Helios: Real-Time 14B Open-Source Video Model
Helios is a 14B open-source autoregressive diffusion model that generates minute-long videos at 19.5 FPS on a single H100, matching 1.3B distilled model speeds at full 14B quality.

Helios is a 14-billion-parameter open-source video generation model from Peking University and ByteDance, released on March 4, 2026. It runs at 19.5 frames per second on a single NVIDIA H100 GPU - matching the throughput of 1.3B distilled models while delivering the quality you'd expect from a full-scale 14B architecture.
TL;DR
- 14B open-source video model running at 19.5 FPS on one H100 - same speed as models one-tenth its size
- Supports text-to-video, image-to-video, and video-to-video; creates clips up to 60 seconds; Apache 2.0 licensed
- Beats every open-weight distilled competitor on HeliosBench short and long video, with no KV-cache or quantization tricks
That speed number sounds like a marketing claim, so let me be clear about how it's reached. Helios uses aggressive token compression (8x history reduction via Multi-Term Memory Patchification), a Pyramid Unified Predictor Corrector that cuts generation tokens by another 2.3x, and adversarial hierarchical distillation to reduce sampling steps from 50 to 3 in the Distilled variant. No KV-cache. No quantization. No sparse attention. The efficiency gains come from architectural compression, not the standard shortcuts.
The model is built on top of Wan-2.1-T2V-14B, adapted into an autoregressive generator via Unified History Injection - a technique that feeds historical clean frames alongside the noisy segment being denoised, allowing the bidirectional base to function autoregressively.
Key Specifications
| Specification | Details |
|---|---|
| Provider | Peking University / ByteDance / Canva / Chengdu Anu Intelligence |
| Model Family | Helios |
| Parameters | 14B (active for all inference) |
| Max Video Length | 1452 frames (~60 seconds at 24 FPS) |
| Resolution | 384 x 640 pixels |
| Training Data | 800,000 video clips (under 10 seconds each) |
| Supported Tasks | Text-to-Video, Image-to-Video, Video-to-Video |
| License | Apache 2.0 |
| Release Date | March 4, 2026 |
| Pricing | Free (open weights) |
| Min VRAM (low-mode) | ~6 GB (Group Offloading enabled) |
| Recommended HW | Single NVIDIA H100 |
Three variants are available: Helios-Base (50 sampling steps, maximum quality), Helios-Mid (intermediate, uses CFG-Zero for ~2x speedup), and Helios-Distilled (3 sampling steps, real-time via adversarial distillation). All three are open on HuggingFace.
Benchmark Performance
Helios was assessed on HeliosBench, a custom test dataset of 240 prompts built by the authors because no existing public benchmark covers real-time long-video generation. That's worth flagging: these are author-run benchmarks, not independent third-party evaluations. Take the numbers at face value for now.
| Model | Parameters | FPS (H100) | Short Video Score (81f) | Long Video Score (1440f) |
|---|---|---|---|---|
| Helios-Distilled | 14B | 19.53 | 6.00 | 6.94 |
| Reward Forcing | 1.3B | 22.13 | 5.71 | 6.88 |
| SANA Video Long | 2B | 13.24 | 5.65 | 6.41 |
| Krea-RealTime-14B | 14B | 6.70 | 5.88 | 6.52 |
| Wan 2.1 14B (base) | 14B | <1 | 6.02 | 4.90 |
The most interesting comparison is against Wan 2.1 14B, the base model Helios was initialized from. Helios-Distilled runs 52x faster (19.53 vs <1 FPS) and scores higher on long-video generation (6.94 vs 4.90), which is the task where temporal drift matters most. On short video, the base Wan model edges ahead by 0.02 points - essentially tied.
Against Reward Forcing (1.3B), which is the fastest open model at 22.13 FPS, Helios trades 2.6 FPS for substantially better long-video quality. The 200-person user study confirms this: Helios wins 70-92.5% of pairwise comparisons on long video and 56-99.2% on short video across tested prompts.
