Qwen3.5-122B-A10B
Qwen3.5-122B-A10B is a 122B-parameter MoE model activating 10B parameters per token, narrowing the gap between medium and frontier models with top scores in GPQA Diamond (86.6), MMMU (83.9), and OCRBench (92.1). Apache 2.0 licensed.
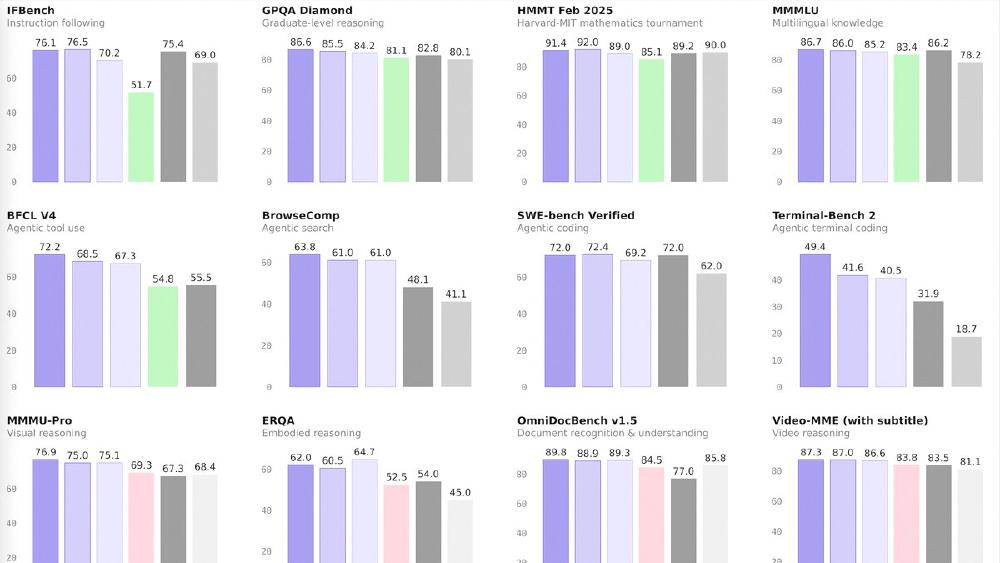
Qwen3.5-122B-A10B is the largest open-weight model in the Qwen 3.5 Medium Series. It packs 122 billion total parameters with 256 experts, routing to 10 billion active parameters per token. It's the strongest of the three open models across most benchmarks, especially on knowledge-heavy and vision tasks, and narrows the gap with the 397B flagship to single-digit percentages on most evaluations.
TL;DR
- 122B total / 10B active MoE model - the strongest open-weight model in the Qwen 3.5 medium lineup
- GPQA Diamond 86.6, MMMU 83.9, OCRBench 92.1 - top scores across the medium series
- Gated DeltaNet hybrid architecture with native multimodal and 262K-1M context
- Apache 2.0 - requires multi-GPU setup but delivers near-flagship performance
The 122B sits in a specific position: it requires more hardware than the 35B-A3B but delivers the best raw scores in the medium lineup. On GPQA Diamond (86.6), it beats GPT-5-mini (82.8) by nearly 4 points. On OCRBench (92.1) and OmniDocBench (89.8), it leads the entire field including closed-source APIs.
Key Specifications
| Specification | Details |
|---|---|
| Provider | Alibaba Cloud (Qwen) |
| Model Family | Qwen 3.5 |
| Architecture | Gated DeltaNet + Sparse MoE |
| Total Parameters | 122B |
| Active Parameters | 10B |
| Layers | 48 |
| Hidden Dimension | 3,072 |
| Experts | 256 total (8 routed + 1 shared per token) |
| Expert FFN Dimension | 1,024 |
| Attention Pattern | 3:1 (Gated DeltaNet: Full Attention) |
| GQA (Full Attention) | 32 Q heads, 2 KV heads |
| Context Window | 262,144 tokens (native), ~1M (YaRN extended) |
| Max Output | 65,536 tokens |
| Input Modalities | Text, Image, Video |
| Vocabulary | 248,320 tokens |
| Languages | 201 |
| Training | Multi-step Token Prediction (MTP) |
| Release Date | February 24, 2026 |
| License | Apache 2.0 |
The architecture scales up from the 35B by increasing hidden dimension (3,072 vs 2,048), adding 8 more layers (48 vs 40), and doubling the expert FFN dimension (1,024 vs 512). The expert count and routing remain identical: 256 total experts, 8 routed + 1 shared.
