Mistral Medium 3.5
Mistral's first flagship merged model: a dense 128B with configurable reasoning, vision, and 77.6% SWE-Bench Verified, self-hostable on 4 GPUs.

Mistral Medium 3.5 is Mistral AI's first "merged" flagship model - one set of weights that handles instruction-following, reasoning, and coding without switching between separate specialized models. Previous Mistral deployments required routing between Magistral for reasoning and Devstral for coding. Medium 3.5 replaces both, plus the older Medium 3.1, with a single 128B dense model.
TL;DR
- Dense 128B, 256K context, open weights under modified MIT, self-hostable on 4 GPUs at FP8
- 77.6% SWE-Bench Verified - clears Devstral 2 (72.2%) and Devstral Small 2 (68.0%) by a clean margin
- $1.50/M input tokens, 40% cheaper than GPT-4o, OpenAI-compatible API
Key Specifications
| Specification | Details |
|---|---|
| Provider | Mistral AI |
| Model Family | Mistral Medium |
| Parameters | 128B (dense) |
| Architecture | Dense transformer (not MoE) |
| Context Window | 256,000 tokens |
| Tensor Formats | BF16, F8_E4M3 (FP8) |
| Multimodal | Text + image input |
| Configurable Reasoning | reasoning_effort parameter (none/high) |
| Multilingual | 24+ languages |
| Release Date | April 29, 2026 |
| License | Modified MIT (open weights) |
| Open Weights | Yes (Hugging Face) |
The "modified MIT" label needs a note: the license is permissive for most organizations but includes revenue-based restrictions for large companies. If your company clears a certain revenue threshold, check the license text before launching commercially. For startups and mid-size businesses the restrictions are effectively moot.
Benchmark Performance
Mistral published benchmark results across three categories: SWE-Bench coding, τ³ agentic task suites, and math/reasoning. MMLU and GPQA Diamond aren't disclosed.
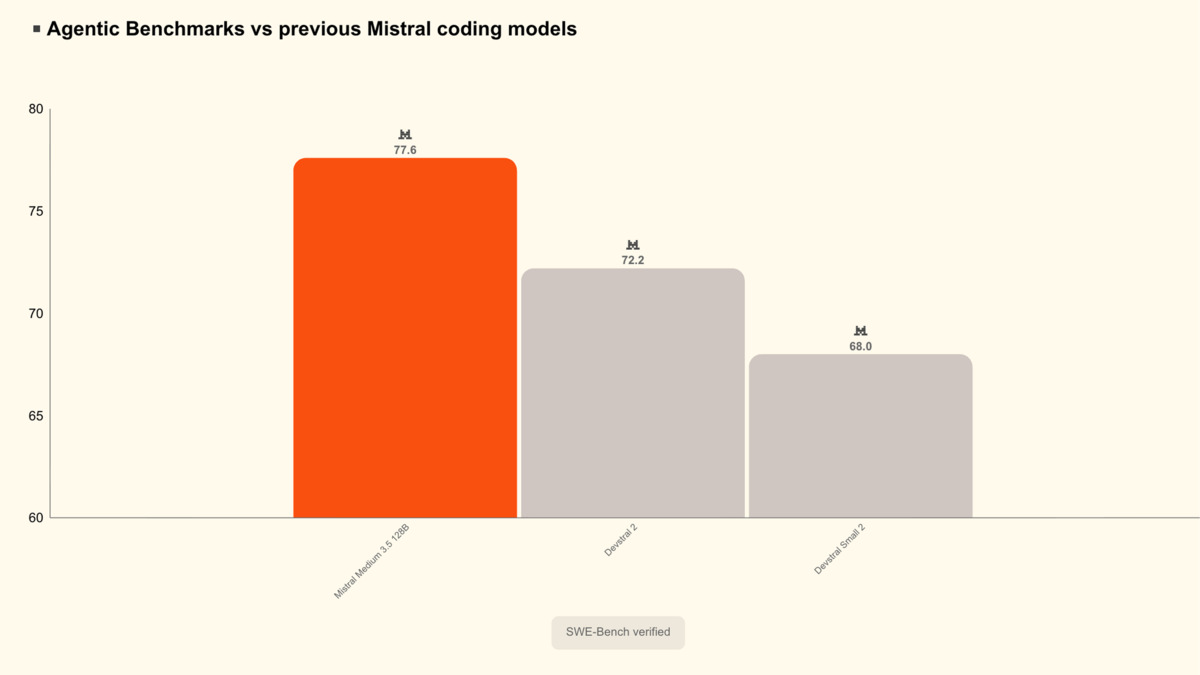 SWE-Bench Verified scores: Medium 3.5 at 77.6% vs Devstral 2 at 72.2% vs Devstral Small 2 at 68.0%.
