Muse Spark
Meta's first closed-source frontier model scores 52 on the Artificial Analysis Intelligence Index, leads on HealthBench Hard, and ships free at meta.ai - but has no public API yet.

Overview
Meta shipped Muse Spark on April 8, 2026 - the first model from its Meta Superintelligence Labs (MSL) division and the first in what the company is calling the Muse series. The release marks a sharp break from Meta's Llama lineage: where Llama was open-weight and community-focused, Muse Spark is proprietary, closed-source, and rolled out directly into Meta's consumer apps.
TL;DR
- 4th on the Artificial Analysis Intelligence Index (score: 52), behind Gemini 3.1 Pro, GPT-5.4, and Claude Opus 4.6
- Leads all tested models on HealthBench Hard (42.8) and Humanity's Last Exam in Contemplating mode (50.2%)
- Built in nine months by Meta Superintelligence Labs under Chief AI Officer Alexandr Wang
- Free at meta.ai with 262K context; no public API yet
The model was built over nine months by a team led by Alexandr Wang, who joined Meta in June 2025 as its first Chief AI Officer after Meta picked up a 49% stake in his company Scale AI for roughly $14 billion. Muse Spark is described as "the first step on our scaling ladder" - small and fast by design, intended to verify the new MSL architecture before the team scales further.
The competitive position is honest, if not spectacular. Muse Spark scores 52 on the Artificial Analysis Intelligence Index, placing 4th overall behind Gemini 3.1 Pro (57), GPT-5.4 (57), and Claude Opus 4.6 (53). It wins on health and scientific reasoning, loses on abstract reasoning and coding. That's a more specific story than Meta's marketing implies, and it's worth examining the numbers in detail.
Key Specifications
| Specification | Details |
|---|---|
| Provider | Meta |
| Model Family | Muse |
| Parameters | Not disclosed |
| Context Window | 262,000 tokens |
| Input Price | Free (no public API) |
| Output Price | Free (no public API) |
| Release Date | April 8, 2026 |
| License | Proprietary |
| Open Source | No |
| Input Modalities | Text, image, voice |
| Output Modalities | Text only |
Benchmark Performance
The benchmarks split into two stories depending on which mode you're evaluating. Thinking mode is Muse Spark's standard reasoning layer. Contemplating mode - which coordinates multiple specialized agents in parallel before returning a synthesized answer - is the more expensive inference path and the one that competes with Gemini 3.1 Pro Deep Think and GPT-5.4 Pro.
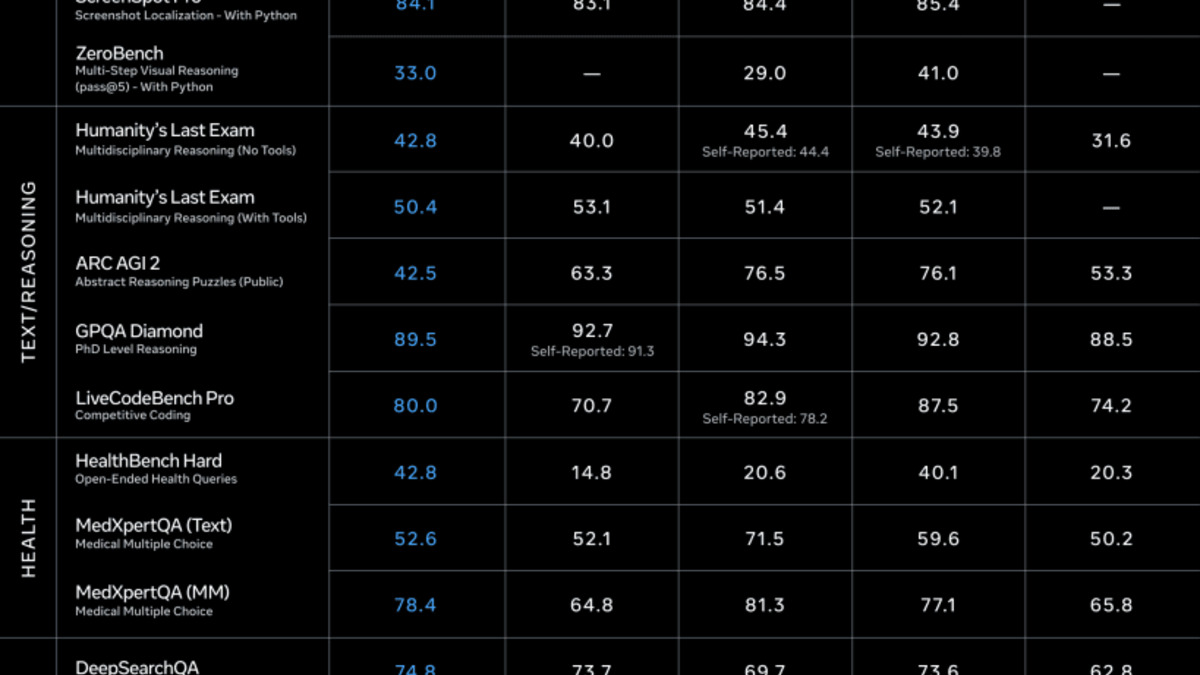 Meta's official benchmark comparison for Muse Spark in Thinking mode across health, vision, and reasoning tasks.
