MiniMax M3
MiniMax M3 is an open-weight frontier model with a 1M-token context window, native multimodal input, and strong agentic coding at $0.60/M input tokens.

Overview
MiniMax M3 is the June 2026 flagship from Shanghai-based MiniMax, positioned as the first open-weight model to combine three things at once: frontier-tier coding performance, a genuine one-million-token context window, and native multimodal input. Released June 1, 2026, M3 is accessible through the MiniMax API and subscription plans; open weights and a technical report are promised on Hugging Face within roughly ten days of launch.
TL;DR
- Scores 59.0% on SWE-Bench Pro, beating GPT-5.5 (58.6%) and Gemini 3.1 Pro (54.2%) on autonomous coding evals
- 1M-token context at $0.60/M input ($0.30/M during launch promo) - roughly 5-10% of Claude Opus pricing
- Benchmarks are self-reported; weights not yet shipped at publication, so independent verification is pending
The headline technical story is MiniMax Sparse Attention (MSA), a new attention architecture that selects which key-value cache blocks are actually relevant before running the expensive attention computation. That design cuts per-token compute to one-twentieth of the previous M2 generation at 1M context, delivering roughly 9x faster prefill and 15x faster decoding at maximum context length.
MiniMax trained M3 on over 100 trillion tokens with multimodal data interleaved from the start, not tacked on at fine-tuning. The model accepts text, image, and video inputs and produces text output. Parameter count is not disclosed.
Key Specifications
| Specification | Details |
|---|---|
| Provider | MiniMax |
| Model Family | MiniMax M-series |
| Parameters | Not disclosed |
| Context Window | 1M tokens (512K guaranteed minimum) |
| Input Price | $0.60/M tokens (50% promo: $0.30/M) |
| Output Price | $2.40/M tokens (50% promo: $1.20/M) |
| Release Date | 2026-06-01 |
| License | Open-weight (terms unconfirmed pending weight release) |
| Modalities | Text, image, video input; text output |
Benchmark Performance
The numbers below come from MiniMax's own launch materials, run on MiniMax infrastructure with agent scaffolding MiniMax configured. That caveat matters: every comparison figure was selected by the vendor, not a neutral third party.
| Benchmark | MiniMax M3 | Claude Opus 4.8 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-Bench Pro | 59.0% | 69.2% | 58.6% | 54.2% |
| Terminal-Bench 2.1 | 66.0% | 74.6% | - | - |
| OSWorld-Verified | 70.06% | 83.4% | - | - |
| BrowseComp | 83.5 | - | - | - |
| GPQA Diamond | 92.68% | - | - | 94.3% |
| PostTrainBench | 37.1 (#3) | 42.4 (#1) | 39.3 (#2) | - |
 PostTrainBench breakdown showing M3 at rank #3, behind Opus 4.7 and GPT-5.5 across composite task categories.
Source: minimax.io
PostTrainBench breakdown showing M3 at rank #3, behind Opus 4.7 and GPT-5.5 across composite task categories.
Source: minimax.io
On coding evals, M3 beats GPT-5.5 and Gemini 3.1 Pro on SWE-Bench Pro while staying behind Claude Opus 4.8's 69.2%. BrowseComp is the standout result: 83.5 against Opus 4.7's 79.3. GPQA Diamond at 92.68% puts it in frontier territory for expert-level scientific reasoning, behind Gemini 3.1 Pro's 94.3%.
The ICLR paper replication demonstration - 18 commits, 23 experimental figures over a 12-hour autonomous run - and a CUDA kernel optimization reaching 9.4x speedup over 147 iterations are meant to show long-context agentic capability, not just benchmark scores. Whether those translate in real-world workflows at scale is still an open question until independent evaluations land.
Key Capabilities
Agentic Coding
M3 is MiniMax's clearest bet on the agentic coding market. The model scored 59% on SWE-Bench Pro and 66% on Terminal-Bench 2.1, both benchmarks that test autonomous task completion in real software environments. It also scores 74.2% on MCP Atlas, suggesting reasonable performance in multi-tool agent setups.