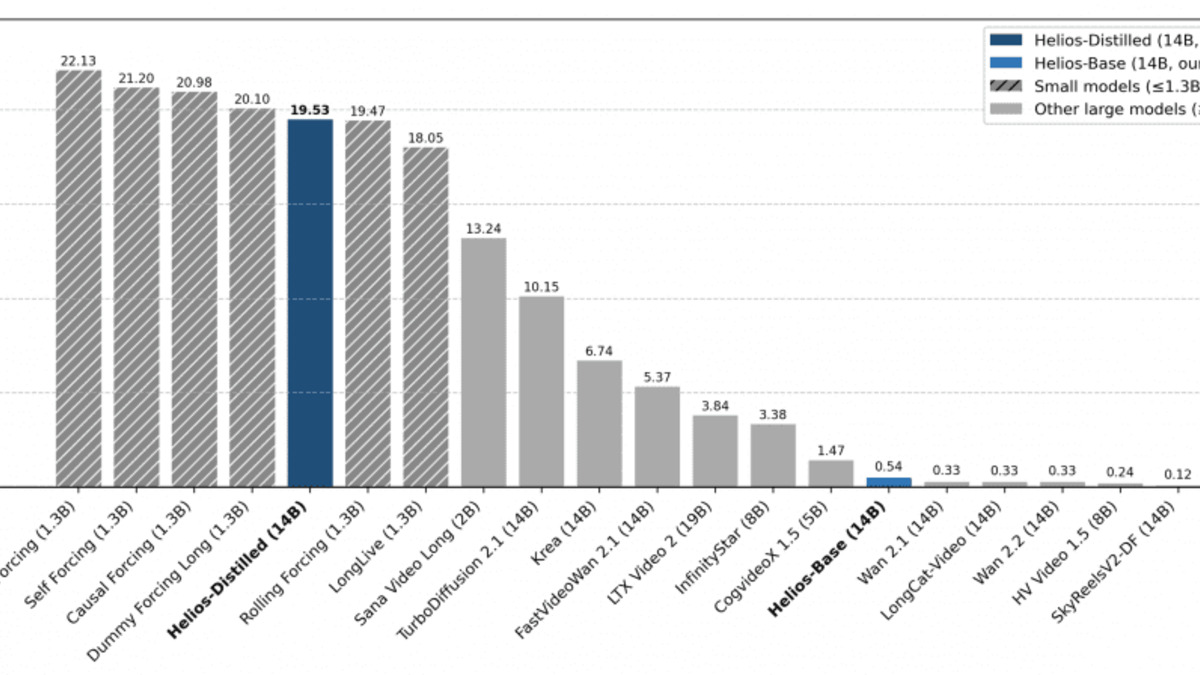 End-to-end throughput (FPS) on a single NVIDIA H100 across all official model variants. Helios-Distilled reaches 19.53 FPS despite having 14B parameters.
Source: neurohive.io
End-to-end throughput (FPS) on a single NVIDIA H100 across all official model variants. Helios-Distilled reaches 19.53 FPS despite having 14B parameters.
Source: neurohive.io
Key Capabilities
Real-Time Long-Video Generation
The headline capability is producing videos longer than 30 seconds at near-real-time speeds on a single consumer-grade data center GPU. Prior 14B models like Wan 2.1 took minutes per second of footage. Helios-Distilled collapses that to real-time, which opens up interactive applications: live storyboarding tools, game engine integration, on-device content creation.
The autoregressive chunking approach processes 33 frames per chunk (though num_frames values should be multiples of 33). For very long videos (1440+ frames), this means hundreds of sequential chunks - which is exactly where most autoregressive video models fail due to temporal drift. Helios addresses this through three explicit anti-drifting techniques baked into training: Relative RoPE (fixed positional encoding regardless of video length), First-Frame Anchor (the opening frame is maintained throughout), and Frame-Aware Corruption (training on deliberately degraded history contexts to build robustness).
