NVIDIA Cosmos 3
NVIDIA Cosmos 3 is an open physical AI omnimodel with Mixture-of-Transformers architecture that natively handles text, images, video, sound, and robot actions in a single 16B or 64B model.

NVIDIA launched Cosmos 3 today at GTC Taipei during Computex 2026, calling it the world's first fully open physical AI omnimodel. Unlike previous world models that handled either reasoning or generation, Cosmos 3 does both natively in a single architecture - taking in text, images, video, audio, and robot action data, and creating all those same modalities as output. That's the actual news: not just another video model, but a unified system designed to give robots and autonomous vehicles a physics-grounded brain.
TL;DR
- First open model to unify vision reasoning, world generation, and robot action prediction in one architecture
- Comes in two sizes now: Nano (16B, runs on RTX PRO 6000) and Super (64B, requires Hopper/Blackwell datacenter GPUs)
- Tops open-model rankings across Physics-IQ, PAI-Bench, R-Bench, RoboLab, RoboArena, VANTAGE-Bench, and TAR leaderboards at launch
The model's design reflects a specific engineering bet: that physical AI needs a single system capable of understanding a scene, predicting what comes next, and generating a robot action path - in one forward pass. Cosmos 3 handles all of that through what NVIDIA calls a Mixture-of-Transformers (MoT) architecture, pairing an autoregressive Reasoner tower with a diffusion-based Generator tower.
Industrial adopters are already on board. LG Electronics, Samsung, and Doosan Robotics are using it for robotics applications. Li Auto is working with it for autonomous vehicle scenarios. Centific, Milestone Systems, and others are building factory and smart-space vision AI on top of it. The Cosmos Coalition - Agile Robots, Black Forest Labs, Generalist, LTX, Runway, and Skild AI - is contributing to the open ecosystem.
 NVIDIA's Cosmos 3 announcement at GTC Taipei, Computex 2026.
Source: nvidianews.nvidia.com
NVIDIA's Cosmos 3 announcement at GTC Taipei, Computex 2026.
Source: nvidianews.nvidia.com
Key Specifications
| Specification | Details |
|---|---|
| Provider | NVIDIA |
| Model Family | Cosmos |
| Architecture | Mixture-of-Transformers (MoT) - Reasoner + Generator towers |
| Parameters | 16B (Nano) / 64B (Super) |
| Context Window | 256K tokens (Reasoner); 4,096 tokens (Generator text input) |
| Input Modalities | Text, image, video (up to 720p), audio (stereo 48kHz), robot actions (JSON) |
| Output Modalities | Text, image, video (up to 400 frames), audio, robot actions |
| Input Price | Not disclosed |
| Output Price | Not disclosed |
| Release Date | June 1, 2026 |
| License | OpenMDW 1.1 (Linux Foundation) |
| Availability | Hugging Face, GitHub, build.nvidia.com, NVIDIA NIM microservices |
The parameter counts reflect total model size: Nano's 16B splits between a 8B Reasoner and a 8B Generator. Super's 64B follows the same 32B+32B split. Training data ran to 1.3 billion data points across 393 datasets - text (22M), image (767M), video (348M), audio (139M), and action trajectories (8M). Six synthetic datasets released with the model cover robotics manipulation, physics simulation, spatial reasoning, human motion, autonomous driving, and warehouse operations.
