NVIDIA Nemotron 3 Ultra 550B-A55B
NVIDIA's 550B open-weight MoE model with 55B active parameters, hybrid Mamba-Transformer architecture, and 1M token context - the top-scoring US open model on the Artificial Analysis Intelligence Index.

NVIDIA's Nemotron 3 Ultra is the largest model in the Nemotron 3 family - 550 billion total parameters with only 55 billion active per forward pass. Announced by Jensen Huang at Computex on June 1, 2026 and released four days later, it's the highest-scoring US-origin open-weight model on the Artificial Analysis Intelligence Index, sitting at 48 points.
TL;DR
- Top US open-weight model on intelligence benchmarks (48 on AA Intelligence Index), optimized for long-running agentic workflows
- 550B total / 55B active MoE; 262K context in BF16, 1M tokens in NVFP4 on Blackwell; $0.50/$2.50 per million tokens on OpenRouter
- Beats every US open model on intelligence but trails Kimi K2.6 (54) from Moonshot AI; compensates with 5.9x higher throughput than GLM-5.1
Overview
The Ultra joins two smaller Nemotron 3 siblings - Nemotron 3 Super 120B-A12B and Nemotron 3 Nano 30B-A3B - as the flagship of the family. Where Super was optimized for a single-node H200 setup, Ultra targets multi-node Blackwell clusters and data-center-grade inference. The architecture stays the same hybrid Mamba-Transformer-MoE design, but scaled up considerably and retrained with an expanded post-training pipeline.
NVIDIA positions it specifically for autonomous agents: long-horizon planning, multi-step tool use, and tasks where context builds up over many turns. The 1 million token context (in NVFP4 quantization on Blackwell hardware) and a 95% score on the RULER 1M benchmark back that up. The model's non-hallucination score on AA-Omniscience is 78.7%, the best in its comparison set.
The competitive story is nuanced. Ultra is unambiguously the best US-origin open model right now. But Kimi K2.6 from Moonshot AI scores 54 on the same Intelligence Index compared to Ultra's 48. NVIDIA's counter-argument is throughput: Ultra delivers over 300 tokens per second on a pre-release DeepInfra endpoint - roughly 5-6x faster than the Chinese frontier open models, and 30% lower cost per completed benchmark task.
Key Specifications
| Specification | Details |
|---|---|
| Provider | NVIDIA |
| Model Family | Nemotron 3 |
| Parameters | 550B total / 55B active |
| Context Window | 262K tokens (BF16); 1M tokens (NVFP4 on Blackwell) |
| Input Price | $0.50/M tokens (OpenRouter) |
| Output Price | $2.50/M tokens (OpenRouter) |
| Release Date | June 4, 2026 |
| License | OpenMDW-1.1 (Linux Foundation permissive, commercial use permitted) |
| Architecture | Hybrid Mamba-2 + Transformer + LatentMoE |
| Training Data | ~20 trillion tokens (pretraining) |
| Knowledge Cutoff | September 2025 (pretraining); May 2026 (SFT) |
| Min. Hardware | 8x GB200/B200/GB300/B300, or 16x H100, or 8x H200 |
Benchmark Performance
The table below compares Ultra against its nearest open-weight competitors using numbers from the Hugging Face model card and the Artificial Analysis Intelligence Index.
