Google Gemma 4 - Four Open Models Under Apache 2.0
Gemma 4 is Google DeepMind's most capable open model family: four variants from 2B to 31B, Apache 2.0 license, multimodal across text/image/video/audio, and the 31B Dense ranking #3 on Chatbot Arena against all open-weight models globally.

Google DeepMind dropped Gemma 4 on April 2, 2026, with four open-weight models spanning phones to data center GPUs - all under Apache 2.0 licensing. The 31B Dense variant landed at #3 on the Chatbot Arena text leaderboard among all open-weight models globally, with an ELO score of 1452. That puts it above models with four times the parameter count. The 26B Mixture-of-Experts sits at #6 on the same leaderboard despite activating only 3.8 billion parameters per forward pass.
TL;DR
- Best open-weight family by intelligence-per-parameter as of April 2026, led by 31B Dense at Arena ELO 1452
- 256K context on the larger two variants; Apache 2.0 means no licensing headaches for commercial deployment
- Beats Llama 4 Maverick on every reasoning benchmark; trades blows with Qwen 3.5 27B within 1-2% across MMLU and GPQA
The change that matters most isn't the benchmark score - it's the license. Previous Gemma generations used a proprietary terms-of-service that blocked specific commercial uses. Apache 2.0 removes that friction completely. Anyone building on Gemma 4 can deploy it, modify it, and redistribute it under the same terms as any other Apache-licensed software.
The family is built from the same research foundation as Gemini 3 - Google's internal flagship - which explains why a 31B model is competing with 1T+ parameter closed systems on reasoning tasks.
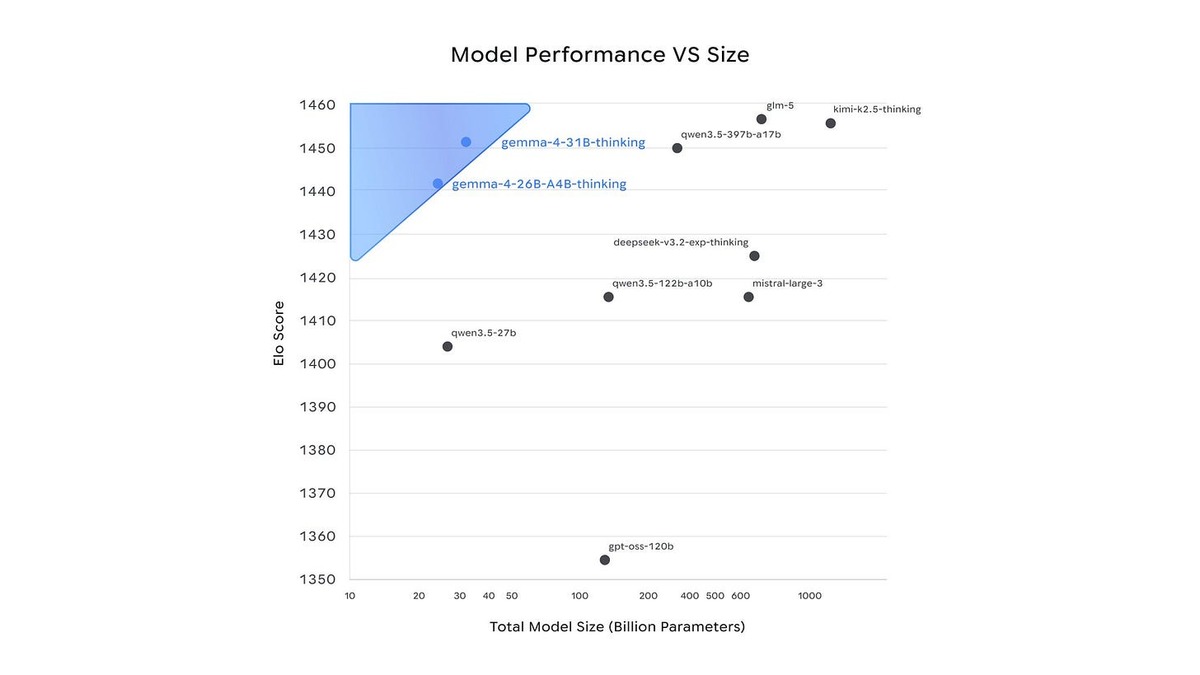 Gemma 4 31B and 26B A4B sit on the Pareto frontier of the Arena text leaderboard - highest ELO scores at the smallest parameter counts among open models.
