Sakana Fugu
Sakana AI's orchestrator model that dynamically coordinates Claude Opus 4.8, GPT-5.5, and Gemini 3.1 Pro to beat each of them individually on SWE-Bench Pro, GPQA-Diamond, and eight other benchmarks.

Sakana AI, the Tokyo-based lab founded by former Google Brain researchers David Ha and Llion Jones, launched Sakana Fugu on June 22, 2026. It's not a new base model. Fugu is a trained orchestrator - a language model whose output is a dynamically assembled plan for routing your request across a pool of frontier models, then synthesizing their outputs into a single response.
TL;DR
- Fugu orchestrates Claude Opus 4.8, GPT-5.5, and Gemini 3.1 Pro rather than replacing them - it routes each sub-task to whichever model handles it best
- Fugu Ultra: 1M token context, $5/$30 per million tokens input/output; subscription plans from $20/month
- Leads 10 of 11 published benchmarks over its individual agent pool members, scoring 73.7% on SWE-Bench Pro vs. Opus 4.8's 69.2%
The system ships in two tiers. Standard Fugu is tuned for low latency and works well for code review, interactive chat, and everyday tasks where you want a quick answer. Fugu Ultra applies maximum quality pressure - it activates a larger portion of its agent pool per query and is suited for complex, multi-step engineering or research problems. Both tiers are available through a single OpenAI-compatible API endpoint at console.sakana.ai, with no SDK migration required from existing OpenAI clients.
What makes the product worth watching isn't the benchmark headline, but the design decision underneath it. Sakana framed Fugu partly as a hedge against model access disruption. The Fugu Ultra agent pool currently draws on Claude Opus 4.8, GPT-5.5, and Gemini 3.1 Pro. Anthropic's Fable 5 and Mythos Preview are absent - both became unavailable publicly after US export restrictions went into effect on June 12. The absence isn't hidden: Sakana notes that its pool can be updated as new frontier models are released, and that the routing logic is retrained accordingly.
Key Specifications
| Specification | Details |
|---|---|
| Provider | Sakana AI |
| Model Family | Fugu |
| Type | Multi-agent orchestrator |
| Parameters | Not disclosed |
| Context Window | 1M tokens |
| Max Output | 131K tokens per response |
| Input Price (Fugu Ultra, standard) | $5.00/M tokens |
| Output Price (Fugu Ultra, standard) | $30.00/M tokens |
| Input Price (above 272K context) | $10.00/M tokens |
| Output Price (above 272K context) | $45.00/M tokens |
| Cached Input | $0.50/M tokens (standard) |
| Release Date | June 22, 2026 |
| License | Commercial (closed) |
| API | OpenAI-compatible (console.sakana.ai) |
Subscription plans start at $20/month (Standard), $100/month (Pro, 10x usage), and $200/month (Max, 20x usage). All tiers include both Fugu and Fugu Ultra. Pay-as-you-go pricing applies to enterprise and production workloads. Sakana notes that multi-agent calls don't stack charges: only the highest-tier underlying model's rate applies to a given request.
Standard Fugu uses dynamic pricing based on which underlying models it activates per query, unlike Fugu Ultra's fixed rate.
