HiDream-O1-Image
HiDream-O1-Image is an 8B open-source text-to-image model with a pixel-space diffusion architecture that outperforms 32B FLUX.2 [dev] across five major benchmarks.

HiDream-O1-Image arrived on May 8, 2026 as a 8-billion-parameter open-source text-to-image model from the HiDream-ai research team. The headline claim is blunt: their 8B model consistently beats FLUX.2 [dev] - a model with roughly 32 billion parameters - across five standard image quality benchmarks. That's the kind of efficiency story worth inspecting.
TL;DR
- 8B pixel-space diffusion model (MIT license) that beats 32B FLUX.2 [dev] on GenEval, DPG-Bench, HPSv3, CVTG-2K, and LongText benchmarks
- Novel Unified Transformer (UiT) architecture removes the VAE bottleneck used by virtually every other diffusion model
- Free to run locally; no commercial API exists yet; a 200B+ Pro variant is in development
The model is fully open-weight under MIT license with weights on HuggingFace and a technical paper on arXiv (2605.11061). A distilled "Dev" variant runs in 28 inference steps rather than the standard 50, trading some quality for speed.
Key Specifications
| Specification | Details |
|---|---|
| Provider | HiDream-ai |
| Model Family | HiDream |
| Parameters | 8B (full); 8B Dev (distilled, 28 steps) |
| Max Resolution | 2,048 x 2,048 pixels |
| Architecture | Pixel-level Unified Transformer (UiT), no VAE |
| Input Price | Free (open weights) |
| Output Price | Free (open weights) |
| Release Date | May 8, 2026 |
| License | MIT |
Benchmark Performance
The benchmarks below come directly from the HiDream-O1-Image technical report. I've included FLUX.2 [dev] (their primary comparison target), FLUX.1 [dev], and DALL-E 3 for broader context.
| Benchmark | HiDream-O1 (8B) | FLUX.2 [dev] (32B) | FLUX.1 [dev] | DALL-E 3 |
|---|---|---|---|---|
| GenEval (overall) | 0.90 | 0.87 | 0.66 | - |
| DPG-Bench (overall) | 89.83 | 87.57 | 83.84 | 83.50 |
| HPSv3 (overall) | 10.37 | 9.28 | - | - |
| CVTG-2K (average) | 0.9128 | 0.8926 | - | - |
| LongText-EN | 0.979 | 0.963 | - | - |
| LongText-ZH | 0.978 | 0.757 | - | - |
 HiDream-O1-Image benchmark comparison from the official model card, showing results across GenEval, DPG-Bench, and HPSv3 against major competitors.
Source: github.com/HiDream-ai
HiDream-O1-Image benchmark comparison from the official model card, showing results across GenEval, DPG-Bench, and HPSv3 against major competitors.
Source: github.com/HiDream-ai
The GenEval margin (+0.03 over FLUX.2 [dev]) looks modest, but HPSv3 tells a different story: HiDream scores 10.37 versus FLUX.2's 9.28, a gap of more than a full point in human preference. Human preference scores are noisy, but a full point is not noise.
The Chinese text rendering numbers are striking: 0.978 versus 0.757 for FLUX.2 [dev]. That 22-point gap on LongText-ZH is almost certainly the consequence of dedicated Chinese training data rather than architecture alone. For anyone building multilingual image pipelines, that gap changes the calculus.
Two caveats: these benchmarks come from the authors, not an independent lab. And some metrics (LongText, CVTG-2K) are fairly specialized; performance on broad creative prompts may differ from what the tables suggest.
Key Capabilities
The defining architectural choice is the elimination of the variational autoencoder (VAE). Every mainstream diffusion model - FLUX.2, Stable Diffusion 3.5, DALL-E 3 - compresses images through a VAE before and after the diffusion process. HiDream skips that step completely.
The Unified Transformer maps raw image pixels, text tokens, and task-specific conditions into a single shared token space, removing the VAE bottleneck used by virtually every competing model.
Working directly in pixel space gives the model two practical advantages. First, it avoids the quality ceiling imposed by VAE reconstruction artifacts, which can blur fine details and degrade text rendering at high resolutions. Second, the architecture is natively multi-task. The same model handles text-to-image generation, instruction-based editing, subject-driven personalization, and complex text rendering without switching between separate modules.
The built-in reasoning-driven prompt agent is worth noting separately. Before generating an image, the model runs an internal reasoning pass over the prompt - similar in concept to chain-of-thought in language models. The practical effect is better prompt adherence on complex compositional requests, which shows up in the GenEval two-object (0.99) and position (0.93) sub-scores.
 Examples showing HiDream-O1-Image across text-to-image generation, image editing, and complex text layout tasks.
Source: github.com/HiDream-ai
Examples showing HiDream-O1-Image across text-to-image generation, image editing, and complex text layout tasks.