Source: latent.space
Gemma 4 31B and 26B A4B sit on the Pareto frontier of the Arena text leaderboard - highest ELO scores at the smallest parameter counts among open models.
Source: latent.space
Key Specifications
| Specification | Details |
|---|---|
| Provider | Google DeepMind |
| Model Family | Gemma |
| Variants | E2B (2.3B effective), E4B (4.5B effective), 26B A4B (MoE), 31B Dense |
| Context Window | 256K tokens (31B, 26B); 128K tokens (E4B, E2B) |
| Input Price | $0.14/M tokens (OpenRouter, 31B) |
| Output Price | $0.40/M tokens (OpenRouter, 31B) |
| Release Date | April 2, 2026 |
| License | Apache 2.0 |
| Multimodal | Image + video on all variants; audio on E2B and E4B only |
| Languages | 140+ |
Benchmark Performance
The table below covers the flagship 31B Dense and 26B A4B variants alongside the closest open-weight competitors. All scores are from instruction-tuned checkpoints.
| Benchmark | Gemma 4 31B | Gemma 4 26B A4B | Qwen 3.5 27B | Llama 4 Maverick |
|---|---|---|---|---|
| MMLU Pro | 85.2% | 82.6% | 86.1% | 80.5% |
| GPQA Diamond | 84.3% | 82.3% | 85.5% | 69.8% |
| AIME 2026 | 89.2% | 88.3% | N/A | N/A |
| LiveCodeBench v6 | 80.0% | 77.1% | 72.4% | 43.4% |
| BigBench Extra Hard | 74.4% | 64.8% | N/A | N/A |
| Chatbot Arena ELO | ~1452 | ~1441 | N/A | ~1417 |
Qwen 3.5 27B edges Gemma 4 31B on MMLU Pro (86.1% vs 85.2%) and GPQA Diamond (85.5% vs 84.3%), but Gemma 4 pulls ahead on math and code - 89.2% on AIME 2026 and 80.0% on LiveCodeBench v6 versus Qwen 3.5's 72.4%. Neither is definitively superior; the choice depends on whether your workload skews toward knowledge retrieval or reasoning and code.
Llama 4 Maverick is a different story. At 69.8% GPQA Diamond and 43.4% LiveCodeBench, it trails Gemma 4 31B by wide margins despite having 400B total parameters. The open-source LLM leaderboard puts Gemma 4 31B comfortably ahead as the best US-origin open model available.
The 26B A4B is especially worth noting for inference economics. It activates only 3.8B parameters per token, runs near the speed of a 4B dense model, yet hits 88.3% on AIME 2026 - within 0.9 points of the much larger 31B. For throughput-sensitive deployments where you don't need maximum accuracy on every request, the MoE variant is the better choice.