Source: officechai.com
Meta's official benchmark comparison for Muse Spark in Thinking mode across health, vision, and reasoning tasks.
Source: officechai.com
Thinking Mode
| Benchmark | Muse Spark | GPT-5.4 | Gemini 3.1 Pro | Claude Opus 4.6 |
|---|---|---|---|---|
| AA Intelligence Index | 52 | 57 | 57 | 53 |
| GPQA Diamond | 89.5% | 92.8% | 94.3% | 92.7% |
| HealthBench Hard | 42.8 | 40.1 | 20.6 | 14.8 |
| CharXiv Reasoning | 86.4 | 82.8 | 80.2 | - |
| MMMU-Pro (Vision) | 80.5% | - | 82.4% | - |
| ARC-AGI-2 | 42.5 | 76.1 | 76.5 | - |
| Terminal-Bench 2.0 | 59.0 | 75.1 | 68.5 | - |
| DeepSearchQA | 74.8 | - | 69.7 | - |
Contemplating Mode
| Benchmark | Muse Spark | GPT-5.4 Pro | Gemini Deep Think |
|---|---|---|---|
| Humanity's Last Exam | 50.2% | 43.9% | 48.4% |
| FrontierScience Research | 38.3% | 36.7% | 23.3% |
| IPhO 2025 Theory | 82.6% | 93.5% | 87.7% |
The health numbers are genuine. HealthBench Hard at 42.8 is more than double Gemini 3.1 Pro's 20.6 - not a marginal win but a structural difference, attributable to Meta's collaboration with over 1,000 physicians during training. The Humanity's Last Exam result in Contemplating mode is also independently interesting: 50.2% beats every tested competitor, including models purpose-built for extended reasoning.
The weaknesses are equally clear and appear in categories that matter to developers. ARC-AGI-2 at 42.5 is roughly half the score of GPT-5.4 and Gemini 3.1 Pro. Terminal-Bench 2.0 at 59.0 trails both competitors by wide margins. These gaps are acknowledged by Meta - the company says in its release materials that there is "a gap between Muse Spark and the models already available" on coding tasks. That's a significant admission when many enterprise use cases are code-heavy. For full coding comparisons see the coding benchmarks leaderboard.
One flag worth noting: most benchmark scores above come from Meta's own published evaluations. The Artificial Analysis Intelligence Index score (52) is independently measured. For categories where only Meta's numbers exist - especially health - treat them as directional rather than final.
Key Capabilities
Muse Spark is natively multimodal, accepting text, image, and voice inputs, though output is text-only at launch. The image and voice channels work in practice: Simon Willison documented the model accurately counting discrete objects (12 whiskers on a cat, 25 pelicans) with coordinate precision, which suggests the visual grounding implementation is solid rather than decorative.
