Qwen3.5-27B
Qwen3.5-27B is a 27B dense model that matches GPT-5-mini on SWE-bench (72.4) and posts the best coding and instruction-following scores in the Qwen 3.5 medium lineup. Apache 2.0 licensed.
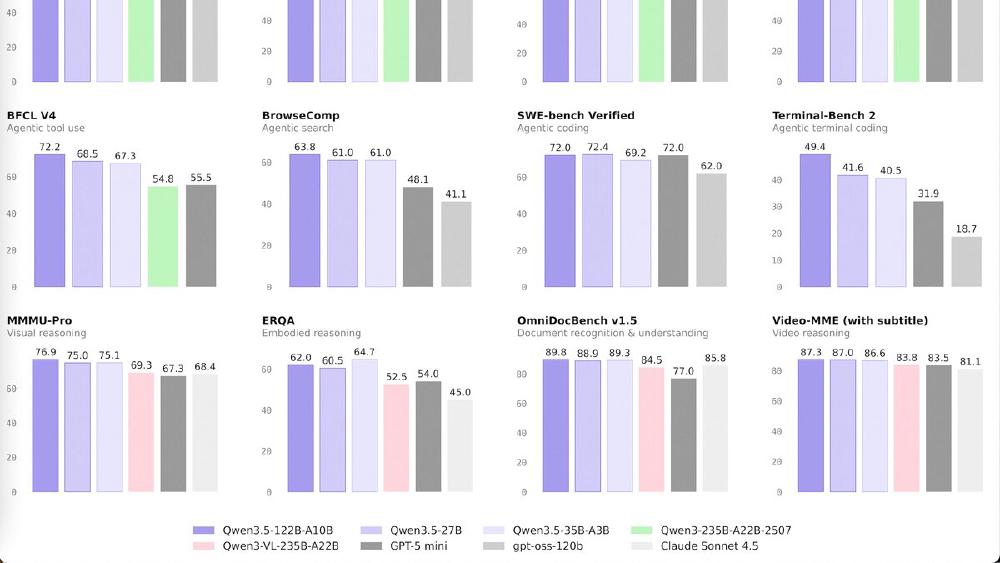
Qwen3.5-27B is the dense model in the Qwen 3.5 Medium Series - the only one that doesn't use Mixture-of-Experts. All 27 billion parameters are active during every forward pass, and the results are remarkably competitive: it matches GPT-5-mini on SWE-bench Verified (72.4) and posts the best instruction-following and coding scores in the entire medium lineup.
TL;DR
- 27B dense model (all params active) - no MoE routing overhead or quantization sensitivity
- SWE-bench 72.4, LiveCodeBench 80.7, IFEval 95.0 - best coding and instruction-following in the medium series
- Same Gated DeltaNet hybrid architecture with native multimodal and 262K-1M context
- Apache 2.0 - fits on a single A100 80GB at BF16, or consumer GPUs with 4-bit quant
The 27B is the workhorse of the lineup. Where the MoE siblings sacrifice some coding performance for compute efficiency, the dense model delivers the best coding benchmarks and the highest instruction-following fidelity (IFEval 95.0, IFBench 76.5) of all four medium models.
Key Specifications
| Specification | Details |
|---|---|
| Provider | Alibaba Cloud (Qwen) |
| Model Family | Qwen 3.5 |
| Architecture | Gated DeltaNet + Dense FFN |
| Total Parameters | 27B |
| Active Parameters | 27B (all) |
| Layers | 64 |
| Hidden Dimension | 4,096 |
| FFN Intermediate Dimension | 17,408 |
| Attention Pattern | 3:1 (Gated DeltaNet: Full Attention) |
| GQA (Full Attention) | 24 Q heads, 4 KV heads |
| Context Window | 262,144 tokens (native), ~1M (YaRN extended) |
| Max Output | 65,536 tokens |
| Input Modalities | Text, Image, Video |
| Vocabulary | 248,320 tokens |
| Languages | 201 |
| Training | Multi-step Token Prediction (MTP) |
| Release Date | February 24, 2026 |
| License | Apache 2.0 |
The 27B uses the deepest layer stack (64 layers) and widest hidden dimension (4,096) of the three open models. Instead of expert routing, it uses standard FFN layers with 17,408 intermediate dimension. This makes it the simplest to deploy - no MoE-specific kernel optimizations needed - and the most predictable in terms of quality under quantization.