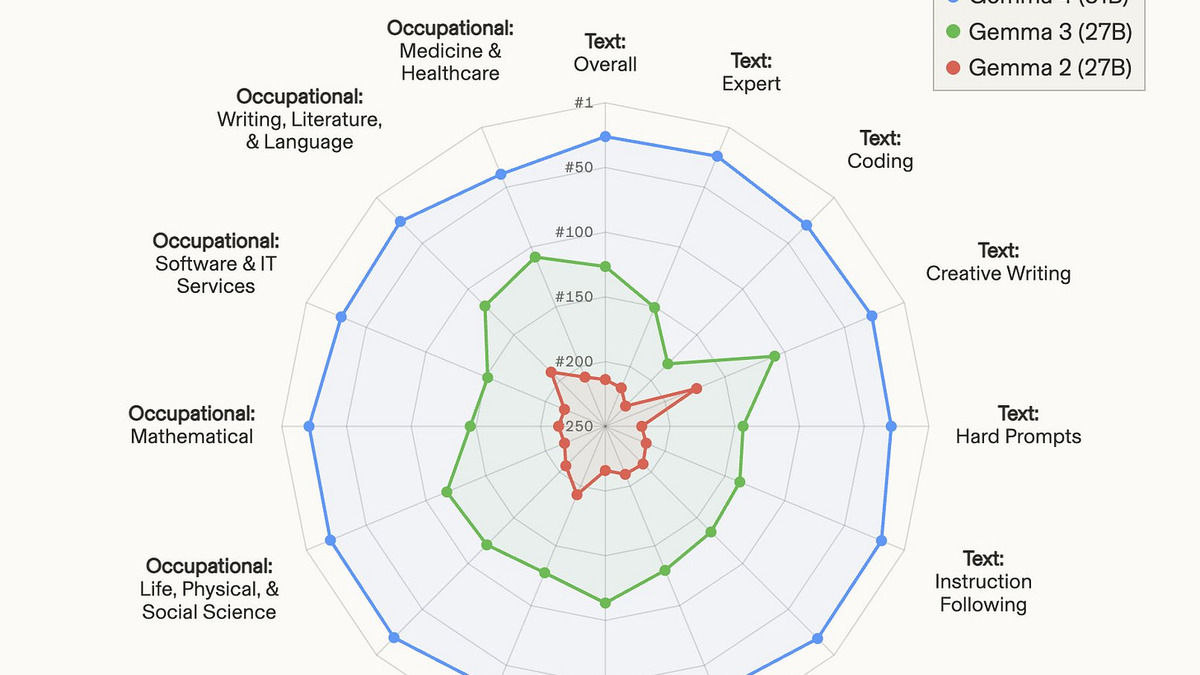 Gemma 4 31B dominates every text category over its predecessors on the Arena AI leaderboard - particularly in coding, expert text, and instruction following.
Source: arena.ai
Gemma 4 31B dominates every text category over its predecessors on the Arena AI leaderboard - particularly in coding, expert text, and instruction following.
Source: arena.ai
Architecture
Alternating Attention
Both the 26B and 31B models use a hybrid attention design that interleaves local sliding window attention (512-1024 token windows) with full global attention layers. The final layer is always global. This lets the model process long-context inputs without paying full quadratic attention costs on every layer.
Per-Layer Embeddings (PLE)
The edge variants (E2B, E4B) include a secondary embedding table that feeds a residual signal into every decoder layer. Google calls these "effective parameters" because PLE provides representational capacity far beyond what the raw parameter count implies. A model with 2.3B effective parameters performs closer to a conventional 5B model on most tasks.
MoE vs Dense Trade-offs
The 26B A4B activates 3.8B parameters per forward pass, which means GPU memory usage during inference is roughly equivalent to a 4B dense model. The tradeoff is that the full 26B weights need to be loaded - so you need enough VRAM to hold them, but compute is proportional to the active 3.8B. On a 40GB A100, both the 26B A4B and the 31B Dense are feasible with quantization; unquantized, only the 26B A4B fits comfortably.
Key Capabilities
Multimodal Reach
Every Gemma 4 variant handles text, images, and video. The E2B and E4B edge models go further with native audio support, using an USM-style conformer encoder for transcription and audio question answering. For the larger models, Google limited audio to the edge variants, likely reflecting hardware constraints at higher parameter counts.
The vision encoder uses learned 2D positional embeddings with configurable token budgets (70, 140, 280, 560, or 1120 image tokens), meaning you can tune the image resolution vs context cost trade-off at inference time. Document understanding (OmniDocBench) scores 0.131 edit distance for the 31B - competitive with closed models on OCR and structured extraction tasks.
Reasoning Mode
All variants support configurable thinking, similar to Claude's extended thinking or o-series chains of thought. Enabling it increases latency and token cost but improves accuracy on hard math and coding tasks. The 89.2% AIME 2026 score is measured with thinking enabled.
