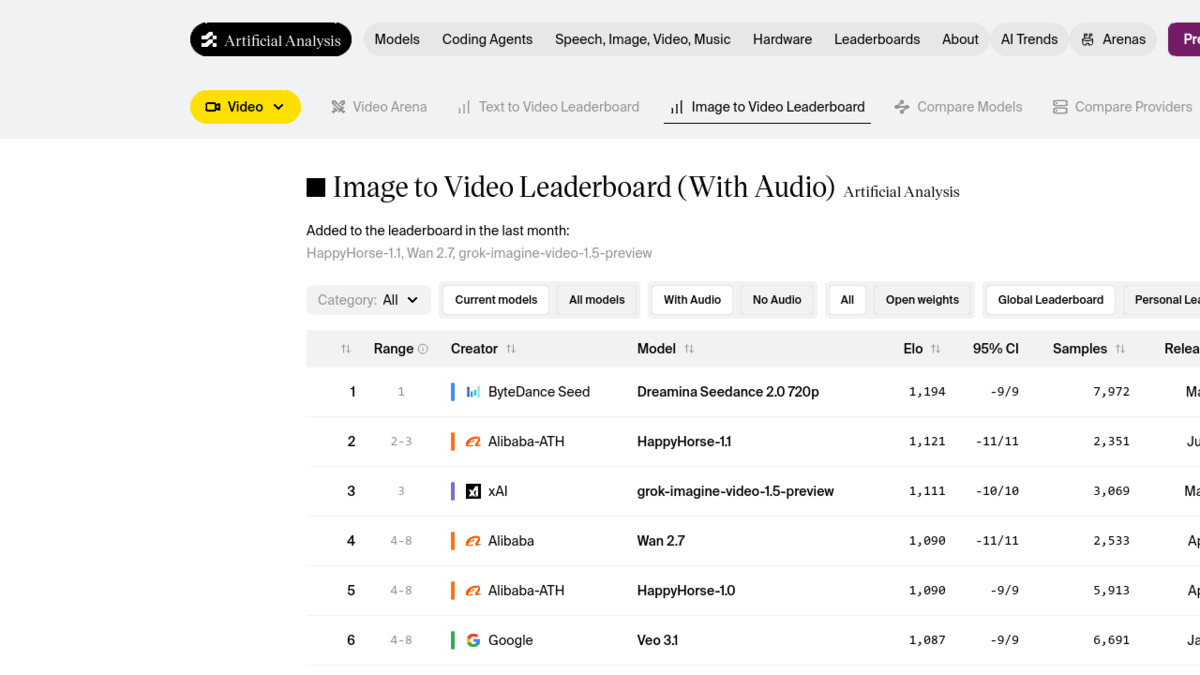 The Artificial Analysis image-to-video leaderboard as of June 2026. Seedance 2.0 leads the with-audio category by a significant margin.
Source: artificialanalysis.ai
The Artificial Analysis image-to-video leaderboard as of June 2026. Seedance 2.0 leads the with-audio category by a significant margin.
Source: artificialanalysis.ai
The Elo gap matters. At 1,194 in the with-audio category, Seedance 2.0 sits more than 70 points above its nearest competitor. In the Artificial Analysis methodology, each Elo point represents real human preference in blind comparisons - this isn't a checklist benchmark or a synthetic metric.
The model's audio quality is the main driver. Competing models that bolt on audio after video generation produce noticeably worse synchronization. Seedance 2.0 produces both branches simultaneously, so foley sounds, background music, and lip-synced dialogue are all frame-level aware of the visual content. That shows up in head-to-head votes.
Where it doesn't lead: raw physics simulation (Sora 2 before its discontinuation in March 2026 was stronger here) and single-shot clip length (Kling 3.0 goes to 4K at 60fps, and the just-announced Seedance 2.5 extends clips to 30 seconds). See our video generation benchmarks leaderboard for full cross-model rankings.
Key Capabilities
Dual-Branch Audio-Video Synthesis
The architecture separates into two branches: one Diffusion Transformer handles spatial quality (textures, lighting, visual detail), while a second branch handles temporal coherence (motion, physics, transitions between frames). Both run in parallel and share information, which is why audio and video stay in sync without a separate post-processing step. The technical paper (arXiv:2604.14148) describes this as a "unified, highly efficient, and large-scale architecture for multi-modal audio-video joint generation."
Multi-Shot Narrative Control
This is the feature that distinguishes Seedance 2.0 from most competitors. A single generation call can produce multiple shots with natural cuts and transitions - so a 15-second output can feel like an edited sequence rather than one continuous clip from a fixed camera. Characters stay consistent across cuts. Combined with multi-language lip-sync at phoneme-level accuracy, this makes it genuinely useful for advertising and short-form content production, not just stylized clips.
Reference-to-Video Workflow
The reference mode accepts up to 9 images, 3 video clips, and 3 audio files simultaneously. You can specify composition from one source, motion patterns from another, and audio texture from a third - all in a single prompt. fal.ai exposes this as the reference-to-video endpoint, separate from the simpler text-to-video and image-to-video endpoints.
 ByteDance's Seedance 2.0 product page demonstrating the model's multimodal generation capabilities.
Source: seed.bytedance.com
ByteDance's Seedance 2.0 product page demonstrating the model's multimodal generation capabilities.
