
Llama 4 Maverick
Meta's Llama 4 Maverick packs 400B total parameters into a 128-expert MoE architecture with only 17B active per token, beating GPT-4o on Chatbot Arena while matching DeepSeek V3 on reasoning at half the active parameters.
Meta's Llama 4 Maverick packs 400B total parameters into a 128-expert MoE architecture with only 17B active per token, beating GPT-4o on Chatbot Arena while matching DeepSeek V3 on reasoning at half the active parameters.

Meta's Llama 4 Scout is a 109B-total, 17B-active MoE model with 16 experts and a 10M-token context window - the longest of any open-weight model - with native multimodal support for text and images.

Microsoft's 14B dense transformer that consistently beats models 5x its size on MATH and GPQA, available under the MIT license for unrestricted commercial use.

Mistral Large 3 is a 675B-parameter MoE model activating 41B per token with native multimodal support, a 256K context window, and Apache 2.0 licensing - Europe's first frontier-class open-weight model.

Mistral Small 3.2 is a 24B dense model with strong function calling, multimodal vision, and 128K context under Apache 2.0 - optimized for production tool-use pipelines and EU-compliant deployments.
NVIDIA's hybrid Mamba2+MoE model packs 31.6B total parameters but activates only 3.2B per token, delivering frontier-class reasoning with 3.3x the throughput of comparable models on a single H200 GPU.

MiniMax M2.5 is a 230B MoE model (10B active) that scores 80.2% on SWE-Bench Verified while costing 1/10th to 1/20th of frontier competitors like Claude Opus 4.6 and GPT-5.2.
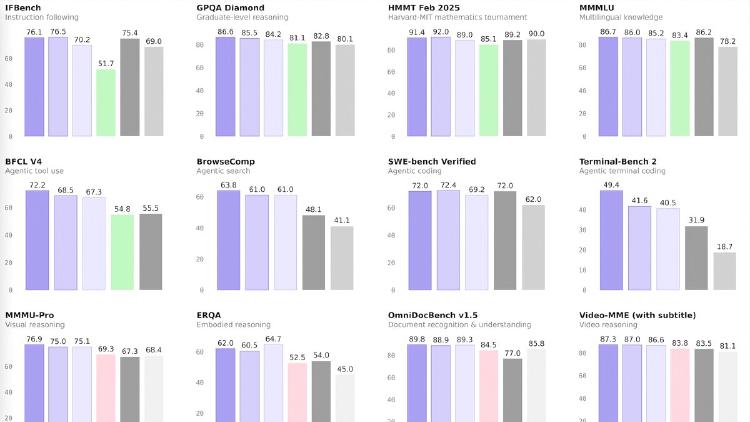
Qwen3.5-122B-A10B is a 122B-parameter MoE model activating 10B parameters per token, narrowing the gap between medium and frontier models with top scores in GPQA Diamond (86.6), MMMU (83.9), and OCRBench (92.1). Apache 2.0 licensed.
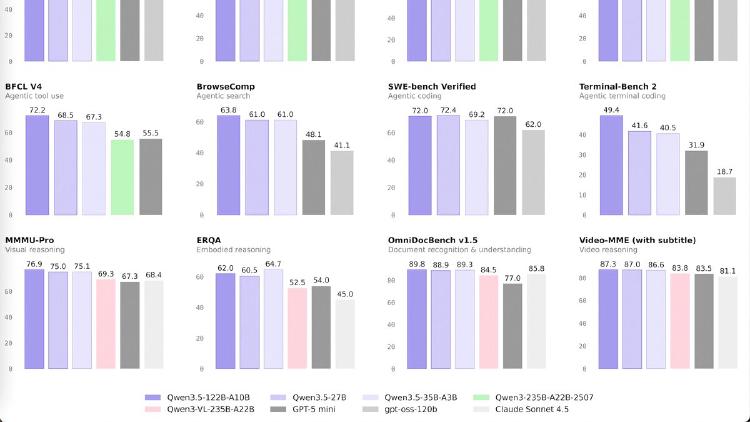
Qwen3.5-27B is a 27B dense model that matches GPT-5-mini on SWE-bench (72.4) and posts the best coding and instruction-following scores in the Qwen 3.5 medium lineup. Apache 2.0 licensed.
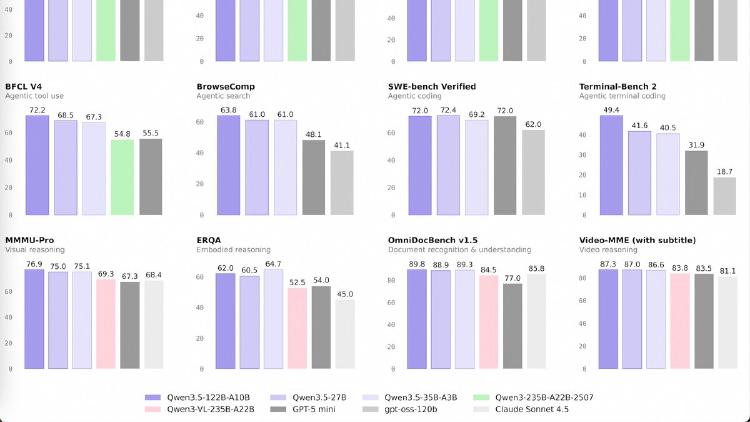
Qwen3.5-35B-A3B is a 35B-parameter MoE model activating just 3B parameters per token that surpasses the previous Qwen3-235B flagship across language, vision, and agent benchmarks. Apache 2.0 licensed.
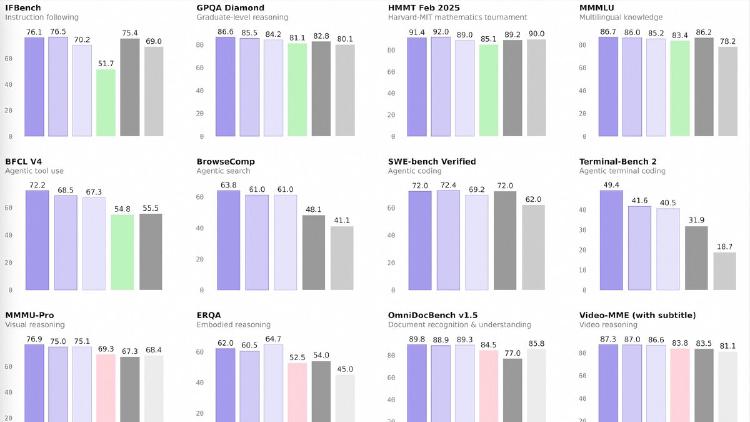
Qwen3.5-Flash is Alibaba's hosted production model with 1M context, built-in tools, and multimodal support at $0.10/M input tokens - one of the cheapest frontier-tier APIs available.

Anthropic's flagship model leads on agentic coding, enterprise knowledge work, and long-context retrieval with a 1M-token window, 128K output, and agent teams at $5/$25 per million tokens.
