Qwen3.5-Flash
Qwen3.5-Flash is Alibaba's hosted production model with 1M context, built-in tools, and multimodal support at $0.10/M input tokens - one of the cheapest frontier-tier APIs available.
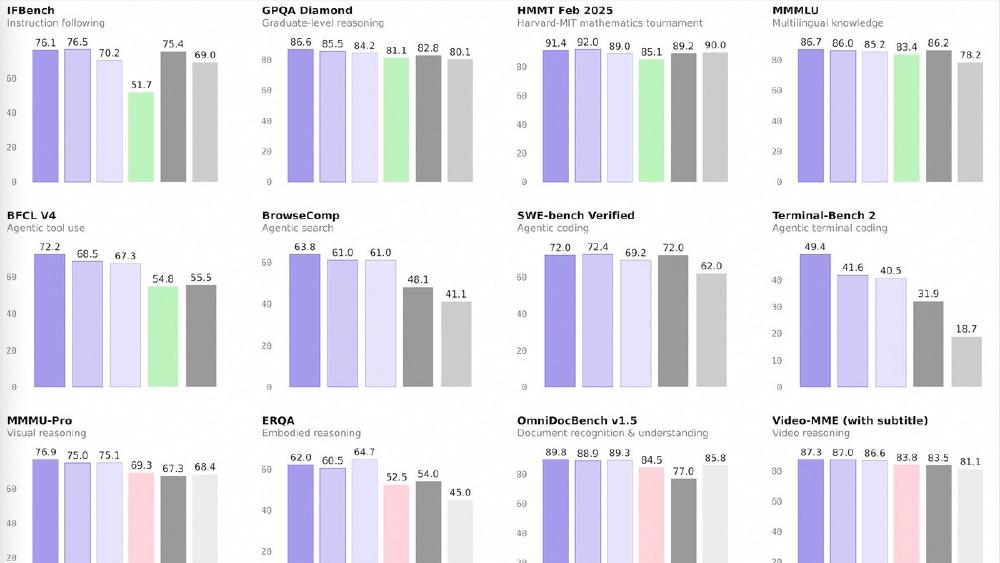
Qwen3.5-Flash is the hosted production tier of Alibaba's Qwen 3.5 Medium Series, aligned with the open-weight 35B-A3B model but optimized for API consumption. It ships with 1M context by default, official built-in tool support, and native multimodal capabilities covering text, image, and video inputs.
TL;DR
- Hosted production API aligned with Qwen3.5-35B-A3B, the model that surpasses the previous 235B flagship
- 1M token context window with built-in tool calling and thinking mode
- $0.10/M input, $0.40/M output - roughly 25x cheaper than GPT-5-mini for input tokens
- Native multimodal: text, images, and video in a single model
Flash sits in a specific niche: it's the API product that Alibaba wants developers and enterprises to build against. While the 35B-A3B, 122B-A10B, and 27B weights are Apache 2.0 for self-hosting, Flash is the managed service that handles scaling, context caching, and tool orchestration.
Key Specifications
| Specification | Details |
|---|---|
| Provider | Alibaba Cloud (Qwen) |
| Model Family | Qwen 3.5 |
| Architecture | Gated DeltaNet + MoE (aligned with 35B-A3B) |
| Parameters | Not disclosed |
| Context Window | 1,000,000 tokens |
| Max Output | 65,536 tokens |
| Input Modalities | Text, Image, Video |
| Thinking Mode | Enabled by default (toggleable) |
| Batch Calling | Supported (50% discount) |
| Context Caching | Supported |
| Input Price | $0.10/M tokens (international) |
| Output Price | $0.40/M tokens (international) |
| Release Date | February 24, 2026 |
| License | Proprietary (hosted API only) |
Pricing varies by region. The international tier (Singapore) runs a flat $0.10/$0.40. The mainland China tier uses length-based pricing: $0.022/$0.216 for prompts under 128K tokens, scaling to $0.173/$1.721 for prompts between 256K and 1M tokens.
Benchmark Performance
Flash is aligned with the 35B-A3B open model. Alibaba's reported benchmarks for the base model:
| Benchmark | Qwen3.5-35B-A3B | GPT-5-mini | Qwen3-235B-A22B |
|---|---|---|---|
| MMLU-Pro | 85.3 | 83.7 | 84.4 |
| GPQA Diamond | 84.2 | 82.8 | 81.1 |
| HMMT Feb 25 | 89.0 | 89.2 | 85.1 |
| SWE-bench Verified | 69.2 | 72.0 | - |
| TAU2-Bench (Agent) | 81.2 | 69.8 | 58.5 |
| MMMU (Vision) | 81.4 | 79.0 | 80.6 |
| MathVision | 83.9 | 71.9 | 74.6 |
The agent benchmark (TAU2-Bench) is where Flash shines in production - 81.2 versus 69.8 for GPT-5-mini and 58.5 for the previous Qwen 3 flagship. The built-in tool support makes Flash a natural fit for agentic workflows.
Key Capabilities
Flash's primary differentiator is the combination of long context, native multimodal processing, and built-in tools at an aggressively low price point. The 1M token context window isn't a theoretical maximum - it's the default, with context caching to reduce costs on repeated prefixes.
The native multimodal training means image and video understanding is not bolted on via a separate vision adapter. The model processes visual tokens through the same architecture, which Alibaba claims improves coherence between visual and textual reasoning. ScreenSpot Pro scores of 68.6 for the base model suggest genuine UI understanding, not just image captioning.
Thinking mode is enabled by default but can be toggled off for latency-sensitive applications. When enabled, the model creates internal reasoning chains before producing its final answer, similar to chain-of-thought prompting but built into the model's inference loop.
Pricing and Availability
Flash is available through Alibaba Cloud Model Studio and through Qwen Chat for consumer testing.
| Provider | Input Cost/M | Output Cost/M | Context |
|---|---|---|---|
| Qwen3.5-Flash | $0.10 | $0.40 | 1M |
| DeepSeek V3.2 | $0.14 | $0.28 | 128K |
| GPT-5-mini | $2.50 | $10.00 | 128K |
| Claude Sonnet 4.6 | $3.00 | $15.00 | 200K |
At these prices, Flash is competitive on cost with open-source self-hosting while removing infrastructure overhead. A free tier provides 1 million tokens over 90 days for evaluation.
Strengths
- 1M context window at $0.10/M input - the cheapest long-context frontier API available
- Native multimodal with strong vision benchmarks
- Built-in tool calling and thinking mode
- Batch API with 50% discount for offline workloads
- Context caching reduces repeated prompt costs
Weaknesses
- Not open-weight - can't self-host or fine-tune
- Pricing tiers in China are complex and scale sharply for long prompts
- Less community tooling and framework support compared to OpenAI or Anthropic APIs
- Alibaba Cloud availability may face latency or compliance constraints outside Asia
Related Coverage
- Qwen 3.5 Medium Series Drops Four Models
- Alibaba Drops Qwen3.5: 397B Parameters, 17B Active
- Qwen 3 Review
- Open Source LLM Leaderboard
- Cost Efficiency Leaderboard
Sources:
Last updated