Source: seed.bytedance.com
Camera Planning
Seedance 2.0 infers shot structure from natural language descriptions - you don't need to write explicit cinematography instructions. Prompts like "tracking shot from behind" or "aerial establishing shot" work reliably. The model plans the camera path and angle progression internally.
Pricing and Availability
Three access paths exist, each with different characteristics.
fal.ai (global): Launched April 9, 2026. Six endpoints covering text-to-video, image-to-video, and reference-to-video in both Pro and Fast variants. Pricing per second of produced video:
| Mode | Price per second |
|---|---|
| Pro 720p (with audio) | $0.3034/s |
| Fast 720p (with audio) | $0.2419/s |
| Token-based (480p/720p/1080p) | $0.014 per 1,000 tokens |
| Token-based (4K) | $0.008 per 1,000 tokens |
The token formula is (height × width × duration × 24) / 1024. A 10-second 720p clip with audio costs roughly $3.00 on the Pro tier.
Volcengine (enterprise, China): Public beta from April 2, 2026. Three tiers - Basic 720p, Pro 1080p, and Cinema 2K. Pricing around $0.14/s. Supports 2K (2048x1152) output not available on fal.ai.
Consumer apps: Available inside CapCut and the Dreamina app in expanding geographic markets. China users access it via Jimeng (Chinese phone number and payment required). The consumer tier has restricted face-generation and IP safeguards added following the studio legal pressure.
 The fal.ai API page for Seedance 2.0, showing the six available endpoints for different generation workflows.
Source: fal.ai
The fal.ai API page for Seedance 2.0, showing the six available endpoints for different generation workflows.
Source: fal.ai
US access via fal.ai is technically available, but the Senate demands and ongoing studio litigation create uncertainty. ByteDance has not restricted API access geographically, but the situation could change.
We put the model through its paces in our full hands-on review - including side-by-side clips against Veo 3.1.
Strengths and Weaknesses
Strengths
- Native joint audio-video generation produces clearly better sync than two-step pipelines
- Multi-shot support in a single call is rare and useful for narrative content
- Reference-to-video mode with 12-file multimodal input offers strong creative control
- #1 on Artificial Analysis image-to-video leaderboard (with audio) with a substantial margin
- Multi-language lip-sync at phoneme level across 8+ languages
Weaknesses
- 15-second cap per generation is short compared to Kling 3.0 and the incoming Seedance 2.5 (30 seconds)
- Acknowledged issues with multi-subject consistency and occasional audio distortion
- Text rendering in produced video is unreliable
- Legal exposure in the US - Senate pressure and MPA cease-and-desist create platform risk for commercial use
- 2K output only available via Volcengine (China enterprise), not fal.ai
What's Next
ByteDance announced Seedance 2.5 on June 23, 2026 at the Volcano Engine 2026 event, with a target launch in early July. Key changes: 30-second single-shot clips, up to 50 reference inputs per call, and 4K output. The company also announced that existing Seedance 2.0 would be upgraded to support 4K output. Seedance 2.5 is a significant capability jump - our coverage on The Decoder has more details.
Related Coverage
- Seedance 2.0 Review: ByteDance's Video Generator Has Hollywood Running Scared
- Video Generation Benchmarks Leaderboard 2026
- Veo 3.1 - Google's closest competitor in cinematic quality
FAQ
Is Seedance 2.0 available in the US?
The fal.ai API is accessible from the US, but US Senate pressure and ongoing Motion Picture Association legal action mean platform availability could change. Check fal.ai for current status before building commercial workflows on it.
How does Seedance 2.0 produce audio?
It uses a dual-branch Diffusion Transformer where audio and video are created simultaneously, not sequentially. The audio branch has frame-level awareness of what's on screen, which produces better synchronization than models that add audio after video generation.
What is the maximum video length Seedance 2.0 can produce?
15 seconds per generation. Seedance 2.5, announced June 23, 2026, raises this to 30 seconds.
How much does Seedance 2.0 cost via the API?
Via fal.ai: $0.3034/s for Pro 720p with audio, $0.2419/s for Fast 720p with audio. A 10-second clip costs roughly $3.00 on the Pro tier. Volcengine enterprise pricing is approximately $0.14/s.
Can Seedance 2.0 produce multiple camera shots in one clip?
Yes. Multi-shot support is a core feature - a single 15-second generation can include multiple scene cuts with consistent characters across them, which most competing models don't support natively.
How many reference files can I provide?
Up to 12 files per call: 9 images, 3 video clips, and 3 audio files. This is available through the reference-to-video endpoints on fal.ai.
Sources:
- ByteDance Seed Blog: Official Launch of Seedance 2.0
- arXiv: Seedance 2.0 Technical Paper (2604.14148)
- Hugging Face Paper Page: Seedance 2.0
- fal.ai: Seedance 2.0 API
- Artificial Analysis: Image-to-Video Leaderboard
- TechCrunch: Hollywood isn't happy about Seedance 2.0
- Variety: ByteDance Pledges Safeguards After Disney, Paramount Legal Threats
- The Decoder: Seedance 2.5 Breaks the 30-Second Barrier
- TechCrunch: Dreamina Seedance 2.0 comes to CapCut
- KuCoin: Volcengine Launches Seedance 2.0 API Service
✓ Last verified June 24, 2026