Benchmark Performance
| Benchmark | Qwen3.5-27B | Qwen3.5-122B-A10B | Qwen3.5-35B-A3B | GPT-5-mini |
|---|---|---|---|---|
| MMLU-Pro | 86.1 | 86.7 | 85.3 | 83.7 |
| GPQA Diamond | 85.5 | 86.6 | 84.2 | 82.8 |
| IFEval | 95.0 | 93.4 | 91.9 | 93.9 |
| IFBench | 76.5 | 76.1 | 70.2 | 75.4 |
| HMMT Feb 25 | 92.0 | 91.4 | 89.0 | 89.2 |
| SWE-bench Verified | 72.4 | 72.0 | 69.2 | 72.0 |
| LiveCodeBench v6 | 80.7 | 78.9 | 74.6 | 80.5 |
| DynaMath | 87.7 | 85.9 | 85.0 | 81.4 |
| TAU2-Bench (Agent) | 79.0 | 79.5 | 81.2 | 69.8 |
| MMMU (Vision) | 82.3 | 83.9 | 81.4 | 79.0 |
| MathVision | 86.0 | 86.2 | 83.9 | 71.9 |
| MathVista (mini) | 87.8 | 87.4 | 86.2 | 79.1 |
| VITA-Bench (Video) | 41.9 | 33.6 | 31.9 | 13.9 |
| ScreenSpot Pro | 70.3 | 70.4 | 68.6 | - |
The 27B leads the medium series on coding (SWE-bench 72.4, LiveCodeBench 80.7), instruction following (IFEval 95.0), math (HMMT 92.0, DynaMath 87.7), and video understanding (VITA-Bench 41.9). The VITA-Bench result is especially striking - 41.9 versus 13.9 for GPT-5-mini, nearly triple the score.
On knowledge-heavy tasks (GPQA, MMLU-Pro, MMMU), the 122B-A10B holds a small edge. On agent tasks (TAU2-Bench), the 35B-A3B leads. But for coding and instruction following, the 27B is clearly the best choice.
Key Capabilities
The dense architecture makes the 27B the most deployment-friendly model in the lineup. At BF16, it requires roughly 54GB VRAM - fitting on a single A100 80GB with room for context. With 4-bit quantization (GPTQ/AWQ), it drops to roughly 14GB - viable on a RTX 4090 or even a RTX 3090 24GB. Seven quantized variants are already available on HuggingFace.
Because there's no expert routing, the 27B avoids the MoE-specific pitfalls: no load balancing issues, no quantization sensitivity from sparse expert activation, and no dependency on MoE-aware inference frameworks. Standard inference engines (vLLM, llama.cpp, Ollama) handle dense models more maturely than sparse MoE models.
The VITA-Bench score (41.9) and VideoMME (87.0 with subtitles) indicate strong video understanding, likely benefiting from the deeper 64-layer architecture's ability to process longer temporal sequences in video inputs.
Pricing and Availability
Apache 2.0 licensed and available on HuggingFace and ModelScope. Seven quantized versions are available. The model can be tested at Qwen Chat.
| Deployment Option | VRAM Required | Notes |
|---|---|---|
| BF16 (full precision) | ~54GB | Single A100 80GB |
| 8-bit quantization | ~27GB | A100 40GB or 2x RTX 4090 |
| 4-bit quantization | ~14GB | RTX 4090, RTX 3090 24GB |
For those who want to compare hosting costs against a managed API, the Qwen3.5-Flash API runs $0.10/$0.40 per million tokens but is aligned with the smaller 35B-A3B rather than the 27B dense model. DeepSeek V3.2 at $0.14/$0.28 is the closest API competitor in price-performance.
Strengths
- Best coding model in the medium series - SWE-bench 72.4 matches GPT-5-mini
- IFEval 95.0 - highest instruction following fidelity, critical for production reliability
- Dense architecture simplifies deployment - no MoE kernel requirements
- Quantization-friendly: 7 quant variants, runs on consumer GPUs at 4-bit
- VITA-Bench 41.9 - nearly 3x GPT-5-mini on video understanding
- 64 layers provide deep reasoning (HMMT 92.0, DynaMath 87.7)
Weaknesses
- All 27B parameters active every forward pass - higher inference cost per token than 35B-A3B (3B active)
- Knowledge benchmarks (GPQA, MMMU) slightly trail the 122B-A10B
- Agent tasks (TAU2-Bench 79.0) trail the 35B-A3B's 81.2
- No managed API specifically aligned with this model
- Self-reported benchmarks - independent validation pending
Related Coverage
- Qwen 3.5 Medium Series Drops Four Models
- Qwen3.5: 397B Parameters, 17B Active
- Qwen 3 Review
- Open Source LLM Leaderboard
- Coding Benchmarks Leaderboard
- How to Choose an LLM in 2026
Sources:
Last updated