Source: github.com/HiDream-ai
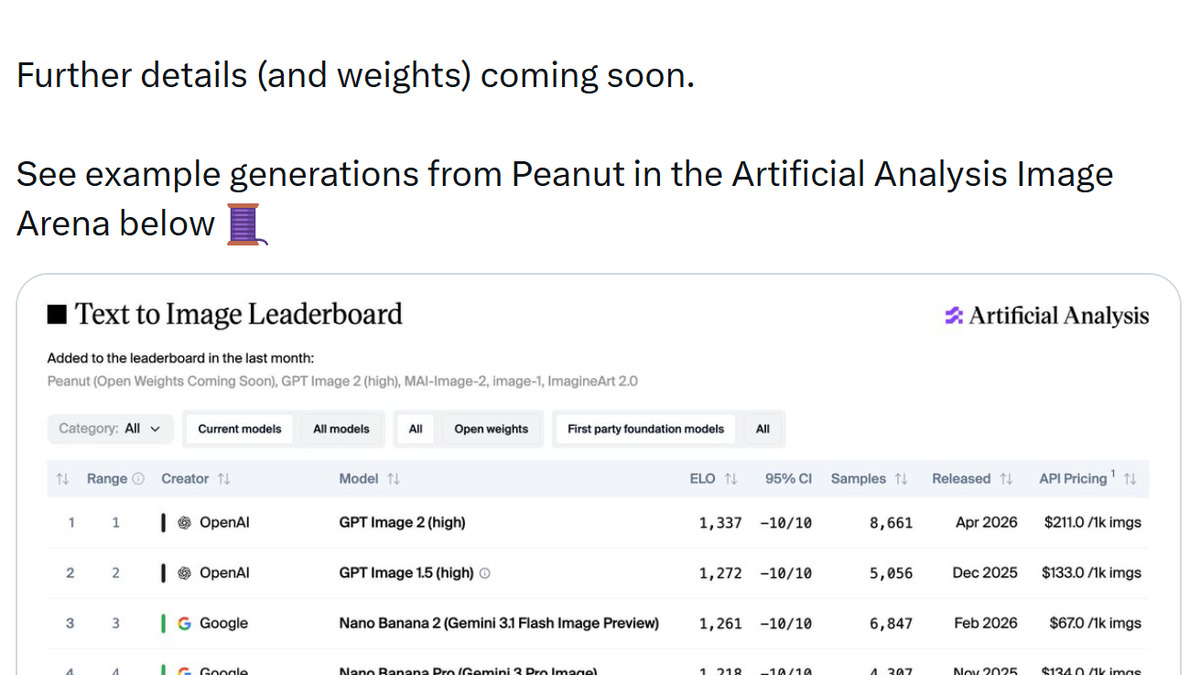
For image generation leaderboard comparisons, the model currently sits at #8 on the Artificial Analysis Text-to-Image Arena - the highest position of any open-weight model in that ranking as of May 2026.
Pricing and Availability
There's no API. HiDream-O1-Image is self-hosted: download weights from HuggingFace, run locally or on your own infrastructure. The MIT license allows commercial use without restriction.
Compute requirements aren't trivial. The full model runs 50 inference steps at up to 2048x2048 resolution. In practice, expect to need a GPU with at least 24GB VRAM for the full model. The Dev variant (28 steps) is meaningfully faster at a modest quality cost.
For comparison, FLUX.2 [pro] via the Black Forest Labs API costs $0.05 per image at production resolutions. For teams generating high volumes, the cost difference between self-hosted HiDream and a paid API is material once infrastructure costs are factored in.
A 200B+ parameter "Pro" version exists in internal testing per the technical report but hasn't been released publicly. The Pro variant scores GenEval 0.92 and DPG-Bench 90.30 in the paper's own tables, so it's meaningfully better - but it's not available.
Strengths and Weaknesses
Strengths
- Beats models 4x its size on GenEval, DPG-Bench, and HPSv3
- Novel VAE-free pixel-space architecture reduces reconstruction artifacts at high resolution
- MIT license, no usage restrictions, weights downloadable from HuggingFace
- Chinese text rendering is 22 points ahead of FLUX.2 [dev] on LongText-ZH
- Multi-task from a single model: generation, editing, personalization, text rendering, layout conditioning
- Dev variant (28 steps) enables faster iteration during prompt development
Weaknesses
- No hosted API; self-deployment requires 24GB+ VRAM GPU
- Benchmarks are author-reported, not independently reproduced
- Very early adoption - limited community tooling and integration support
- Pro variant (200B+) not yet publicly available
- Artificial Analysis Arena ranking (#8) reflects user votes, which can shift quickly after a release spike
Related Coverage
- AI Image Generation Leaderboard - full rankings including HiDream and competitors
- FLUX.2 [dev] - the primary benchmark comparison target
- FLUX.2 [pro] - commercial API alternative with production guarantees
- Ideogram v3 - proprietary alternative strong on text rendering and typography
- GPT Image 2 - OpenAI's image generation model for comparison
Sources
✓ Last verified May 14, 2026
