Gemini 3.5 Flash
Google DeepMind's fastest frontier model, hitting 76.2% on Terminal-Bench 2.1 and 289 tok/s, now powering AI Mode in Search for over 1 billion monthly users.

Gemini 3.5 Flash is Google DeepMind's first model in the new Gemini 3.5 family, announced at Google I/O 2026 on May 19. It is the default model for the Gemini app and AI Mode in Google Search - a deployment that reaches over one billion monthly users. Google positions it as the strongest agentic and coding model the Flash series has ever shipped, with benchmark numbers that beat the previous premium tier, Gemini 3.1 Pro, on nearly every task the Flash line was built for.
TL;DR
- Tops the Flash series on agentic and coding tasks - 76.2% Terminal-Bench 2.1, 83.6% MCP Atlas, 55.1% SWE-Bench Pro
- 1M-token context window, 289 tok/s output speed, $1.50/$9.00 per million tokens in/out
- Faster than Claude Opus 4.7 by 4x; trails it on SWE-Bench Pro (55.1% vs 64.3%)
The model is built on the Gemini 3 Flash reasoning foundation with configurable "thinking levels" that let developers trade latency for reasoning depth. Dynamic thinking defaults to medium - enough to handle multi-step agent tasks without ballooning response time. Knowledge cutoff is January 2026. Input modalities cover text, images, audio, video, and PDF files. Output is text only.
The performance numbers are real but come with caveats. On software engineering, Claude Opus 4.7 scores 64.3% on SWE-Bench Pro versus Gemini 3.5 Flash's 55.1%. On abstract reasoning, GPT-5.5 scores 84.6% on ARC-AGI-2 against Flash's 72.1%. Flash leads where it counts for agents: tool orchestration, multimodal document analysis, and long-horizon workflow tasks.
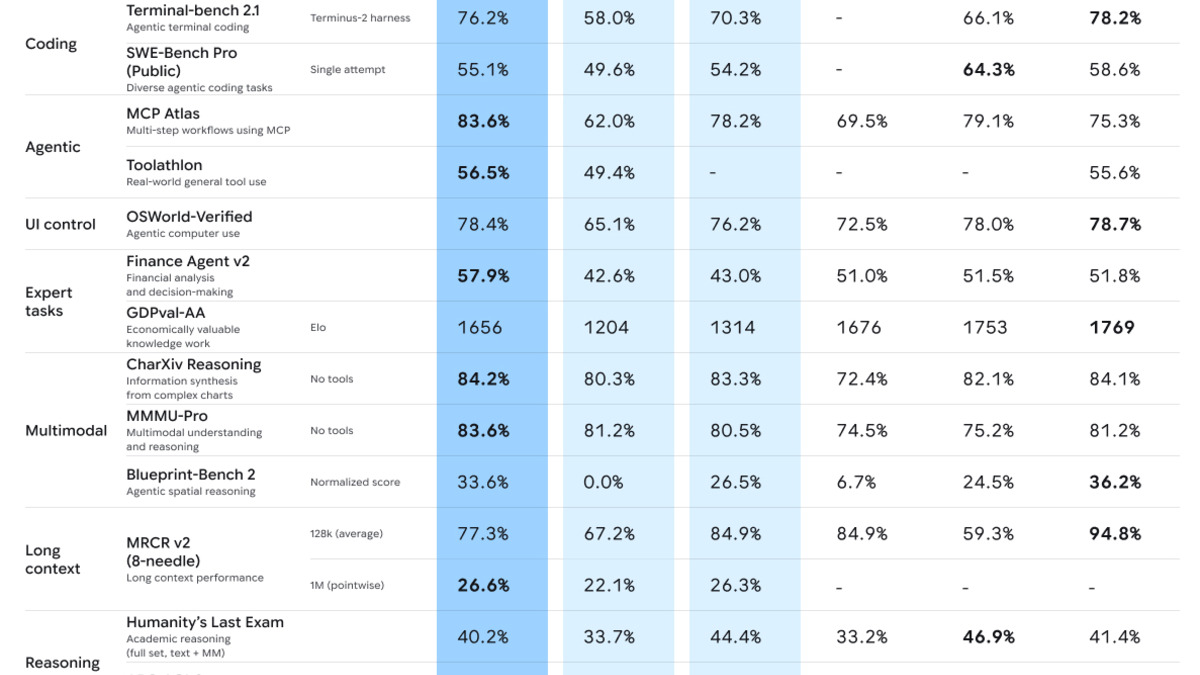 Google's benchmark comparison showing Gemini 3.5 Flash results across agentic, coding, and reasoning categories against Gemini 3 Flash.
Source: blog.google
Google's benchmark comparison showing Gemini 3.5 Flash results across agentic, coding, and reasoning categories against Gemini 3 Flash.
