Qwen3.5-35B-A3B
Qwen3.5-35B-A3B is a 35B-parameter MoE model activating just 3B parameters per token that surpasses the previous Qwen3-235B flagship across language, vision, and agent benchmarks. Apache 2.0 licensed.
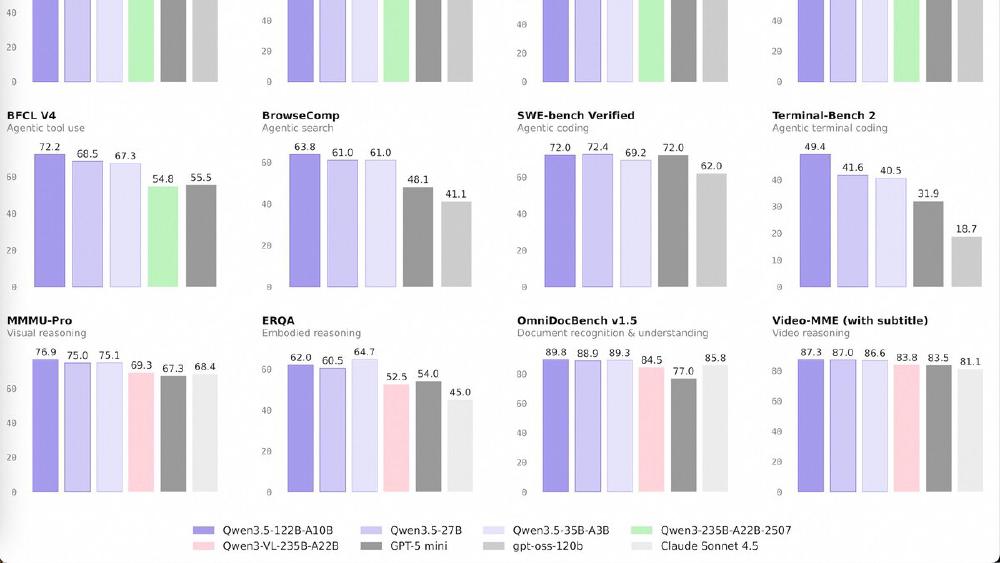
Qwen3.5-35B-A3B is the headline model of the Qwen 3.5 Medium Series. It's a Mixture-of-Experts model with 35 billion total parameters, 256 experts, and only 3 billion parameters active per forward pass. Despite that extreme sparsity, it surpasses both Qwen3-235B-A22B and Qwen3-VL-235B-A22B - the models that were Alibaba's flagships just six months ago.
TL;DR
- 35B total / 3B active MoE model that beats the previous 235B flagship across benchmarks
- Gated DeltaNet hybrid attention (3:1 linear-to-full ratio) with native multimodal (text, image, video)
- 262K native context, extensible to 1M via YaRN - Apache 2.0 license
- Runs on consumer GPUs with quantization - a 3B-active model that posts frontier-class scores
The numbers tell the story better than any marketing copy. A model activating 3 billion parameters - the compute budget of a small local model - now posts MMLU-Pro 85.3, GPQA Diamond 84.2, and TAU2-Bench 81.2 for agent tasks. That last number is a 22.7-point jump over the 235B model's 58.5 on the same benchmark.
Key Specifications
| Specification | Details |
|---|---|
| Provider | Alibaba Cloud (Qwen) |
| Model Family | Qwen 3.5 |
| Architecture | Gated DeltaNet + Sparse MoE |
| Total Parameters | 35B |
| Active Parameters | 3B |
| Layers | 40 |
| Hidden Dimension | 2,048 |
| Experts | 256 total (8 routed + 1 shared per token) |
| Expert FFN Dimension | 512 |
| Attention Pattern | 3:1 (Gated DeltaNet: Full Attention) |
| Context Window | 262,144 tokens (native), ~1M (YaRN extended) |
| Max Output | 65,536 tokens |
| Input Modalities | Text, Image, Video |
| Vocabulary | 248,320 tokens |
| Languages | 201 |
| Training | Multi-step Token Prediction (MTP) |
| Release Date | February 24, 2026 |
| License | Apache 2.0 |
The architecture uses a repeating 4-layer cycle: three Gated DeltaNet layers (linear attention, O(n) scaling with sequence length) followed by one full softmax attention layer (quadratic but providing global context). This hybrid approach enables efficient long-context processing while maintaining the quality that full attention provides.