Source: huggingface.co
SWE-Bench Verified scores: Medium 3.5 at 77.6% vs Devstral 2 at 72.2% vs Devstral Small 2 at 68.0%.
Source: huggingface.co
Coding
| Model | SWE-Bench Verified |
|---|---|
| Mistral Medium 3.5 | 77.6% |
| Devstral 2 | 72.2% |
| Devstral Small 2 | 68.0% |
The 5.4-point gap over Devstral 2 is significant in SWE-Bench terms - it translates to noticeably fewer failed patches in a real agentic loop. Medium 3.5 also beats Qwen 3.5 397B A17B on this benchmark per Mistral's own reporting, though the 397B MoE is a much larger model by total parameter count.
Agentic Tasks (τ³ Suite)
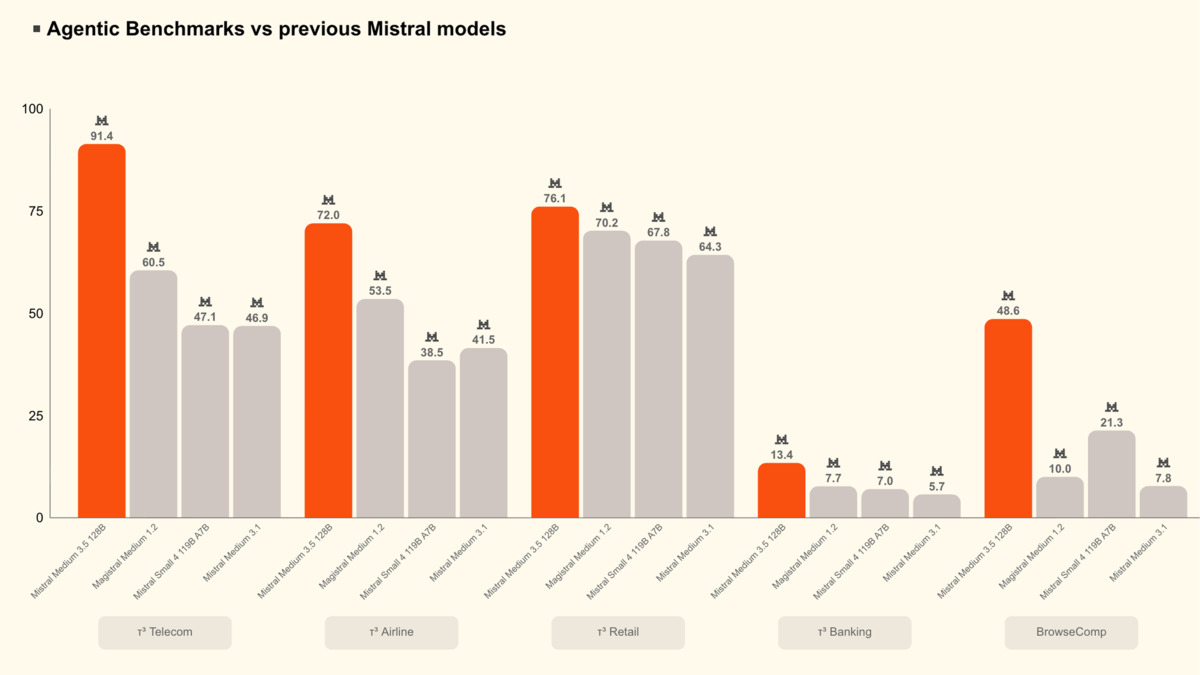 τ³ agentic benchmark scores across five task domains: Medium 3.5 leads every category versus Magistral Medium 1.2, Mistral Small 4, and Medium 3.1.
Source: huggingface.co
τ³ agentic benchmark scores across five task domains: Medium 3.5 leads every category versus Magistral Medium 1.2, Mistral Small 4, and Medium 3.1.
