
Veo 3.1
Google DeepMind's Veo 3.1 generates 4K video with native audio and is now free for every Google account at 10 clips per month via Google Vids.
They summarize our coverage. We write it.
Newsletters like this one rebroadcast our headlines - often without the full review, the source reading, or the analysis underneath. Our weekly briefing sends the work they paraphrase, straight from the desk, before they get to it.
Free, weekly, no spam. One email every Tuesday. Unsubscribe anytime.
Google DeepMind's Veo 3.1 generates 4K video with native audio and is now free for every Google account at 10 clips per month via Google Vids.

Alibaba's first closed-weights flagship Qwen ships with a 256K context window, tops six agentic coding benchmarks, and ranks third on the Artificial Analysis Intelligence Index.
OpenAI's first domain-specific reasoning model for biology and drug discovery, launched April 16 2026 as a US-only research preview with a 0.751 BixBench score.

Moonshot AI's Kimi K2.6 is a 1T-parameter MoE with 32B active per token, 256K context, a 300-agent swarm running 4,000 coordinated steps, and the top SWE-Bench Pro score among open-weight models at 58.6%.

Arcee Trinity-Large-Thinking is a 400B sparse MoE open-source reasoning model that ranks #2 on PinchBench at $0.85/M output tokens, 28x cheaper than Claude Opus 4.6.
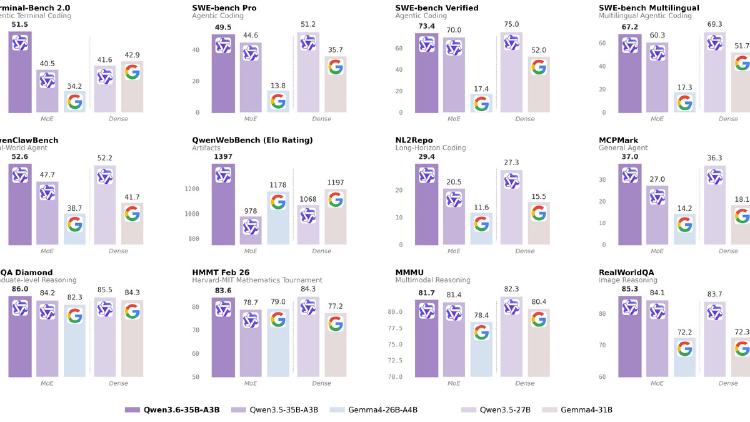
Alibaba's 35B sparse MoE with 3B active parameters delivers 73.4% SWE-bench Verified, multimodal vision and video, 256K context, and DeltaNet hybrid architecture under Apache 2.0.
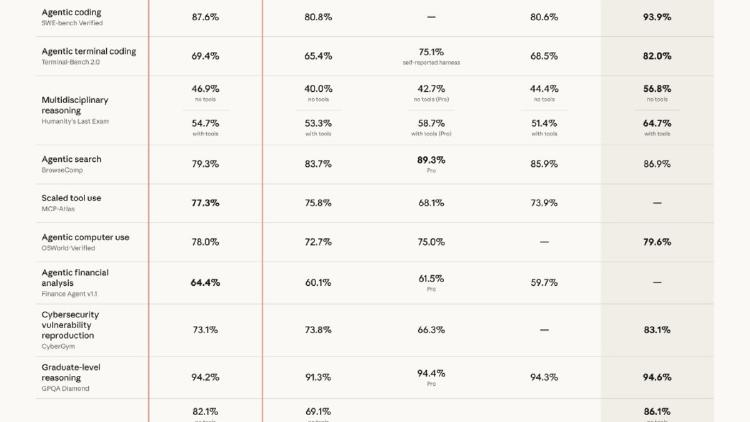
Anthropic's latest flagship model ships with 3x higher resolution vision, a new xhigh effort level, task budgets for cost control, cyber safeguards, and 13% better coding performance at the same $5/$25 pricing.

Claude Mythos Preview is Anthropic's most capable model - restricted to 50 orgs via Project Glasswing, with 93.9% on SWE-bench Verified and thousands of autonomous zero-day discoveries.

Microsoft's production-focused image generation model - 41% cheaper and 22% faster than MAI-Image-2, optimized for high-volume enterprise workflows.

NVIDIA Ising is the world's first open AI model family for quantum computing - a 35B MoE VLM for quantum processor calibration and 3D CNN decoders for real-time surface code error correction.

Meta's first closed-source frontier model scores 52 on the Artificial Analysis Intelligence Index, leads on HealthBench Hard, and ships free at meta.ai - but has no public API yet.

Gemma 4 is Google DeepMind's most capable open model family: four variants from 2B to 31B, Apache 2.0 license, multimodal across text/image/video/audio, and the 31B Dense ranking #3 on Chatbot Arena against all open-weight models globally.