Benchmark Performance
| Benchmark | Qwen3.5-35B-A3B | Qwen3.5-27B | Qwen3.5-122B-A10B | GPT-5-mini | Qwen3-235B-A22B |
|---|---|---|---|---|---|
| MMLU-Pro | 85.3 | 86.1 | 86.7 | 83.7 | 84.4 |
| GPQA Diamond | 84.2 | 85.5 | 86.6 | 82.8 | 81.1 |
| HMMT Feb 25 | 89.0 | 92.0 | 91.4 | 89.2 | 85.1 |
| SWE-bench Verified | 69.2 | 72.4 | 72.0 | 72.0 | - |
| LiveCodeBench v6 | 74.6 | 80.7 | 78.9 | 80.5 | 75.1 |
| TAU2-Bench (Agent) | 81.2 | 79.0 | 79.5 | 69.8 | 58.5 |
| BrowseComp | 61.0 | 61.0 | 63.8 | 48.1 | - |
| MMMU (Vision) | 81.4 | 82.3 | 83.9 | 79.0 | 80.6 |
| MathVision | 83.9 | 86.0 | 86.2 | 71.9 | 74.6 |
| ScreenSpot Pro | 68.6 | 70.3 | 70.4 | - | 62.0 |
| AndroidWorld | 71.1 | 64.2 | 66.4 | - | 63.7 |
The agent and vision benchmarks are where the 35B-A3B makes its strongest case. TAU2-Bench at 81.2 and AndroidWorld at 71.1 are both best-in-class for this parameter range. On ScreenSpot Pro (GUI grounding), it scores 68.6 versus Claude Sonnet 4.5's 36.2.
The coding benchmarks (SWE-bench 69.2, LiveCodeBench 74.6) are competitive but trail GPT-5-mini and the dense 27B sibling. For pure coding performance, the 27B may be the better choice in the lineup.
Key Capabilities
The 35B-A3B is a natively multimodal model - it processes text, images, and video through the same architecture rather than bolting on a vision adapter. This means it handles document understanding (OCRBench 91.0), GUI interaction (ScreenSpot Pro 68.6), and video comprehension (VideoMME 86.6 with subtitles) in a single model.
With 256 experts and only 8 routed per token plus 1 shared, the inference compute is remarkably low. At 3B active parameters, aggressive quantization (4-bit GPTQ/AWQ) can bring VRAM requirements down to consumer GPU territory. Multi-step Token Prediction (MTP) training enables speculative decoding for faster inference.
The 262K native context extends to roughly 1M tokens via YaRN rope scaling, and the 3:1 DeltaNet-to-attention ratio means most of that context is processed with linear complexity rather than quadratic.
Pricing and Availability
The model is Apache 2.0 licensed and available for download on HuggingFace and ModelScope. There's no API pricing - it's a self-hosted open-weight model.
For those who want a managed API, Qwen3.5-Flash is the production-aligned hosted version at $0.10/M input tokens. The model is also available for testing at Qwen Chat.
Quantized versions are available on HuggingFace for lower VRAM requirements.
Strengths
- 3B active parameters achieve frontier-class results - exceptional compute efficiency
- Best-in-class agent benchmarks (TAU2-Bench 81.2, AndroidWorld 71.1) at this size
- Native multimodal with strong vision (MMMU 81.4, MathVision 83.9, OCR 91.0)
- Apache 2.0 license with 201 language support
- Consumer GPU viable with quantization
Weaknesses
- SWE-bench (69.2) and LiveCodeBench (74.6) trail GPT-5-mini and the dense 27B sibling
- 256-expert MoE can be sensitive to quantization quality
- Full weight matrix (35B) must stay in memory even though only 3B activates
- Gated DeltaNet framework support still maturing in vLLM/SGLang/TensorRT-LLM
- Self-reported benchmarks - independent evaluations pending
Related Coverage
- Qwen 3.5 Medium Series Drops Four Models
- Alibaba's Qwen 3.5 Claims to Beat GPT-5.2
- Qwen 3 Review
- Open Source LLM Leaderboard
- Coding Benchmarks Leaderboard
- Open Source vs Proprietary AI Guide
Sources:
Last updated