Benchmark Performance
NVIDIA reports Cosmos 3 ranks first among open models across every benchmark it entered at launch:
| Benchmark | What It Tests | Cosmos 3 Standing |
|---|---|---|
| Physics-IQ | Physical plausibility in generated video | #1 open model |
| PAI-Bench | Physical AI generation accuracy | #1 open model |
| R-Bench | Real-world video generation quality | #1 open model |
| VANTAGE-Bench (32B tier) | Vision-language on fixed-camera industrial footage | #1 (Super) |
| VANTAGE-Bench (8B tier) | Same, compact scale | #1 (Nano) |
| RoboLab | Simulation policy across language-guided tasks | #1 open model |
| RoboArena | Real-robot policy on DROID hardware | #1 open model |
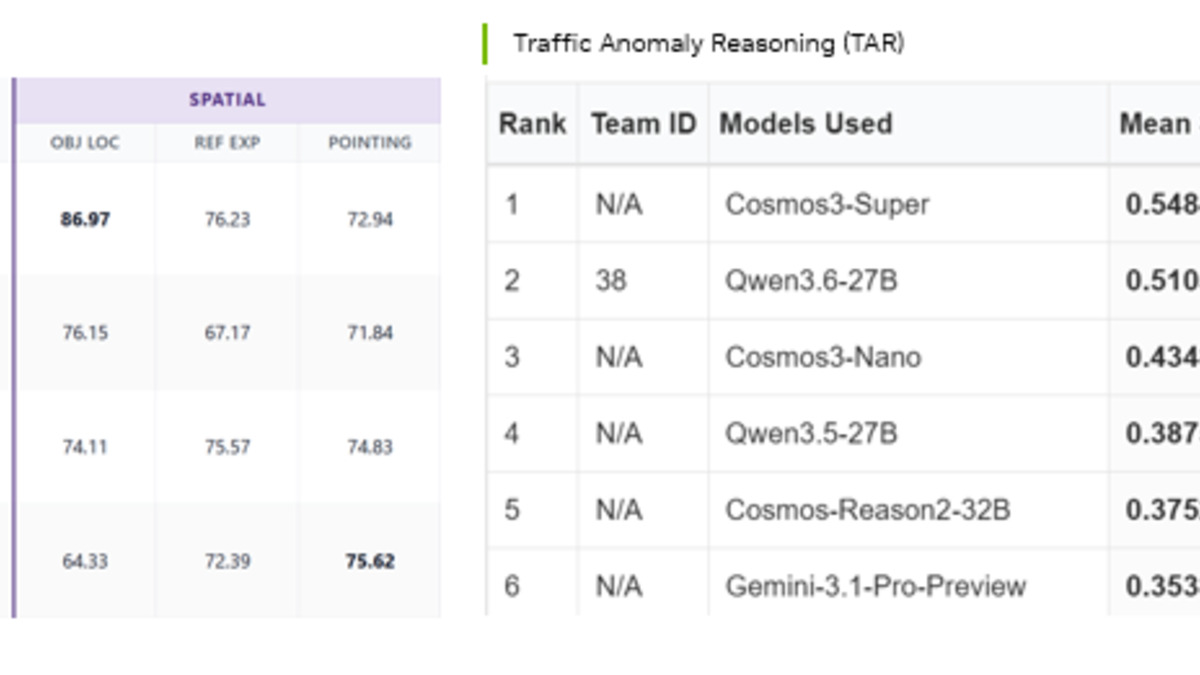
| TAR | Traffic oddity reasoning | #1 open model |
| Artificial Analysis T2I | Text-to-image open weights ranking | #1 open model |
| Artificial Analysis I2V | Image-to-video open weights ranking | #1 open model |
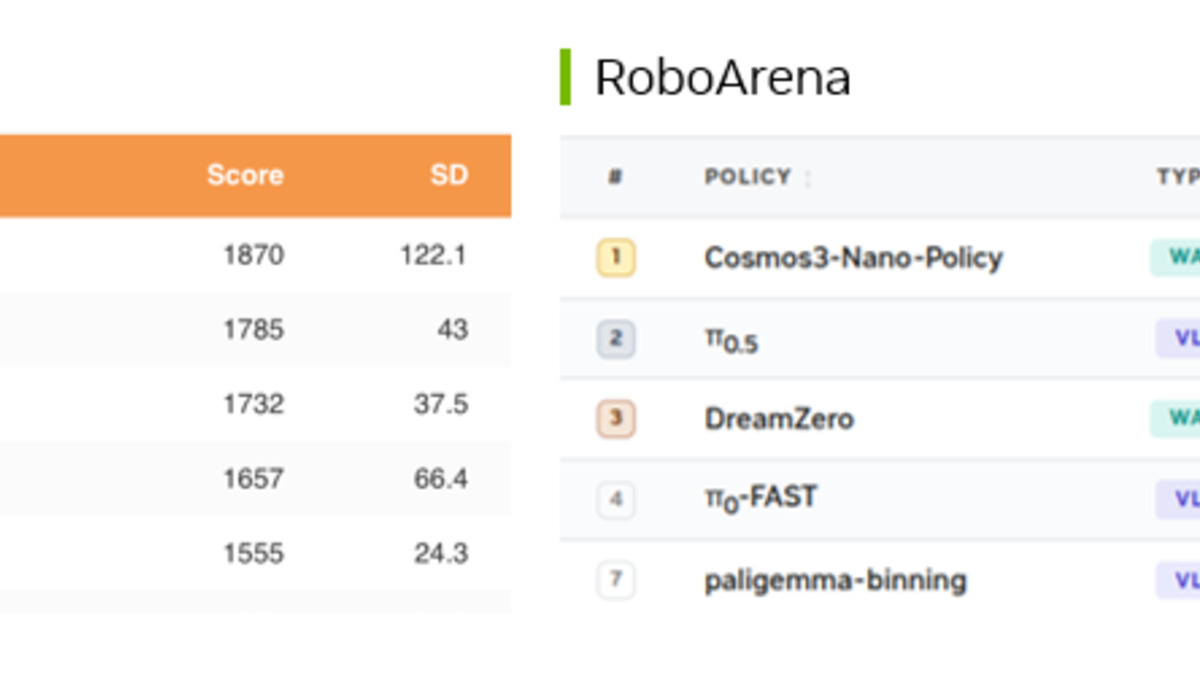 Cosmos 3 Nano post-trained policy tops RoboLab and RoboArena at launch.
Source: blogs.nvidia.com
Cosmos 3 Nano post-trained policy tops RoboLab and RoboArena at launch.
Source: blogs.nvidia.com
The caveat worth flagging: all of these benchmarks are either run or heavily cited by NVIDIA in its own announcement. Independent third-party replication will take weeks. The Artificial Analysis rankings are external, which gives them slightly more credibility, but the robotics-specific leaderboards (RoboLab, RoboArena) are fairly new and not as established as something like MMLU or SWE-Bench. Still, the benchmark sweep is wide enough that performance appears genuine rather than cherry-picked.
Specific numerical scores aren't disclosed in the public announcement - NVIDIA points to the technical report PDF for full tables. The NVFP4 quantization path reportedly delivers up to 2x inference speedup over BF16 baseline.
Key Capabilities