The context advantage matters for long-horizon coding tasks. Most competing API models cap at 200K tokens; M3's guaranteed 512K minimum, with bursts to 1M, lets an agent load an entire large codebase plus history without chunking. SubQ pushes further with 12M tokens via a subquadratic architecture, but it's at an earlier commercial stage.
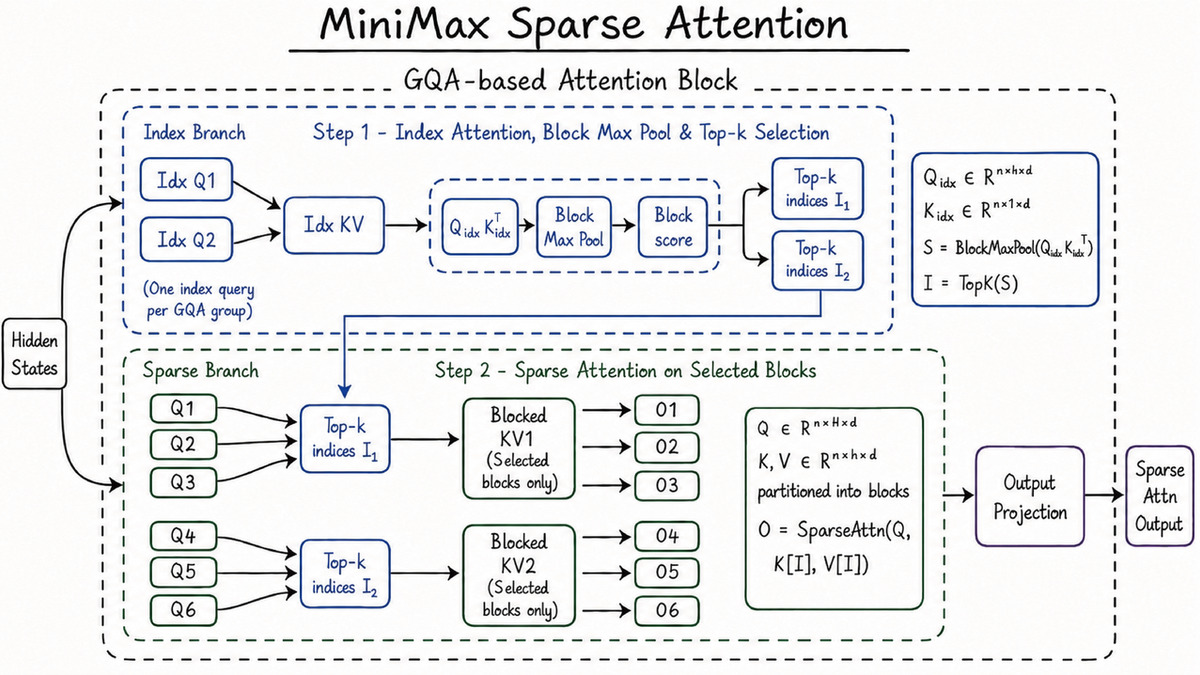 MiniMax Sparse Attention (MSA) uses a lightweight index branch to select relevant KV blocks before running full attention, reducing per-token compute to 1/20th of the M2 generation at 1M tokens.
Source: minimax.io
MiniMax Sparse Attention (MSA) uses a lightweight index branch to select relevant KV blocks before running full attention, reducing per-token compute to 1/20th of the M2 generation at 1M tokens.
Source: minimax.io
Long-Context Efficiency
The MSA architecture is the differentiator here. Standard attention scales quadratically with sequence length; MSA's block-selection approach cuts that down to near-linear cost at very long contexts. MiniMax reports roughly 100 tokens per second output speed at 1M context - about 3x faster than Claude Opus models at that length. For long-context benchmarks, that matters beyond raw accuracy.
Multimodal Input
M3 handles text, image, and video inputs natively, trained with interleaved multimodal data from pretraining rather than added post-hoc. The model scores above Gemini 3.1 Pro on OmniDocBench and beats Claude Opus 4.7 on SVG-Bench according to MiniMax's own evaluations. Image and video input support is available via the API at launch; output is text-only.