Benchmark Performance
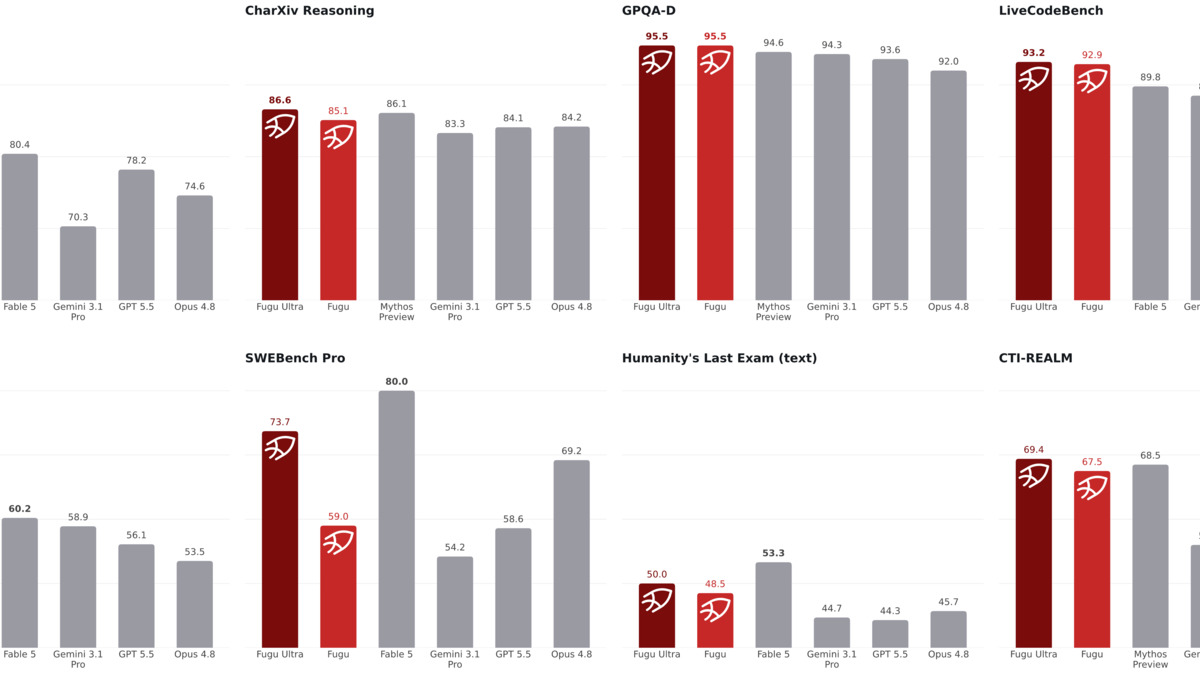 Fugu Ultra benchmark results vs. its agent pool members and top frontier models. Source: Sakana AI via github.com/SakanaAI/fugu
Source: github.com/SakanaAI
Fugu Ultra benchmark results vs. its agent pool members and top frontier models. Source: Sakana AI via github.com/SakanaAI/fugu
Source: github.com/SakanaAI
All numbers below are from Sakana's June 2026 evaluation. Independent third-party replication isn't yet available. On benchmarks where Fable 5 and Mythos Preview scores are listed, those figures come from prior third-party evaluations and Sakana's own published comparisons.
| Benchmark | Fugu Ultra | Fugu | Opus 4.8 | GPT-5.5 | Gemini 3.1 Pro | Fable 5 |
|---|---|---|---|---|---|---|
| SWE-Bench Pro | 73.7% | - | 69.2% | 58.6% | 54.2% | 86.0% |
| TerminalBench 2.1 | 82.1% | - | - | - | - | - |
| LiveCodeBench | 93.2% | 92.9% | - | - | - | 89.8% |
| LiveCodeBench Pro | 90.8% | - | - | - | - | - |
| GPQA-Diamond | 95.5% | 95.5% | - | - | - | - |
| Humanity's Last Exam | 50.0% | - | - | - | - | 53.3% |
| CharXiv Reasoning | 86.6% | - | - | - | - | - |
On 10 of 11 published benchmarks, Fugu Ultra leads its own agent pool members. The one exception is SWE-Bench Pro, where Fable 5 scores 86.0% compared to Fugu Ultra's 73.7%. That gap is real and not trivial - nearly 13 points on a hard coding benchmark. Sakana's framing of being "shoulder-to-shoulder" with Fable 5 is accurate on reasoning and science tasks but doesn't hold on the benchmark most relevant to software engineering agents.
GPQA-Diamond at 95.5% is striking. Both tiers of Fugu post the same score there, suggesting the orchestration overhead adds little on tasks where the pool members can individually nail questions but benefit from cross-verification. LiveCodeBench tells a similar story: Fugu Ultra scores 93.2% versus Fugu's 92.9%, a near-negligible gap.