The architecture choice matters here. Previous physical AI models were either good at reasoning (VLMs) or good at generation (video diffusion models), but not both in the same weights. Cosmos 3 routes all modalities through a shared MoT backbone where each transformer decoder layer maintains two parameter sets - one for the autoregressive Reasoner, one for the diffusion Generator. They share attention across subsequences but use separate weights, which lets the model condition video generation on its own reasoning output without a brittle two-model handoff.
This enables capabilities that were awkward or impossible to chain before. Feed in a scene image and a text command, and the model generates both a video of what should happen and a robot action path (joint angles, gripper positions) to make it happen. That's the inverse dynamics path, which is directly useful for policy learning. The forward dynamics path goes the other way: given an action sequence and starting frame, the model predicts the resulting video - synthetic training data generation without a physics simulator.
The action support is specific: Cosmos 3 ships with built-in embodiment specs for Franka Panda arms, WidowX 250, UMI, Agibot, UR series, and autonomous vehicle/egocentric motion modes. The action vectors range from 9D to 57D depending on embodiment. This isn't a vague "supports robotics" claim - it's a concrete set of robot interfaces baked into the model. Developers working outside those embodiments will need custom post-training.
See the robotics and embodied AI leaderboard for context on how Cosmos 3 fits into the broader landscape of VLA models competing for robotics use cases.
Pricing and Availability
Cosmos 3 Nano and Super are available now on Hugging Face, GitHub, and build.nvidia.com. API access runs through NVIDIA NIM microservices on Microsoft Azure, CoreWeave, Baseten, Nebius, Deep Infra, and Classmethod. Pricing for NIM API calls isn't disclosed.
