Qwen3.5-Omni
Alibaba's Qwen3.5-Omni takes text, images, audio, and video as input and streams both text and speech output in a single end-to-end model with a 256K context window.

Qwen3.5-Omni is Alibaba's natively multimodal model. It takes text, images, audio, and video as input and produces text plus streaming speech in a single forward pass. Shipped on March 30, 2026 in three variants - Plus, Flash, and Light - it sits at the crossroads of frontier voice AI and open-weight development.
TL;DR
- One model handles text, image, audio, video input while creating text and speech output - no bolt-on TTS
- Plus hits SOTA on 215 subtasks and edges out Gemini 3.1 Pro on MMAU and LibriSpeech
- 256K context covers 10+ hours of audio or 400 seconds of 720p video in one call
- Pricing starts at $0.10/M input tokens for Flash; Light weights on Hugging Face for self-hosting
Qwen3-Omni handled 19 input languages for speech and 10 outputs. The 3.5 generation jumps to 113 and 36, which changes the calculus for voice agents outside the English-Chinese axis. The architecture evolves the Thinker-Talker design onto the Hybrid-Attention MoE backbone shared with the rest of the Qwen 3.5 series.
Key Specifications
| Specification | Details |
|---|---|
| Provider | Alibaba Cloud (Qwen) |
| Model Family | Qwen 3.5 Omni |
| Architecture | Thinker-Talker with Hybrid-Attention MoE |
| Total Parameters (Plus) | ~30B total, ~3B active per token |
| Variants | Plus, Flash, Light |
| Context Window | 256K tokens (native) |
| Max Audio Input | 10+ hours continuous |
| Max Video Input | 400+ seconds of 720p at 1 FPS |
| Input Modalities | Text, Image, Audio, Video |
| Output Modalities | Text, Speech (streaming) |
| Speech Recognition | 113 languages and dialects |
| Speech Generation | 36 languages |
| Input Price (Plus) | $0.40/M tokens |
| Output Price (Plus) | $4.80/M tokens |
| Input Price (Flash) | $0.10/M tokens |
| Output Price (Flash) | $0.80/M tokens |
| Release Date | March 30, 2026 |
| License | Apache 2.0 for open weights (Light); Plus and Flash via API |
The 256K context maps to roughly 10 hours of audio or 400 seconds of 720p video at 1 FPS. For meeting transcription or long-form podcast editing, that's enough to process entire sessions in one call.
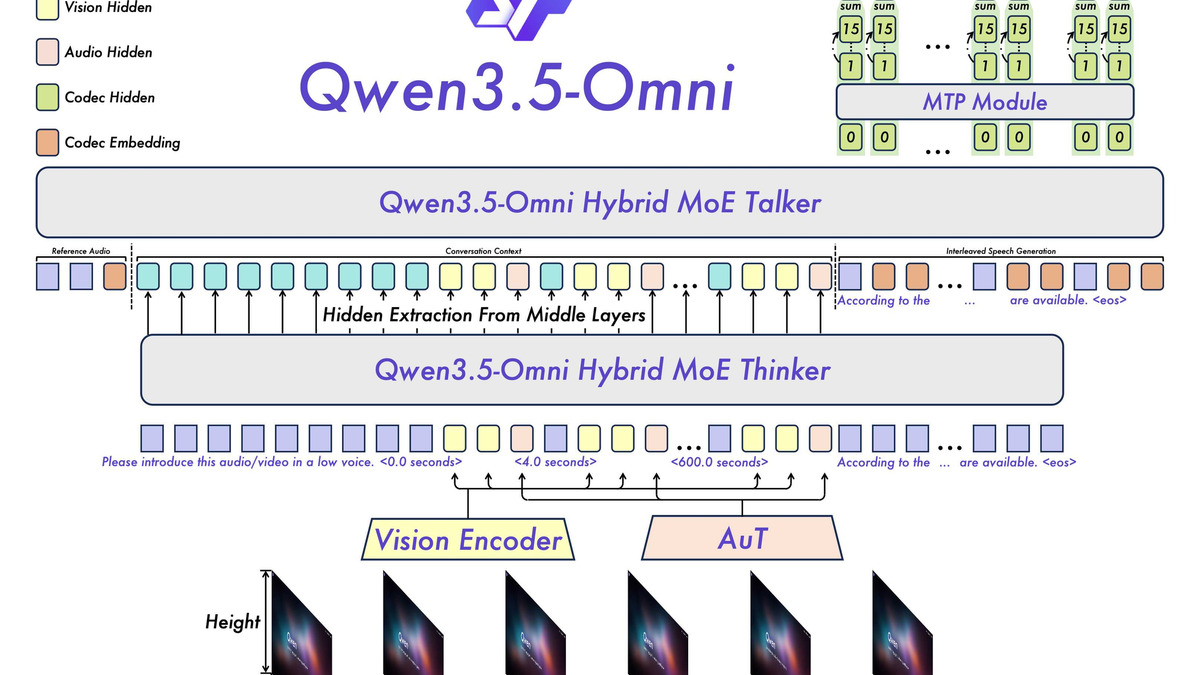 Qwen3.5-Omni's Thinker-Talker architecture. The Thinker ingests text, audio, images, and video through a Hybrid-Attention MoE. The Talker produces streaming speech tokens concurrently with generation.