Unified Multi-Task Support
A single checkpoint handles T2V, I2V, and V2V tasks through a unified input representation. This matters for production workflows where you want one model rather than three separate deployments. The approach is described in the technical report as "Unified History Injection" - historical frames (clean or noisy) are fed with the current segment, so the model sees both conditioning context and the generation target in a single forward pass.
Low-VRAM Inference
With Group Offloading enabled, Helios runs on about 6 GB of VRAM. For a 14B model, that's striking. The four-14B-models-per-80GB-H100 training configuration uses the same compression ideas applied at inference time. Most 14B video models require at least 24 GB, often 40-80 GB for the full pipeline.
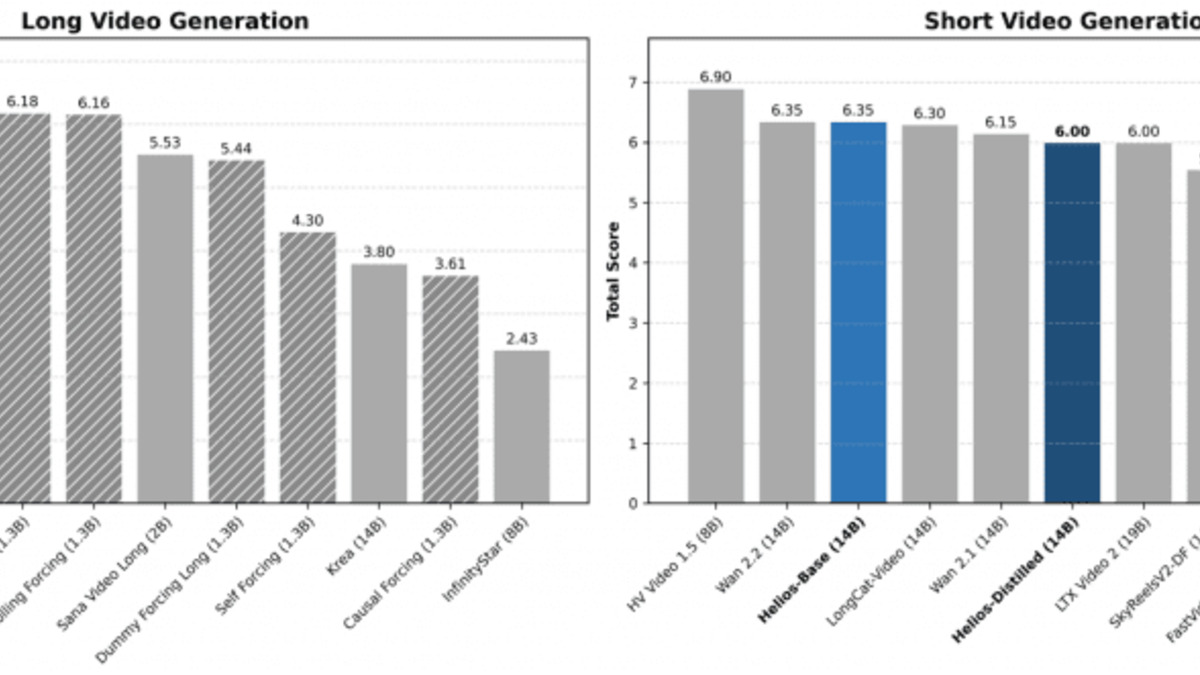 HeliosBench scores across four video length regimes: 81, 240, 720, and 1440 frames. Helios-Distilled leads across all regimes.
Source: neurohive.io
HeliosBench scores across four video length regimes: 81, 240, 720, and 1440 frames. Helios-Distilled leads across all regimes.
Source: neurohive.io
Pricing and Availability
Helios is fully open-source under Apache 2.0, which permits commercial use, modification, and redistribution. Weights for all three variants (Base, Mid, Distilled) are hosted on HuggingFace under BestWishYsh/Helios-Base and BestWishYsh/Helios-Distilled. ModelScope mirrors are also available.