Source: blog.google
Key Specifications
| Specification | Details |
|---|---|
| Provider | Google DeepMind |
| Model Family | Gemini |
| Parameters | Not disclosed |
| Context Window | 1,048,576 input tokens / 65,536 output tokens |
| Input Modalities | Text, image, audio, video, PDF |
| Output Modalities | Text |
| Knowledge Cutoff | January 2026 |
| Input Price | $1.50 / M tokens |
| Output Price | $9.00 / M tokens |
| Release Date | May 19, 2026 |
| License | Proprietary |
Benchmark Performance
The numbers below come from Google's official announcement and the DeepMind model card. Competitor scores are sourced from the same evaluation suite where stated.
| Benchmark | Gemini 3.5 Flash | Gemini 3.1 Pro | Claude Opus 4.7 | GPT-5.5 |
|---|---|---|---|---|
| Terminal-Bench 2.1 | 76.2% | 68.5% | n/a | n/a |
| SWE-Bench Pro | 55.1% | n/a | 64.3% | 58.6% |
| MCP Atlas | 83.6% | 73.9% | 79.1% | n/a |
| CharXiv Reasoning | 84.2% | n/a | n/a | 84.1% |
| MMMU-Pro | 83.6% | n/a | n/a | 81.2% |
| ARC-AGI-2 | 72.1% | n/a | n/a | 84.6% |
| Humanity's Last Exam | 40.2% | n/a | n/a | n/a |
| GDPval-AA (Elo) | 1,656 | n/a | 1,753 | n/a |
| Finance Agent v2 | 57.9% | n/a | n/a | 51.8% |
The pattern here is consistent. Flash 3.5 controls agentic tool-use and multimodal benchmarks. It trails on traditional software engineering (SWE-Bench Pro) and long-range memory tasks (MRCR v2 at 1M: 26.6% vs GPT-5.5's 77.3% at 128k context). For tasks that require spawning subagents, calling tools, and processing mixed media, the numbers hold up. For deep multi-file code changes or extended document retrieval, they don't.
Check the coding benchmarks leaderboard and agentic AI benchmarks leaderboard for live rankings as more independent evaluations come in.
At 289 tokens per second output - about 4x the rate of Claude Opus 4.7 or GPT-5.5 - Flash also occupies a unique position on the Artificial Analysis Intelligence Index: top-right quadrant, meaning high intelligence and high speed simultaneously. That's the combination most agentic pipelines care about, since slow models bottleneck multi-step workflows even at high accuracy.
Key Capabilities
Agentic Workflows
Gemini 3.5 Flash ships with full support for the Model Context Protocol (MCP), Google's Antigravity multi-agent orchestration platform, and parallel subagent execution. The 83.6% score on MCP Atlas - which tests scaled tool-use reliability across hundreds of tasks - is the clearest signal of where the model is built to operate. Google cites a 72% reduction in token use for long-range cyber tasks compared to Gemini 3 Flash, alongside a 42% performance improvement.
Enterprise deployments announced at I/O include Shopify (merchant data forecasting), Macquarie Bank (document-heavy onboarding), Salesforce (multi-turn tool calling in Agentforce), Databricks (real-time diagnostics), and Xero (workflow automation). These aren't benchmarks - they're production workloads. The pattern across all of them is the same: complex, long-horizon tasks that take humans days now take the model minutes.
Coding
On Terminal-Bench 2.1, a benchmark measuring full terminal-based coding tasks, Flash scores 76.2% against Gemini 3.1 Pro's 68.5% - a meaningful improvement given the benchmark's difficulty. SWE-Bench Pro at 55.1% is respectable but not top-of-class; Claude Opus 4.7 at 64.3% has a real edge on multi-file software engineering. For new application development, single-file fixes, and UI generation, Flash is strong. For large codebase refactors, it's a supporting role, not the lead.
Google also cites a 10-20% improvement in low-effort coding tasks over Gemini 3 Flash when using minimal thinking level, which matters for high-volume code completion pipelines where cost and latency are the binding constraints.
Multimodal Processing
The 1M-token context window with native support for image, audio, video, and PDF inputs makes Flash 3.5 the most capable Flash model for document-intensive workflows. CharXiv Reasoning at 84.2% and MMMU-Pro at 83.6% both test multimodal understanding across charts, scientific figures, and complex visual inputs. Long-context performance shows some degradation: 77.3% on MRCR v2 at 128k tokens, 26.6% at 1M tokens. That's expected at the frontier, but it's worth planning for when designing retrieval pipelines.
 The Gemini 3.5 brand graphic from Google's I/O 2026 announcement, showing the multi-colored star logo.
Source: blog.google
The Gemini 3.5 brand graphic from Google's I/O 2026 announcement, showing the multi-colored star logo.