Agentic Tool Use
On τ2-bench, which tests real-world agentic task completion with tool calls, the 31B scores 86.4%. This puts it in the same tier as much larger closed models for agent pipelines. Gemma 4 was specifically designed for agentic workflows - function calling is native, not fine-tuned on.
Pricing and Availability
Google hasn't added Gemma 4 to its own Gemini API yet today, though Vertex AI deployment via Model Garden is available for the 26B A4B and 31B Dense. On OpenRouter, four providers currently offer both variants with the following rates for the 31B:
- Input: $0.14 per million tokens
- Output: $0.40 per million tokens
For context, GPT-5.2 runs $15/M input and $60/M output. Gemma 4 31B at $0.14/M input is over 100x cheaper per token for a model that lands near the top of the open model multimodal benchmarks leaderboard.
The full family is available for self-hosting via Hugging Face, Ollama, LM Studio, and Docker. Local inference support includes llama.cpp, MLX (Apple Silicon), ONNX (edge), and transformers.js for browser-based WebGPU inference. For developers running Gemma 4 locally, the 26B A4B is the right choice: it fits quantized on a 24GB consumer GPU while the 31B Dense requires 40GB+ unquantized.
At $0.14 per million input tokens, Gemma 4 31B costs over 100x less than GPT-5.2 for a model that sits #3 on the open-source Arena leaderboard.
Strengths and Weaknesses
Strengths
- Apache 2.0 on all four variants - no commercial use restrictions
- 31B Dense ranks #3 globally among open models on Chatbot Arena (ELO 1452)
- Strong math and code: 89.2% AIME 2026, 80.0% LiveCodeBench v6
- 26B A4B activates only 3.8B parameters - fast and memory-efficient at inference
- Genuine multimodal support across image, video, and audio (edge variants)
- Thinking mode for harder reasoning tasks at the cost of additional latency
- Solid agentic tool use: 86.4% on τ2-bench for the 31B
Weaknesses
- Qwen 3.5 27B edges it on MMLU Pro and GPQA Diamond by 1-2%
- 26B MoE inference is slower than the active parameter count implies due to expert routing overhead
- Audio support limited to E2B and E4B edge variants; 31B and 26B are text/image/video only
- Google's own Gemini API doesn't offer Gemma 4 yet - must use third-party providers or self-host
- Long-context MRCR v2 (128k) at 66.4% for 31B shows room for improvement at the context window edge
Related Coverage
- Our full review: Gemma 4 - Google's Biggest Open-Source Bet
- News: Google Gemma 4 Ships Four Open Models Under Apache 2.0
- Predecessor: Google Gemma 3 27B
- Competitor: Qwen 3.5 27B
- Competitor: Llama 4 Maverick
- Chatbot Arena Elo Rankings
- Open-Source LLM Leaderboard
- Multimodal Benchmarks Leaderboard
FAQ
What is the best Gemma 4 variant for local inference?
The 26B A4B MoE fits quantized on a 24GB GPU and activates only 3.8B parameters per token, making it the fastest and most memory-efficient option for local use without major accuracy loss.
Does Gemma 4 support function calling natively?
Yes. All variants support native function calling without fine-tuning, including both text-only and multimodal function calls for agentic workflows.
Is Gemma 4 fully open source?
All four Gemma 4 variants are released under Apache 2.0, which permits commercial use, modification, and redistribution without restrictions.
How does Gemma 4 31B compare to Gemma 3 27B?
The jump is large. Gemma 3 27B scored around 42% on GPQA Diamond; Gemma 4 31B hits 84.3% - a 42-point improvement. MMLU Pro went from roughly 67% to 85.2%. Both context window and multimodal capabilities expanded clearly.
Where can I access Gemma 4 via API?
OpenRouter lists four providers as of April 2026, pricing the 31B at $0.14/M input and $0.40/M output. Vertex AI supports deployment via Model Garden. Google's own Gemini Developer API doesn't yet include Gemma 4.
Sources:
✓ Last verified April 7, 2026

