Qwen 3.6-35B-A3B
Alibaba's 35B sparse MoE with 3B active parameters delivers 73.4% SWE-bench Verified, multimodal vision and video, 256K context, and DeltaNet hybrid architecture under Apache 2.0.
Overview
Qwen 3.6-35B-A3B is the latest sparse MoE model from Alibaba's Qwen team, succeeding Qwen 3.5-35B-A3B. It activates 3 billion of its 35 billion parameters per token through 256 experts (8 routed + 1 shared), using a hybrid Gated DeltaNet + attention architecture.
TL;DR
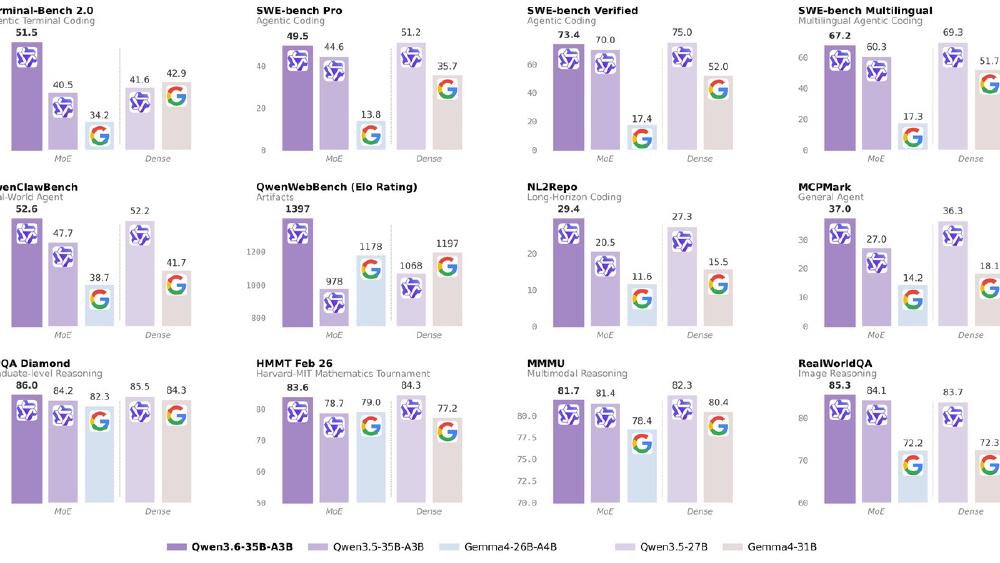
- 73.4% SWE-bench Verified with only 3B active parameters - competing with models 10x its inference cost
- Multimodal: text + images + video with 92.0 RefCOCO spatial intelligence and 83.7 VideoMMU
- Apache 2.0 license, Q4 quantization fits in 22.4 GB (single RTX 4090)
The model's distinguishing feature is agentic coding performance that punches well above its active parameter count. At 51.5% on Terminal-Bench 2.0 and 73.4% on SWE-bench Verified, it matches or exceeds much larger models on real-world coding tasks. The DeltaNet layers scale linearly with context rather than quadratically, making long-context agentic work practical on consumer hardware.
Key Specifications
| Specification | Details |
|---|---|
| Provider | Alibaba (Qwen Team) |
| Model Family | Qwen 3.6 |
| Parameters | 35B total / 3B active |
| Architecture | Gated DeltaNet + MoE (256 experts, 9 active) |
| Layers | 40 (10 blocks of 3 DeltaNet + 1 attention) |
| Context Window | 256K native (1M with YaRN) |
| Input Price | Free (Apache 2.0) |
| Output Price | Free (Apache 2.0) |
| Release Date | April 16, 2026 |
| License | Apache 2.0 |
| Modalities | Text, images, video |
| Hidden Dimension | 2,048 |
| BF16 Model Size | 69.4 GB |
| Q4_K_XL Size | 22.4 GB |
Benchmark Performance
| Benchmark | Qwen 3.6-35B | Qwen 3.5-35B | Gemma 4 31B | Dense Qwen 3.5-27B |
|---|---|---|---|---|
| SWE-bench Verified | 73.4 | 70.0 | N/P | 72.4 |
| Terminal-Bench 2.0 | 51.5 | 40.5 | N/P | N/P |
| GPQA Diamond | 86.0 | 84.2 | 84.3 | 85.5 |
| MMLU-Pro | 85.2 | N/P | 85.2 | 86.1 |
| AIME 2026 | 92.7 | 91.0 | 89.2 | N/P |
| LiveCodeBench v6 | 80.4 | N/P | 80.0 | 80.7 |
| MMMU | 81.7 | N/P | N/P | N/P |
| VideoMMU | 83.7 | 80.4 | N/P | N/P |
| RefCOCO | 92.0 | 89.2 | N/P | N/P |
The 11-point jump on Terminal-Bench (40.5 to 51.5) is the largest single improvement. This benchmark measures autonomous coding in terminal environments - exactly the workload where MoE efficiency matters most because sessions are long-running and token-heavy.
Key Capabilities
Agentic coding
The model is optimized for repository-level coding tasks: frontend workflows, multi-file refactoring, test generation, and build-debug cycles. QwenWebBench (an internal bilingual web development benchmark) jumped 43% from 978 to 1,397. MCPMark (measuring MCP tool use) improved from 27.0 to 37.0.
Multimodal
Text, image, and video understanding are native. The vision encoder handles static images for document analysis, chart reading, and UI evaluation. Video understanding supports configurable frame sampling rates for hour-scale content. RefCOCO at 92.0 indicates strong spatial grounding - useful for UI testing and visual debugging.
Thinking modes
The model supports both thinking (chain-of-thought) and non-thinking (direct response) modes, switchable via enable_thinking parameter. A preserve_thinking mode carries reasoning context across turns without regenerating it - reducing overhead in iterative development sessions.
Pricing and Availability
Free and open under Apache 2.0. Available on HuggingFace in BF16 and multiple GGUF quantizations.
The hosted equivalent is Qwen3.6-Flash on Alibaba Cloud Model Studio, which adds 1M context by default and built-in tool support.
| Quantization | Size | Target Hardware |
|---|---|---|
| BF16 | 69.4 GB | Multi-GPU / A100 |
| Q5_K_XL | 26.6 GB | RTX 4090 / 2x3090 |
| Q4_K_XL | 22.4 GB | RTX 4090 (recommended) |
| UD-Q3_XXS | 13.2 GB | RTX 3090 / RTX 4070 Ti |
| UD-IQ2_XXS | 10.8 GB | 12GB GPUs (compressed) |
Inference via SGLang, vLLM, KTransformers, or HuggingFace Transformers.
Strengths
- SWE-bench and Terminal-Bench scores rival models 10x the active parameter count
- 3B active parameters means fast, cheap inference
- Full multimodal: text + images + video in one model
- Apache 2.0 with no usage restrictions
- DeltaNet architecture provides linear context scaling
- Fits on consumer GPUs at Q4 (22.4 GB)
Weaknesses
- No Chatbot Arena Elo score available yet
- DeltaNet kernels are still immature in most frameworks (see megakernel research)
- 3B active parameters limits raw reasoning depth vs dense 27B+ models on academic math
- Video understanding requires careful frame sampling configuration
Related Coverage
- Qwen 3.6 Release News
- Qwen 3.5-35B-A3B Model Card
- RTX 3090 Beats M5 Max - DeltaNet Megakernel
- Overall LLM Rankings - April 2026
Sources:
✓ Last verified April 16, 2026