| Benchmark | Nemotron 3 Ultra 550B | Kimi K2.6 1T | Nemotron 3 Super 120B |
|---|---|---|---|
| AA Intelligence Index | 48 | 54 | 36 |
| MMLU-Pro | 86.8 | Not published | - |
| GPQA Diamond (no tools) | 87.0 | Leads on GPQA | - |
| SWE-Bench Verified | 65.0 - 70.4% | - | - |
| LiveCodeBench v6 | 89.0 | - | - |
| IFBench (prompt loose) | 81.7 | - | - |
| RULER @ 1M tokens | 94.7% | - | - |
| TauBench Average | 70.9 | - | - |
| PinchBench Agent Productivity | 90.0% | - | - |
| Output speed (tokens/sec) | 141 (AA) / 300+ (DeepInfra) | ~50-100 | - |
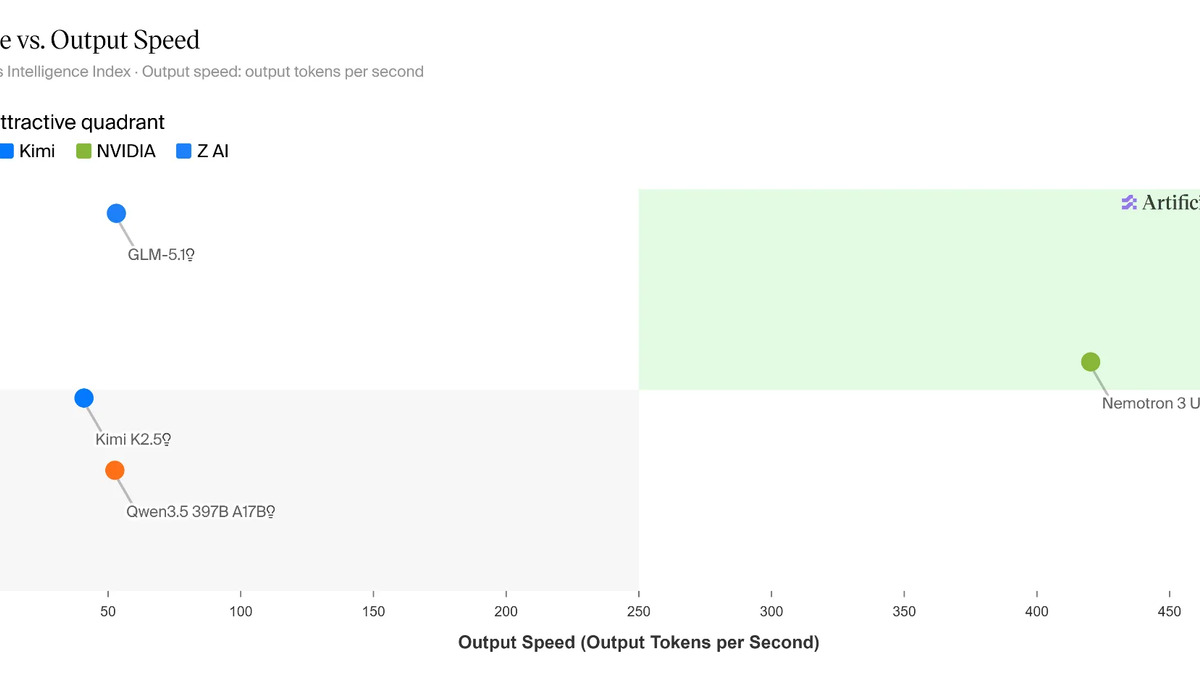 NVIDIA's throughput comparison shows Ultra at 5.9x higher output than GLM-5.1-754B and 4.8x higher than Kimi K2.6 on 8K input / 64K output sequences.
Source: developer.nvidia.com
NVIDIA's throughput comparison shows Ultra at 5.9x higher output than GLM-5.1-754B and 4.8x higher than Kimi K2.6 on 8K input / 64K output sequences.
Source: developer.nvidia.com
The numbers need context. Ultra's GPQA Diamond score of 87.0 is measured without tools. NVIDIA reports Kimi K2.6 leads on GPQA when evaluated under the same conditions, which is why the overall Intelligence Index favors K2.6 by six points.
The SWE-Bench Verified range (65% to 70.4%) spans five different agent harnesses: Pi, OpenHands, Hermes, OpenCode, and Mini SWE Agent. The spread reflects harness overhead rather than model variance. See the SWE-Bench leaderboard for current rankings across all models.
On agentic tasks, Ultra completed benchmarks using fewer total tokens per turn than comparable models, which is what drives that 30% lower cost-per-task metric. That's a relevant signal for workloads billed by output tokens.
Key Capabilities
Architecture: LatentMoE and Why It Matters
The core architectural innovation is LatentMoE. Standard MoE models route tokens to experts and run computation at full hidden dimension. LatentMoE projects tokens into a smaller latent space before expert routing and computation, then projects back out. The result: more experts activated per token at the same inference cost. Ultra routes to 22 experts per token from a pool of 512 total.
The Mamba-2 layers handle long sequences with sub-quadratic memory scaling, which is why the 1M context is practical rather than theoretical. A small number of attention layers are kept for precise recall tasks where Mamba layers alone would lose detail.
Multi-Token Prediction (MTP) layers sit on top of the main stack. During training, they provide richer gradient signal. At inference, they enable speculative decoding out of the box with no separate draft model required - the vLLM deployment example in the model card uses "method": "nemotron_h_mtp", "num_speculative_tokens": 5 to activate it.