Benchmark Performance
| Benchmark | Qwen3.5-122B-A10B | Qwen3.5-35B-A3B | Qwen3.5-27B | GPT-5-mini | Claude Sonnet 4.5 |
|---|---|---|---|---|---|
| MMLU-Pro | 86.7 | 85.3 | 86.1 | 83.7 | - |
| GPQA Diamond | 86.6 | 84.2 | 85.5 | 82.8 | - |
| SuperGPQA | 67.1 | 63.4 | 65.6 | 58.6 | - |
| HLE w/ CoT | 25.3 | 22.4 | 24.3 | 19.4 | - |
| SWE-bench Verified | 72.0 | 69.2 | 72.4 | 72.0 | - |
| LiveCodeBench v6 | 78.9 | 74.6 | 80.7 | 80.5 | - |
| CodeForces | 2100 | 2028 | 1899 | 2160 | - |
| TAU2-Bench (Agent) | 79.5 | 81.2 | 79.0 | 69.8 | - |
| BrowseComp | 63.8 | 61.0 | 61.0 | 48.1 | - |
| BFCL-V4 (Function) | 72.2 | 67.3 | 68.5 | 55.5 | - |
| MMMU (Vision) | 83.9 | 81.4 | 82.3 | 79.0 | 79.6 |
| MathVision | 86.2 | 83.9 | 86.0 | 71.9 | 71.1 |
| OCRBench | 92.1 | 91.0 | 89.4 | 82.1 | 76.6 |
| OmniDocBench 1.5 | 89.8 | 89.3 | 88.9 | 77.0 | 85.8 |
| ScreenSpot Pro | 70.4 | 68.6 | 70.3 | - | 36.2 |
The 122B leads on knowledge benchmarks (GPQA, SuperGPQA, HLE), vision tasks (MMMU, MathVision, OCR), and function calling (BFCL-V4 72.2 vs GPT-5-mini's 55.5). Worth noting: the dense 27B beats it on coding (LiveCodeBench, SWE-bench) and the 35B-A3B beats it on agent tasks (TAU2-Bench).
Key Capabilities
The 122B-A10B excels at knowledge-intensive and document understanding tasks. The OCRBench score of 92.1 and OmniDocBench 89.8 make it the strongest document processing model in the open-weight space. Combined with ScreenSpot Pro 70.4 (versus Claude Sonnet 4.5's 36.2), it's a strong candidate for GUI automation and document extraction pipelines.
The BFCL-V4 function calling score of 72.2 - versus 55.5 for GPT-5-mini - shows strong structured output and tool-use capabilities. This, combined with BrowseComp 63.8, makes the 122B a compelling base for agentic applications that require both reasoning depth and reliable function execution.
The 48-layer architecture with 16 cycles of the DeltaNet-attention hybrid provides deep reasoning capacity. On HLE (Humanity's Last Exam) with chain-of-thought, it scores 25.3 - the highest in the medium series and clearly above GPT-5-mini's 19.4.
Pricing and Availability
Apache 2.0 licensed and available on HuggingFace and ModelScope. Available for testing at Qwen Chat.
While only 10B parameters activate per token, the full 122B weight matrix must reside in memory. At BF16 precision, that requires about 244GB of VRAM - a multi-GPU deployment on A100 80GB (3-4 GPUs) or equivalent. Quantization to 4-bit reduces this to roughly 60-70GB, viable on two A100s or a single A100 80GB with aggressive optimization.
For managed API access, Qwen3.5-Flash at $0.10/M input is the hosted option, though it aligns with the smaller 35B-A3B rather than the 122B.
Strengths
- Strongest knowledge and vision benchmarks in the open-weight medium class
- BFCL-V4 72.2 - best function calling in the lineup, far ahead of GPT-5-mini
- OCRBench 92.1 and OmniDocBench 89.8 - best-in-class document understanding
- HLE 25.3 - deepest reasoning of the medium models
- Apache 2.0 with 201 language support
Weaknesses
- 122B total params require multi-GPU infrastructure even with only 10B active
- Coding benchmarks (SWE-bench 72.0, LiveCodeBench 78.9) trail the dense 27B sibling
- TAU2-Bench 79.5 trails the smaller 35B-A3B's 81.2 on agent tasks
- Framework support for Gated DeltaNet still maturing
- Self-reported benchmarks - independent validation pending
Related Coverage
- Qwen 3.5 Medium Series Drops Four Models
- Qwen3.5: 397B Parameters, 17B Active
- Qwen 3 Review
- Open Source LLM Leaderboard
- Coding Benchmarks Leaderboard
Sources:
Last updated