Source: apidog.com
Qwen3.5-Omni's Thinker-Talker architecture. The Thinker ingests text, audio, images, and video through a Hybrid-Attention MoE. The Talker produces streaming speech tokens concurrently with generation.
Source: apidog.com
Benchmark Performance
Alibaba reports 215 SOTA results for Plus across audio, audio-visual, visual, text, and speech-generation benchmarks. The directly comparable numbers against Gemini 3.1 Pro are where the claim carries the most weight.
| Benchmark | Qwen3.5-Omni-Plus | Gemini 3.1 Pro | GPT-Audio | ElevenLabs |
|---|---|---|---|---|
| MMAU (audio understanding) | 82.2 | 81.1 | - | - |
| MMSU (audio understanding) | 82.8 | 81.3 | - | - |
| RUL-MuchoMusic | 72.4 | 59.6 | - | - |
| VoiceBench (dialogue) | 93.1 | 88.9 | - | - |
| LibriSpeech clean WER | 1.11 | 3.36 | - | - |
| LibriSpeech other WER | 2.23 | 4.41 | - | - |
| CV15 (en) WER | 4.83 | 8.73 | - | - |
| MMLU-Redux (text) | 94.2 | - | - | - |
| MMMU-Pro (visual reasoning) | 73.9 | - | - | - |
| Seed-zh voice stability (lower better) | 1.07 | 2.42 (2.5 Pro) | 1.11 | 13.08 |
| Seed-hard WER | 6.24 | - | 8.19 | 27.70 |
Word error rate on LibriSpeech clean drops from 3.36 (Gemini 3.1 Pro) to 1.11 - roughly a two-thirds reduction on a benchmark where gains have been fractional for years. Music understanding on RUL-MuchoMusic swings from 59.6 to 72.4, pointing to substantially more musical audio in training than competitors had.
Text performance is the quiet story. MMLU-Redux 94.2 for the Omni variant sits within a point of the non-multimodal Qwen3.5-Plus at 94.3. Adding native audio and video didn't cost the model on text reasoning, which has historically been a tradeoff in unified architectures.
The Artificial Analysis Intelligence Index places Plus at 39 (rank 8 of 67) and Flash at 26 (rank 13 of 78). Both are non-reasoning models.
Key Capabilities
The headline capability is Audio-Visual Vibe Coding: point a camera at a UI or share a screen, describe what you want built verbally, and the model produces functional code from the combined audio-visual stream with no text prompt. The Decoder frames it as emergent rather than an explicit training target - more interesting than the marketing positioning suggests.
Semantic interruption matters for production voice agents. Earlier real-time models struggled to separate a user wanting to cut in from background noise. Qwen3.5-Omni's turn-taking intent recognition distinguishes backchannels ("uh-huh", "right") from actual interruptions. Whether it holds up in a noisy open-plan office is something builders will need to test, but the architecture handles it at the model level rather than via an external VAD pipeline.
Voice cloning works from 10-30 second samples and exposes controls for speed, volume, and emotion. On Seed-zh stability (lower better), Plus scores 1.07 against ElevenLabs 13.08, GPT-Audio 1.11, and Minimax 1.19. On Seed-hard, cloned-voice WER is 6.24 versus ElevenLabs 27.70. That gap matters for customer-facing products where voice drift or word errors kill the experience.