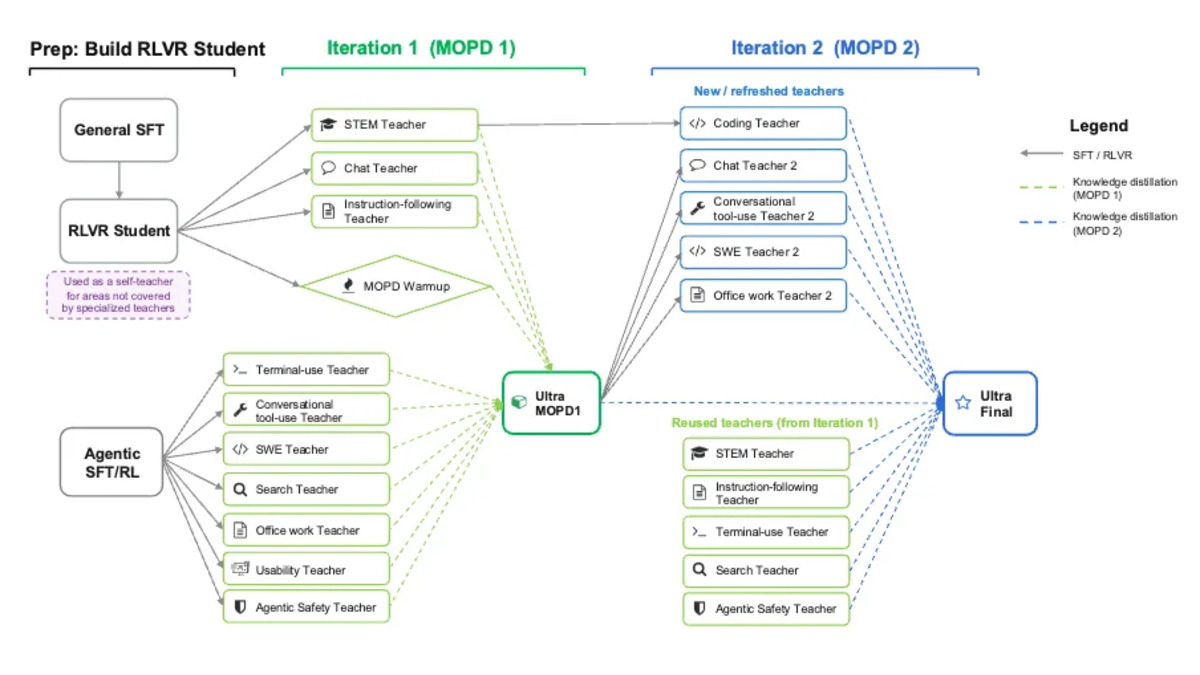 Multi-teacher On-Policy Distillation (MOPD) trains Ultra using 10+ specialized teacher models across domains, with asynchronous pipelined execution.
Source: developer.nvidia.com
Multi-teacher On-Policy Distillation (MOPD) trains Ultra using 10+ specialized teacher models across domains, with asynchronous pipelined execution.
Source: developer.nvidia.com
Post-Training Pipeline
Ultra went through four explicit stages after pretraining: SFT, reinforcement learning (asynchronous GRPO across 55 RL environments), and then Multi-Domain On-Policy Distillation (MOPD). The MOPD stage is remarkable. Rather than distilling from a single large teacher, NVIDIA used 10+ specialized teacher models and ran them asynchronously while training - teachers and student co-evolving domain by domain. The legal benchmark jumped from 64.6% to 74.7% on LegalBench after 4 billion tokens of targeted legal domain data.
Agentic Workflow Support
Ultra supports tool calling natively via the qwen3_coder parser format and is compatible with Hermes Agent, CrewAI, OpenHands, LangChain, Pi, and over 15 other frameworks. Reasoning can be toggled on or off through the chat template, which matters for latency-sensitive tasks that don't need chain-of-thought.
The TauBench scores (81.5 airline, 86.4 retail, 92.9 telecom, 22.6 banking) reveal the one weak spot clearly: structured banking workflows. That low score likely reflects domain knowledge gaps rather than general reasoning failure, but it's a real constraint for fintech applications.
Pricing and Availability
OpenRouter lists Ultra at $0.50/M input and $2.50/M output tokens. There's also a free-tier variant (nvidia/nemotron-3-ultra-550b-a55b:free) for low-volume use. Artificial Analysis computes a blended rate of ~$0.52/M at a typical usage mix, with cache hits discounted roughly two-thirds against input price.