Source: huggingface.co
| Benchmark | Mistral Medium 3.5 | Magistral Medium 1.2 | Mistral Small 4 | Medium 3.1 |
|---|---|---|---|---|
| τ³-Telecom | 91.4 | 60.5 | 47.1 | 46.9 |
| τ³-Airline | 72.0 | 53.5 | 38.5 | 41.5 |
| τ³-Retail | 76.1 | 70.2 | 67.8 | 64.3 |
| τ³-Banking | 13.4 | 7.7 | 7.0 | 5.7 |
| BrowseComp | 48.6 | 10.0 | 21.3 | 7.8 |
The τ³ numbers are striking. Telecom jumps 31 points over Magistral Medium 1.2 - the previous dedicated reasoning model. BrowseComp, which tests open-ended web research tasks, goes from 10.0 to 48.6. These aren't incremental gains.
Math and Instruction Following
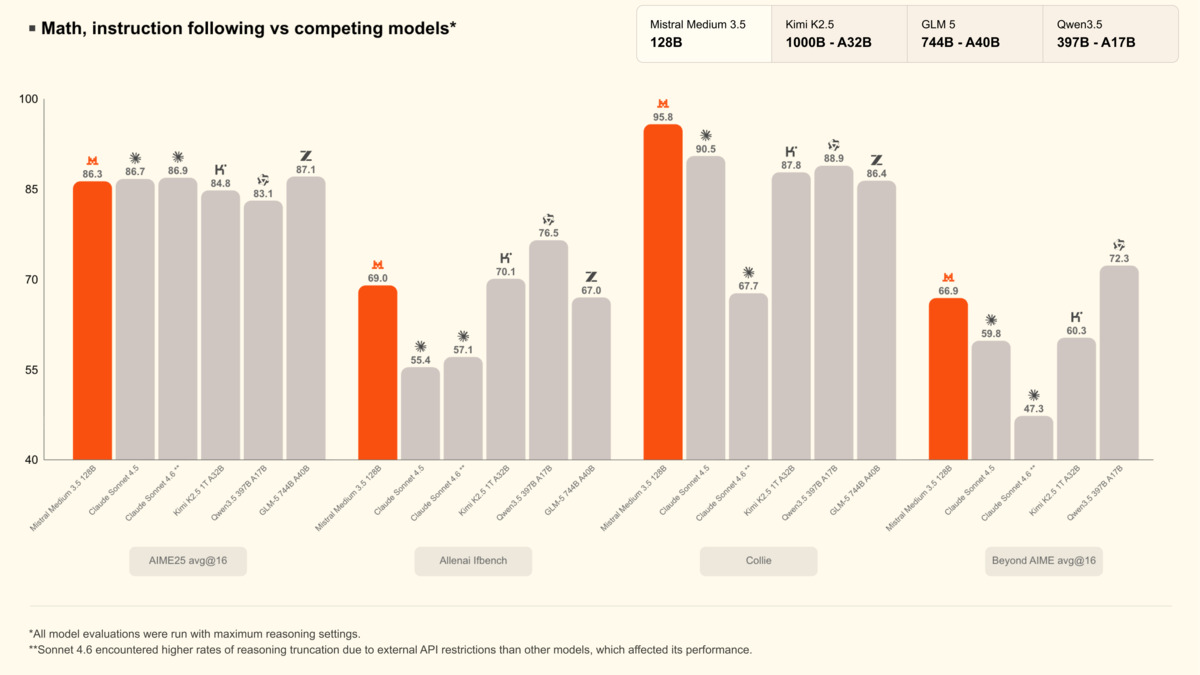 Math benchmarks (AIME25, AllenAI IfBench, Collie, Beyond AIME) vs Kimi K2.5, GLM-5, and Qwen3.5 397B - all run at maximum reasoning settings.
Source: huggingface.co
Math benchmarks (AIME25, AllenAI IfBench, Collie, Beyond AIME) vs Kimi K2.5, GLM-5, and Qwen3.5 397B - all run at maximum reasoning settings.
Source: huggingface.co
On AIME25 avg@16, Medium 3.5 scores 86.3, roughly matching Claude Sonnet 4.5 (86.7) and Sonnet 4.x (88.9). Kimi K2.5 at 84.8 and GLM-5 at 83.1 trail by a few points. On the Collie instruction-following benchmark, Medium 3.5 peaks at 95.8, ahead of competing models in that group. All math scores were measured at maximum reasoning settings.