Pricing and Availability
The standard API rate is $0.60/M input tokens and $2.40/M output tokens. A 50% launch discount brought that to $0.30/M input and $1.20/M output; MiniMax indicated the promotion ran for the first week. At promotional pricing, a 500K-input plus 100K-output task costs roughly $0.27 - compared to around $5 on Claude Opus at similar context lengths. Even at standard rates, M3 undercuts frontier proprietary models significantly.
Subscription plans on MiniMax Code:
- Plus: $20/month (~1.7B tokens)
- Max: $50/month (~5.1B tokens)
- Ultra: $120/month (~9.8B tokens)
M3 is also available on OpenRouter at the same pricing. Longer-context inputs (beyond 512K tokens) carry a surcharge over the base rate. Compare pricing directly against MiniMax M2.7 if your workloads stay under 200K - M2.7 is available at the same base rate with verified open weights.
Open weights are expected on Hugging Face under the MiniMaxAI organization within ten days of the June 1 launch. MiniMax's M2.7 shipped with a license restricting commercial use without written authorization; M3's final license terms will land with the weights. Don't assume commercial use is freely permitted based on the "open-weight" label until you've read the actual license.
Strengths
- Competitive SWE-Bench Pro score (59%) at 5-10% of frontier proprietary pricing
- 1M-token context with genuine efficiency gains from MSA architecture
- Native multimodal input from pretraining, not a fine-tuned add-on
- Roughly 3x faster long-context generation vs. standard attention models
- BrowseComp score of 83.5 beats Claude Opus 4.7 on autonomous web tasks
Weaknesses
- All launch benchmarks are self-reported; independent verification pending
- Parameter count not disclosed, making model comparison difficult
- Open weights not yet published at launch; license terms unconfirmed
- OSWorld GUI score (70%) lags Claude Opus 4.8 (83.4%) on desktop operation
- Chinese jurisdiction: API traffic falls under China's National Intelligence Law
- Context pricing surcharge kicks in above 512K tokens
Related Coverage
- MiniMax M2.7 model profile - the predecessor, with verified 59% SWE-Bench and confirmed open weights
- MiniMax M2.7 Self-Evolving Agent Coverage - background on MiniMax's autonomous training approach
- SWE-Bench Coding Agent Leaderboard - M3's position in the broader coding-agent rankings
- Long-Context Benchmarks Leaderboard - 1M-context comparison across current models
- Agentic AI Benchmarks Leaderboard - how M3 compares in tool-use and agent tasks
- What Is a Context Window? - primer on why 1M tokens matters for agentic pipelines
FAQ
Is MiniMax M3 open source?
Weights are promised but not yet published at launch. The license terms will ship with the weights. MiniMax's previous model (M2.7) restricted commercial use without authorization, so read the license before building commercial products on top of M3.
How does M3 compare to Claude Opus 4.8 on coding?
Claude Opus 4.8 scores 69.2% on SWE-Bench Pro versus M3's 59.0%. Opus leads on OSWorld (83.4% vs 70%) and Terminal-Bench. M3's advantage is cost (roughly 10-20x cheaper) and context length.
What is MiniMax Sparse Attention?
MSA replaces standard full attention with a two-stage mechanism: a lightweight index branch selects relevant key-value cache blocks, then attention runs only on those blocks. This cuts compute per token to 1/20th of the previous generation at 1M context, enabling practical long-context inference at reasonable cost.
Where can I access MiniMax M3?
Via the MiniMax API, MiniMax Code subscription, or OpenRouter. Open weights on Hugging Face are expected within 10 days of the June 1 launch.
What inputs does M3 accept?
Text, images, and video inputs. Output is text-only. Multimodal support is native - trained from pretraining on interleaved data, not added at fine-tuning.
Sources:
- MiniMax M3 Official Blog Post
- MiniMax M3 on OpenRouter
- The Decoder: MiniMax M3 open-weight model with 1M context challenges proprietary leaders
- TechTimes: MiniMax M3 Open-Weight Coding Model - Frontier Claims, Unverified Benchmarks
- Lushbinary: MiniMax M3 Developer Guide - Benchmarks and Pricing
- Datanorth: MiniMax Launches M3
- HuggingFace Blog: MiniMax Goes Sparse - Decoding M3's Attention
Last updated
✓ Last verified June 4, 2026