The tool suite built into meta.ai is worth examining. Willison identified 16 tools exposed through the interface including container.python_execution (Python 3.9.25 with pandas, numpy, matplotlib, scikit-learn), browser.search, container.visual_grounding, media.image_gen, and subagents.spawn_agent. The last one is architecturally interesting: users can trigger Contemplating mode, which spins up multiple reasoning agents in parallel before producing a single answer. That's similar in spirit to how Grok 4.20 approaches complex queries via its parallel agent system, though Meta's implementation is distinct.
Meta trained Muse Spark with input from over 1,000 physicians. The HealthBench Hard score of 42.8 - triple the Gemini 3.1 Pro result - suggests the investment translated into model behavior.
The health capability is the most differentiated feature in the launch. Meta collaborated with physicians across the training process, and the model can parse medical images, produce interactive health displays explaining nutrition and physiology, and answer clinical questions at a level no other frontier model currently matches on HealthBench Hard. Whether that translates to real-world clinical accuracy is a separate question the benchmarks don't answer.
Meta also cites significant compute efficiency: Muse Spark reportedly reaches capabilities comparable to Llama 4 Maverick using more than 10x less compute. If that holds at scale, it has consequences for how Meta prices the API when it eventually opens.
Pricing and Availability
Muse Spark is free to use at meta.ai and via the Meta AI app. No API pricing has been announced. A private API preview is available to select partners, but no public release date has been set.
The model is rolling out to WhatsApp, Instagram, Facebook, Messenger, and Meta's Ray-Ban AI glasses over the coming weeks, replacing the Llama-based models that powered Meta AI previously.
Meta plans to open-source future versions of the Muse series, maintaining a two-track strategy: Muse for closed, competitive frontier products and Llama for open community releases. The timing on any open-source release is unspecified.
For developers, the lack of a public API is the limiting factor right now. There is no pricing to assess, no rate limits to benchmark, and no programmatic access for integration work. That may change quickly given Meta's stated commercial ambitions, but until it does, Muse Spark is a consumer product, not a developer platform.
Strengths and Weaknesses
Strengths
- Leads all benchmarked models on HealthBench Hard (42.8) and HealthBench general tasks
- Highest Humanity's Last Exam score in Contemplating mode (50.2%) among tested models
- Strong vision capability - MMMU-Pro at 80.5%, second only to Gemini 3.1 Pro Preview
- Competitive CharXiv Reasoning score (86.4), best among tested models
- Free access with no usage limits via meta.ai
- Compute-efficient: comparable Llama 4 Maverick capability at over 10x lower compute cost
Weaknesses
- No public API and no announced pricing timeline
- Weak abstract reasoning: ARC-AGI-2 at 42.5 vs. 76.5 for Gemini 3.1 Pro
- Below-par coding performance: Terminal-Bench 2.0 at 59.0 vs. 75.1 for GPT-5.4
- Proprietary - no open weights, no fine-tuning, no self-hosting
- Meta-reported benchmarks outside health domains need independent verification
- Text-only output; no image or audio generation through the main interface
Related Coverage
- Meta Muse Spark Launches, Ranks 4th Among Frontier Models - our launch coverage
- Meta Closes Open Source Door on Frontier AI - background on the strategic shift from Llama to Muse
- Llama 4 Maverick - the previous-generation Meta flagship this model supersedes in consumer apps
- Reasoning Benchmarks Leaderboard - where Muse Spark fits on GPQA and HLE
- Multimodal Benchmarks Leaderboard - full vision benchmark comparisons
- Coding Benchmarks Leaderboard - context for Terminal-Bench results
Sources:
- Introducing Muse Spark - Meta AI Blog
- Introducing Muse Spark - Meta Newsroom
- Scaling How We Build and Test Our Most Advanced AI - Meta AI
- Muse Spark - Artificial Analysis
- Meta debuts Muse Spark, first AI model under Alexandr Wang - Axios
- Meta debuts new AI model - CNBC
- Meta's new model is Muse Spark - Simon Willison
- Meta Releases Muse Spark, Beats Top Frontier Labs On Some Benchmarks - OfficeChai
- Meta debuts the Muse Spark model - TechCrunch
- Goodbye, Llama? Meta launches Muse Spark - VentureBeat
- Meta Muse Spark - TokenCost
✓ Last verified April 9, 2026