There's no hosted API or SaaS pricing from the authors. Running Helios costs whatever your inference compute costs. On a cloud H100 (roughly $2.50-3.50/hour), you can create 19.5 frames per second, which means roughly 24 seconds of video per minute of compute time for the Distilled variant.
The project has day-0 Diffusers integration, with support also available through vLLM-Omni and SGLang. ComfyUI integration exists via a community wrapper. The GitHub repository includes training scripts, inference code, and the HeliosBench evaluation framework.
The authors note this is a research release, not a product integration with ByteDance's commercial services. That matters for anyone wondering whether Xiaomi-style surprise deployments (like the Hunter Alpha / MiMo-V2-Pro stealth launch) are coming for Helios. The research-only framing suggests not.
Comparison to Competitors
For local open-source video generation, Helios sits above LTX-2.3 on long-video quality at the cost of lower maximum resolution (384x640 vs LTX-2.3's 4K). LTX-2.3 claims ~18x faster generation than Wan 2.2 on similar hardware, but that comparison is vendor-benchmarked against a different baseline. For Kling 3 and Seedance 2, both are closed-source commercial models with notably higher output quality and resolution but no local deployment option.
If you're building something that needs open-weight video generation and can live with 384x640, Helios-Distilled is the current best option for throughput. If quality at higher resolution matters more than speed, the base Wan 2.1 or LTX-2.3 family are better picks. See the AI Image Generation Leaderboard for broader comparisons across the generation ecosystem.
Strengths
- Highest FPS among 14B open-weight video models by a wide margin
- Competitive quality at 1/10th the compute of full-scale 14B baselines
- Apache 2.0 license - no restrictions on commercial use
- Diffusers integration means standard tooling works out of the box
- ~6 GB VRAM mode opens deployment on consumer hardware
- All three variants released with training code and eval framework
Weaknesses
- 384x640 maximum resolution is well below commercial competitors and LTX-2.3
- HeliosBench is author-developed, not an independent benchmark
- Occasional flickering at segment boundaries (acknowledged in the paper)
- No hosted API - requires own compute
- Training on 800K short clips may limit diversity of produced content
Related Coverage
- Our review of LTX-2.3 - the main open-source alternative with higher resolution
- Our review of Kling 3 - leading closed-source commercial video model
- Our review of Seedance 2 - ByteDance's closed-source video product
- AI Image Generation Leaderboard for broader model rankings
- Best Local Image Generation Models 2026 - guide on running generation models locally
FAQ
What is Helios best at?
Generating videos longer than 30 seconds at near-real-time speeds on a single GPU. It's the fastest open 14B video model by FPS and leads on long-video quality benchmarks.
Can Helios run on consumer hardware?
Yes, with Group Offloading enabled it needs approximately 6 GB of VRAM, making it compatible with RTX 3060/4060-class cards. Full-quality mode requires H100-level VRAM.
Is Helios free for commercial use?
Yes. The Apache 2.0 license permits commercial use, modification, and redistribution without restriction.
How does Helios compare to LTX-2.3?
Helios is faster and better at long-video temporal coherence; LTX-2.3 supports higher resolutions (up to 4K) and adds synchronized audio generation. Choose based on your resolution and audio requirements.
What resolution does Helios output?
384x640 pixels. This is the main limitation compared to commercial models, which normally output 720p or higher.
Sources:
- Helios technical report (arXiv 2603.04379)
- PKU-YuanGroup/Helios GitHub repository
- Helios project page (PKU Yuan Group)
- The Decoder - ByteDance's Helios brings minute-long video generation close to real time
- Neurohive - Helios 14B Model Analysis
- HuggingFace - Helios-Distilled model card
- WaveSpeedAI - Helios Real-Time Long Video Generation
- BuildFastWithAI - AI Models March 2026
✓ Last verified March 26, 2026