NVIDIA NIM (build.nvidia.com) provides 1,000 free inference credits on signup at 40 requests per minute - enough for meaningful prototyping before committing to deployment.
Open weights are available on Hugging Face in two variants: BF16 (nvidia/NVIDIA-Nemotron-3-Ultra-550B-A55B-BF16) for maximum accuracy and NVFP4 (nvidia/NVIDIA-Nemotron-3-Ultra-550B-A55B-NVFP4) for throughput on Blackwell hardware. A GenRM variant (nvidia/NVIDIA-Nemotron-3-Ultra-550B-A55B-GenRM) ships separately for reward modeling use cases.
Self-hosting requires real hardware. Full BF16 inference needs 16x H100s or 8x H200s at minimum. The NVFP4 variant runs on 8x GB200/B200s. NVIDIA provides NIM containers for both vLLM and SGLang with ready-to-use launch commands in the model card.
Beyond OpenRouter and NIM, day-one availability covered Perplexity Pro, Amazon SageMaker JumpStart, Google Cloud, Microsoft Azure Foundry, Oracle Cloud, Together AI, Fireworks AI, DeepInfra, and Anaconda.
Ultra's throughput advantage - 5.9x over GLM-5.1 and 4.8x over Kimi K2.6 - makes the cost-per-task gap larger than the raw intelligence gap suggests.
Strengths and Weaknesses
Strengths
- Highest intelligence score of any US-origin open-weight model (48 on AA Intelligence Index)
- Best-in-class long context: 94.7% on RULER @ 1M tokens
- Fastest open frontier model: 300+ tokens/sec on DeepInfra, 141 t/s on AA median
- Native speculative decoding via MTP layers - no draft model needed
- Broad day-one deployment coverage across major cloud and inference platforms
- OpenMDW-1.1 license allows commercial use globally
- Configurable reasoning mode (on/off via chat template) for latency control
- 10-language support with strong multilingual instruction following
Weaknesses
- Intelligence gap with Chinese open models: Kimi K2.6 scores 54 vs Ultra's 48 on the AA Index
- TauBench Banking drops to 22.6 - well below other TauBench domains
- Self-hosting requires 8x H200 or better; not accessible on consumer hardware
- BF16 context window is 262K, not 1M - the full million requires NVFP4 on Blackwell specifically
- SWE-Bench range (65-70.4%) trails some specialized coding models in the coding benchmarks leaderboard
Related Coverage
- NVIDIA Ships Nemotron 3 Super - 120B Open Model for Agents - earlier Nemotron 3 family member
- Kimi K2.6 - current global open-weight intelligence leader at 54 on the AA Index
- SWE-Bench coding agent leaderboard - full SWE-Bench rankings across all models
- Agentic AI benchmarks leaderboard - broader agentic model comparisons
FAQ
What is Nemotron 3 Ultra best at?
Long-context agentic workflows and instruction following. It scores 94.7% on RULER at 1M tokens, 81.7% on IFBench, and 90% on PinchBench agent productivity - making it strong for multi-step tool use and RAG over large document sets.
How does Nemotron 3 Ultra compare to Kimi K2.6?
Kimi K2.6 leads on raw intelligence (54 vs 48 on the AA Intelligence Index) and GPQA Diamond. Ultra leads on throughput - 5.9x higher output tokens per second at the same GPU count - and costs roughly 30% less per completed benchmark task.
Can I run Nemotron 3 Ultra locally?
Only with datacenter hardware. BF16 inference requires at minimum 16x H100-80GB or 8x H200. The NVFP4 variant needs 8x GB200/B200/GB300/B300. There's no consumer-grade path for a 550B model.
Is Nemotron 3 Ultra commercially licensed?
Yes. The OpenMDW-1.1 license from the Linux Foundation permits commercial use globally with no geographic restrictions.
What context window does it support?
262K tokens in BF16 precision on any supported GPU. Up to 1M tokens when running the NVFP4 variant on Blackwell (GB200/B200/GB300/B300) hardware.
How do I access it without downloading 550B weights?
Try NVIDIA NIM at build.nvidia.com (1,000 free credits), OpenRouter ($0.50/$2.50 per million tokens), or the free tier on OpenRouter. Perplexity Pro also includes access.
Sources:
✓ Last verified June 6, 2026