What these numbers don't capture is latency. Early testers noted that Fugu Ultra queries can take 30 minutes on complex coding tasks, which reflects the cost of running multi-agent rounds. That's acceptable for overnight batch jobs, but a poor fit for interactive workflows.
Key Capabilities
 Fugu's orchestration architecture: a coordinator assigns Thinker, Worker, and Verifier roles dynamically per query turn. Source: Sakana AI via github.com/SakanaAI/fugu
Source: github.com/SakanaAI
Fugu's orchestration architecture: a coordinator assigns Thinker, Worker, and Verifier roles dynamically per query turn. Source: Sakana AI via github.com/SakanaAI/fugu
Source: github.com/SakanaAI
Fugu's technical foundation comes from two papers Sakana published at ICLR 2026. TRINITY describes a roughly 0.6B-parameter coordinator model, trained with CMA-ES evolutionary search, that assigns Thinker, Worker, and Verifier roles to models in a pool turn by turn. Conductor is a 7B model trained with reinforcement learning to discover natural-language coordination strategies - it writes targeted instructions for each worker LLM and can call itself recursively to scale compute at test time. The arXiv technical report covers both architectures and their combination in the Fugu product.
The practical result is that users never choose which underlying model handles their request. Fugu reads the query and decides internally - which is convenient, but also means the per-query routing is proprietary and not exposed in the API response. You can't audit why a given request went to GPT-5.5 over Opus 4.8.
Fugu Ultra's agent pool is fixed: it always includes the full set of available frontier models and does not allow opt-out. Standard Fugu supports selective opt-out of specific agents, which matters for enterprise compliance scenarios where, for example, data residency or export control rules restrict which underlying models can process a given request.
The system excels at tasks that benefit from multiple independent passes and cross-verification - long code reviews, research synthesis, complex debugging sessions where different models catch different bugs. One beta developer cited Fugu Ultra catching more than 20 bugs in a codebase versus 3 flagged by a single model baseline. That kind of systematic coverage is the core value proposition.
Context handling is also strong at 1M tokens. Fugu inherits the long-context capability of its agent pool members, though pricing jumps at 272K tokens ($5/$30 below, $10/$45 above per million tokens), so large-context workloads get expensive quickly.
Pricing and Availability
Fugu is available through console.sakana.ai with standard OpenAI-compatible credentials. Point an existing OpenAI client at the Sakana endpoint and switch the model parameter to fugu-ultra-20260615 or fugu-20260615. The API supports both Chat Completions and Responses endpoints.
Sakana offers a one-line install that patches the model into OpenAI Codex:
curl -fsSL https://sakana.ai/fugu/install | bash
Then launch with codex-fugu. The install supports Ubuntu and macOS; Windows users need the manual setup path.
Subscription tiers bundle both Fugu and Fugu Ultra:
| Tier | Price | Usage |
|---|---|---|
| Standard | $20/month | Lightweight workflows |
| Pro | $100/month | 10x Standard |
| Max | $200/month | 20x Standard |
| Pay-as-you-go | Per token (see above) | Enterprise / production |
Subscribers who sign up by July 31, 2026 receive the second month free at their initial tier. Geographic availability is currently restricted - EU/EEA users face access limitations during an ongoing compliance review.
No HuggingFace presence; Fugu is a commercial API service, not an open model.
Compared to running Claude Opus 4.8 directly at $5/$25 per million tokens, Fugu Ultra costs the same on input but costs more on output ($30 vs. $25). The bet is that Fugu's synthesis produces better answers than a single Opus call for the tasks where quality is the limiting factor.
See our coding benchmarks leaderboard for how Fugu Ultra stacks up against other top models on software engineering tasks, and our agentic AI benchmarks leaderboard for multi-step task performance.