Self-hosting Nano requires a NVIDIA RTX PRO 6000 workstation (or equivalent Ampere/Hopper/Blackwell GPU). Super needs datacenter-grade Hopper or Blackwell hardware. The model runs in BF16 by default, with NVFP4 quantization available for the 2x speedup at the cost of some quality. vLLM deployment is supported through vLLM-Omni (v0.19.1 for CUDA 12.8, v0.21.0 for CUDA 13).
Cosmos 3 Edge, the real-time inference variant for edge hardware, is listed as "coming soon" with no release window given.
Compared to proprietary alternatives, the open weight release is a significant differentiator. Physical AI developers who need to fine-tune on proprietary robot data can do so locally under OpenMDW 1.1, which permits commercial use. That's not possible with closed API-only systems.
 Cosmos 3 reasoning across diverse physical scenes - from robotics labs to traffic scenarios.
Source: blogs.nvidia.com
Cosmos 3 reasoning across diverse physical scenes - from robotics labs to traffic scenarios.
Source: blogs.nvidia.com
Strengths and Weaknesses
Strengths
- Open weights under OpenMDW 1.1 with commercial use allowed - fine-tune on your own robot data without sending it to NVIDIA's API
- Only open model that unifies reasoning, world generation, and action prediction in one architecture at this scale
- 256K context window in the Reasoner tower handles long video sequences without chunking
- Concrete embodiment support for major robot platforms built in at release, not as an afterthought
- Six synthetic training datasets released alongside the weights - useful for researchers extending the model
- Nano variant (16B) runs on a single RTX PRO 6000, making it usable outside HPC clusters
Weaknesses
- Benchmark sweep is completely self-reported at launch; independent evaluations haven't run yet
- No specific numerical scores published in the announcement - leaderboard claims without tables is a yellow flag
- Cosmos 3 Edge (real-time inference) not yet available, limiting deployment on actual edge hardware
- Super (64B) needs Hopper/Blackwell datacenter GPUs - not accessible to most individual developers
- Known failure modes: temporal inconsistency in long sequences, audio-video sync drift, and object morphing in complex scenes
- Action support is limited to specific documented embodiments - custom robot platforms need post-training
Related Coverage
- NVIDIA Nemotron 3 Super 120B-A12B - NVIDIA's parallel MoE language model release, also from the Nemotron 3 family
- NVIDIA SANA-WM World Model - NVIDIA's earlier single-GPU world model for reference
- NVIDIA's Alpamayo Hits 100K Downloads - context on NVIDIA's robotics model momentum before Cosmos 3
- Robotics Embodied AI Leaderboard 2026 - broader VLA model rankings where Cosmos 3 will appear
- Video Generation Benchmarks Leaderboard 2026 - where Cosmos 3 sits in the text-to-video competitive field
FAQ
What hardware do I need to run Cosmos 3 Nano locally?
NVIDIA recommends a RTX PRO 6000 workstation GPU. Ampere, Hopper, and Blackwell architectures are all supported, with Hopper (H100) listed as a tested configuration.
Is Cosmos 3 free to use commercially?
Yes. The OpenMDW 1.1 license from the Linux Foundation permits both personal and commercial use. Check the specific license terms before rolling out in production, especially for safety-critical applications.
What's the difference between the Reasoner and Generator context windows?
The Reasoner (VLM) accepts up to 256K tokens - useful for long video sequences. The Generator's text input is capped at 4,096 tokens. For most generation tasks the 4K limit is fine; the 256K window matters for reasoning over extended temporal sequences.
Can Cosmos 3 control any robot, or only specific platforms?
Out of the box: Franka Panda (single and dual arm), WidowX 250, UMI, Agibot, UR series, Google robot, and autonomous vehicle/egocentric camera modes. For other embodiments, custom post-training is required.
Where does Cosmos 3 fit relative to Cosmos 2 / Cosmos-Predict?
Cosmos 3 is a generational upgrade from Cosmos-Predict2 and Cosmos-Predict2.5, adding native action generation and the MoT omnimodel architecture. Prior Cosmos models were mostly video generation models; Cosmos 3 is closer to a unified physical AI operating system.
Sources:
✓ Last verified June 1, 2026