Pricing and Availability
DashScope pricing differs between international (Singapore) and mainland China regions. Headline rates via Artificial Analysis:
| Variant | Input | Output | Blended (3:1) | Context |
|---|---|---|---|---|
| Qwen3.5-Omni-Plus | $0.40/M | $4.80/M | $1.50/M | 256K |
| Qwen3.5-Omni-Flash | $0.10/M | $0.80/M | - | 256K |
| Qwen3.5-Omni-Light | Free (self-host) | Free (self-host) | - | 256K |
| Gemini 3.1 Pro | $2.00/M | $12.00/M | - | 1M |
| GPT-5.2 | $10.00/M | $30.00/M | - | 400K |
At $0.10/M input, Flash is one of the cheapest frontier-tier multimodal APIs - matching text-only Qwen3.5-Flash pricing but with audio, video, and speech output folded in. Plus is still under a third of Gemini 3.1 Pro's rate.
Access paths:
- DashScope API - Plus and Flash via
qwen3.5-omni-plusandqwen3.5-omni-flashmodel IDs, OpenAI-compatible interface - Qwen-Omni-Realtime WebSocket - live audio and video streams with full-duplex conversation and semantic interruption (docs)
- Hugging Face - Light variant weights plus demo spaces (online, offline)
- Qwen Chat - consumer-facing test interface at chat.qwen.ai
New DashScope accounts in Singapore get a free quota of 1M input and 1M output tokens for 90 days. Audio tokenizes at roughly 427 tokens per minute, so a 10-minute voice call burns around 4,300 input tokens before any response.
Strengths
- SOTA on directly comparable audio benchmarks - LibriSpeech WER and MMAU ahead of Gemini 3.1 Pro
- Native multimodal single forward pass with streaming speech output concurrent with generation
- 256K context for 10+ hour audio or 400-second 720p video in one call
- 113-language speech recognition and 36-language generation
- Plus pricing undercuts Gemini 3.1 Pro 5x on input and 2.5x on output
- Voice cloning stability far ahead of ElevenLabs on Seed-zh and Seed-hard
- Light variant ships with open weights, preserving Qwen's Apache 2.0 tradition
Weaknesses
- The 215 SOTA claim is thin - many entries are per-language ASR and S2TT subtasks with little competition
- Plus needs 40GB+ VRAM for FP16 self-hosting, pricing individual developers out
- Parameter counts for Flash and Light aren't formally disclosed
- DashScope tiered pricing can get complex on long prompts - chunking may be cheaper
- Plus and Flash are API-only; only Light has published weights
- Non-reasoning model, trails reasoning frontier on chain-of-thought benchmarks
- Verbose outputs - Artificial Analysis measured 16M tokens against a 7.2M average
Related Coverage
- Qwen3.5-Omni Does 10-Hour Audio and 4M Video Frames - original launch coverage
- Alibaba Drops Qwen3.5: 397B Parameters, 17B Active - flagship text model in the same generation
- Qwen3.5-35B-A3B - open-weight sibling sharing the MoE backbone
- Qwen3.5-Flash - text-only hosted API variant at similar pricing
- Gemini 3.1 Pro - closest audio-benchmark peer
- AI Voice and Speech Leaderboard
- Audio Understanding Benchmarks Leaderboard
- How to Set Up an AI Voice Agent
- Qwen 3 Review
Sources
- Qwen3.5-Omni: Scaling Up, Toward Native Omni-Modal AGI - Qwen Blog
- Qwen3.5-Omni Technical Details - Analytics Vidhya
- Qwen3.5-Omni: SOTA in 215 Benchmarks - StableLearn
- What Is Qwen3.5-Omni - WaveSpeedAI
- Qwen3.5-Omni API Pricing - WaveSpeedAI
- Qwen3.5 Omni Plus Price Analysis - Artificial Analysis
- Qwen3.5 Omni Flash Price Analysis - Artificial Analysis
- Qwen3.5-Omni Beats Gemini on Audio - Apidog
- Qwen3.5-Omni Can Hear, Watch, and Clone Your Voice - Decrypt
- Qwen3.5-Omni Review - BuildFastWithAI
- Qwen3.5-Omni Learned to Code from Spoken Instructions - The Decoder
- Qwen3-Omni GitHub Repository
- Qwen-Omni Realtime API Docs - Alibaba Cloud
- Qwen Pricing - PricePerToken
Last updated
✓ Last verified April 21, 2026