Strengths and Weaknesses
Strengths
- Beats each individual agent pool member on 10 of 11 benchmarks through cross-model verification
- OpenAI-compatible API requires no SDK changes for existing OpenAI users
- Vendor-diversity hedge: pool can be updated if specific models lose availability
- Selective agent opt-out in standard Fugu helps with compliance constraints
- 1M token context window inherits from its pool members
- LiveCodeBench at 93.2% and GPQA-Diamond at 95.5% are among the highest published scores in those categories
Weaknesses
- Not competitive with Fable 5 on SWE-Bench Pro (73.7% vs. 86.0%) - a meaningful gap for software engineering agent workflows
- High latency on Fugu Ultra for complex tasks (early reports of 20-30 minute completions)
- Proprietary routing - no visibility into which models handled your query
- Fugu Ultra pool opt-out not supported; compliance users must use standard Fugu
- Benchmarks are self-reported; no independent third-party evaluation published yet
- Output pricing ($30/M) is 20% higher than Opus 4.8's $25/M
- EU/EEA access restricted during compliance review
- Relies on continued availability of third-party model APIs; true independence requires running pool members locally
Related Coverage
- Claude Opus 4.8 - Strongest single-model competitor in the Fugu pool
- GPT-5.5 - Second pool member; scores 58.6% on SWE-Bench Pro vs. Fugu Ultra's 73.7%
- Gemini 3.1 Pro - Third pool member; 54.2% on SWE-Bench Pro
- Claude Fable 5 - Scores 86.0% on SWE-Bench Pro but unavailable since June 12
- Coding Benchmarks Leaderboard - SWE-Bench rankings across all tracked models
- Agentic AI Benchmarks Leaderboard - Multi-step task performance rankings
FAQ
Is Sakana Fugu a new LLM?
No. Fugu is an orchestrator trained to coordinate other LLMs. It routes tasks to Claude Opus 4.8, GPT-5.5, and Gemini 3.1 Pro internally, then synthesizes the outputs. The underlying base models come from Anthropic, OpenAI, and Google.
How does Fugu Ultra differ from standard Fugu?
Fugu Ultra uses a larger agent pool per query and optimizes for answer quality at the cost of higher latency and fixed pricing. Standard Fugu is faster, supports selective agent opt-out, and uses dynamic pricing based on which models it activates.
Does Fugu work with existing OpenAI SDKs?
Yes. The API is OpenAI-compatible. Point your existing client at the Sakana endpoint, swap in the model ID (fugu-ultra-20260615 or fugu-20260615), and it works without code changes.
Why is Fugu Ultra worse than Fable 5 on SWE-Bench Pro?
Fable 5 and Claude Mythos Preview aren't in the Fugu agent pool because they became unavailable after US export restrictions on June 12, 2026. Fugu Ultra's pool currently tops out at Opus 4.8, which scores 69.2% on SWE-Bench Pro individually. Orchestration adds roughly 4.5 points, reaching 73.7% - still well below Fable 5's 86.0%.
Is Fugu open source?
No. Fugu is a closed commercial API. The orchestrator architecture itself is proprietary. Sakana has published technical papers describing the TRINITY and Conductor methods, but the trained model weights and routing logic aren't publicly released.
Is Fugu available in Europe?
Not currently. Sakana has restricted EU/EEA access pending a compliance review. Timeline for broader availability hasn't been announced.
Sources
- Sakana Fugu release announcement - sakana.ai
- Sakana Fugu Technical Report (arXiv 2606.21228) - arxiv.org
- GitHub: SakanaAI/fugu - github.com
- Fugu Ultra API specs and pricing - requesty.ai
- Sakana AI Launches Sakana Fugu - MarkTechPost - marktechpost.com
- Sakana AI's Fugu orchestrates multiple LLMs - The Decoder - the-decoder.com
- Japan's Sakana Fugu multiagent AI - Nikkei Asia - asia.nikkei.com
- VentureBeat: No Claude Fable 5? No problem - venturebeat.com
- Sakana Fugu pricing explained - ayautomate.com
- What Is Sakana Fugu - sakutto.ai - sakutto.ai
✓ Last verified June 23, 2026