Important caveat: Mistral ran these benchmarks themselves. Independent third-party replications aren't available at launch. The SWE-Bench score is more trustworthy since it uses standardized tooling, but the τ³ suite is Mistral-designed and Mistral-run.
Key Capabilities
Merged Architecture
The key architectural decision is merging instruction-following, reasoning, and coding into a single checkpoint. Earlier Mistral deployments split these across Magistral (reasoning), Devstral (coding), and Medium 3.1 (general). Now you deploy one model and control behavior via the reasoning_effort parameter:
# Fast, direct responses
reasoning_effort = "none"
# Step-by-step chain-of-thought for complex tasks
reasoning_effort = "high"
This matters operationally. One model to monitor, one model to version, one bill.
Vision
Medium 3.5 includes a vision encoder trained from scratch. It accepts images at variable sizes and aspect ratios - no forced resizing to a fixed resolution. That's relevant for document parsing, where tall screenshots and wide tables lose information when forced into a square. The model supports OCR with structured annotations and bounding box extraction through the API.
Agentic Tooling
Native function calling, parallel tool use, structured JSON output, and async cloud-based agent execution are all part of the base package. The model powers Mistral's own Vibe 2.0 remote agents - sessions that run in the cloud, can be spawned from the CLI or Le Chat, and let you inspect file diffs, tool calls, and progress states mid-run. This is the same model powering Le Chat's new Work Mode, which runs multi-step tasks by calling multiple tools in parallel.
Self-Hosting
At FP8 precision, the 128B weights need roughly 128GB VRAM. Four H100 80GB cards (320GB total) is the practical minimum with room for the KV cache during production inference. Mistral also ships an EAGLE speculative decoding model for local inference acceleration. Supported runtimes include vLLM, SGLang, Transformers, and Ollama.
vllm serve mistralai/Mistral-Medium-3.5-128B \
--tensor-parallel-size 8 \
--tool-call-parser mistral \
--enable-auto-tool-choice \
--reasoning-parser mistral \
--max_num_batched_tokens 16384 \
--gpu_memory_utilization 0.8
BF16 serving requires 8 GPUs to leave enough headroom. FP8 is the recommended path for most production setups on H100.
Pricing and Availability
| Access | Pricing |
|---|---|
| Mistral API | $1.50/M input, $7.50/M output |
| Open weights (Hugging Face) | Free |
| NVIDIA build.nvidia.com | Free (prototyping) |
| NVIDIA NIM | Production container |
| Le Chat Pro/Team/Enterprise | Included |
At $1.50/M input, Medium 3.5 is cheaper than GPT-4o ($2.50/M input) and Gemini 3.1 Pro ($2.00/M input). The output rate at $7.50/M is higher than some competitors, so workloads with long outputs should factor that in. The API is OpenAI-compatible - swap the base URL, keep your existing client code.
For cost-efficiency comparisons at scale, see our cost efficiency leaderboard.
Strengths
- Single merged model replaces three separate Mistral deployments
- 77.6% SWE-Bench Verified - best in the Mistral family by a large margin
- Large agentic performance gains over Magistral and Medium 3.1
- Open weights under modified MIT, self-hostable on 4 GPUs (FP8)
- Vision encoder handles variable image sizes and aspect ratios
- OpenAI-compatible API, no client migration needed
- $1.50/M input is competitive for a 128B model
Weaknesses
- No published MMLU, GPQA Diamond, or broad general-knowledge benchmarks
- τ³ benchmarks are Mistral-designed and Mistral-run - no independent replication at launch
- "Modified MIT" has revenue-based restrictions that some large enterprise users need to read carefully
- BF16 self-hosting needs 8x 80GB GPUs; FP8 minimum is 4x H100s - not accessible for most on-prem setups
- Dense 128B is a larger footprint than MoE alternatives like Qwen 3.5 397B A17B (17B active per token)
Related Coverage
- Review: Mistral Vibe 2.0 - Medium 3.5 powers the remote agent runner in Vibe 2.0
- Mistral Small 4 - Smaller MoE sibling, 119B total / 6B active, Apache 2.0
- Coding Benchmarks Leaderboard - Full SWE-Bench rankings across models
- Agentic AI Benchmarks Leaderboard - Where Medium 3.5 sits against broader competition
Sources:
Last updated
✓ Last verified April 30, 2026