Source: blog.google
Pricing and Availability
Standard tier: $1.50 per million input tokens, $9.00 per million output tokens, $0.15 per million cached input tokens. Batch tier is 50% off: $0.75 input / $4.50 output. Priority tier costs 80% more: $2.70 / $16.20.
Compared to the direct competitors:
- Claude Opus 4.7: $5.00 / $25.00 (3.3x more expensive on input, 2.8x on output)
- GPT-5.5: $5.00 / $30.00 (3.3x more on input, 3.3x on output)
- Gemini 3.1 Pro: $2.50 / $15.00 (1.7x more on input, 1.7x on output)
The "cheaper at less than half the cost of frontier models" claim Google made at the keynote checks out on output tokens specifically. VentureBeat reported Google's internal estimate that enterprises switching to Flash from competing flagship models could save over $1 billion per year across large deployments.
Google AI Studio gives free access with daily request limits - no credit card required. The model is also available via the Gemini API, Android Studio, Gemini Enterprise Agent Platform, and the Google Antigravity framework. Context caching adds $1.00 per million token-hours of storage, which matters for workflows that reuse long system prompts or document contexts across many calls.
"Gemini 3.5 Flash delivers frontier-level intelligence with exceptional speed, occupying the top-right quadrant of the Artificial Analysis Intelligence Index - the only model combining top-tier intelligence with industry-leading throughput." - Google DeepMind, May 2026
Strengths and Weaknesses
Strengths
- Speed: 289 tok/s output is roughly 4x faster than Claude Opus 4.7 and GPT-5.5 under comparable conditions
- Agentic tool use: 83.6% on MCP Atlas leads the field
- Multimodal inputs: native text, image, audio, video, PDF support in one model
- Pricing: 3x cheaper than Claude Opus 4.7 and GPT-5.5 on input; batch tier halves that further
- Configurable thinking: minimal/low/medium/high lets you dial quality against latency per call
- Scale: default model for 1B+ monthly users in Search AI Mode validates production reliability
Weaknesses
- SWE-Bench Pro at 55.1% trails Claude Opus 4.7 (64.3%) on complex multi-file software engineering
- Long-range retrieval degrades sharply at 1M context (26.6% MRCR v2) vs short-context performance
- No Computer Use support (use gemini-3-flash-preview if you need browser/desktop automation)
- No image or audio generation - text output only
- GDPval-AA Elo of 1,656 is behind Claude Opus 4.7 at 1,753 on real-world agentic tasks
Related Coverage
- Gemini 3.1 Pro - the previous premium tier that 3.5 Flash now surpasses on most agentic benchmarks
- Gemini 3 Deep Think - for tasks requiring maximum reasoning depth over speed
- Agentic AI Benchmarks Leaderboard - live rankings on GAIA, MCP Atlas, and BFCL
- Coding Benchmarks Leaderboard - SWE-Bench and Terminal-Bench current standings
FAQ
Is Gemini 3.5 Flash faster than GPT-5.5?
Yes. At around 289 tokens per second output, it runs roughly 4x faster than GPT-5.5 and Claude Opus 4.7 under standard conditions, based on Artificial Analysis measurements from May 2026.
Does Gemini 3.5 Flash support image and video input?
Yes. It accepts text, image, audio, video, and PDF inputs natively. Output is text only - it doesn't produce images or audio.
What is the context window for Gemini 3.5 Flash?
1,048,576 input tokens (about 1M) with a maximum of 65,536 output tokens. Performance on long-context retrieval tasks degrades at the 1M end.
How does Gemini 3.5 Flash compare to Claude Opus 4.7?
Flash is faster (289 vs ~71 tok/s) and cheaper (3.3x less on input). Claude Opus 4.7 leads on SWE-Bench Pro (64.3% vs 55.1%) and GDPval-AA Elo (1,753 vs 1,656). Flash leads on MCP Atlas (83.6% vs 79.1%).
Can I use Gemini 3.5 Flash for free?
Yes, through Google AI Studio with daily request limits, no credit card required. It's also the default model in the free tier of the Gemini app.
Does Gemini 3.5 Flash support Computer Use?
No. For browser and desktop automation tasks, Google recommends using gemini-3-flash-preview instead.
Sources:
- Gemini 3.5: frontier intelligence with action - Google Blog
- Gemini 3.5 Flash Model Card - Google DeepMind
- Gemini 3.5 Flash - Google DeepMind
- Google Introduces Gemini 3.5 Flash at I/O 2026 - MarkTechPost
- Gemini 3.5 Flash: Benchmarks, Thinking & API Guide 2026 - DigitalApplied
- Gemini 3.5 Flash Benchmarks 2026 - BenchLM.ai
- Google says Gemini 3.5 Flash rivals large flagship models for coding - Engadget
- Google says Gemini 3.5 Flash can slash enterprise AI costs by more than $1 billion - VentureBeat
- Google Search AI Mode hits 1bn users - ResultSense
- Gemini 3.5 Flash: API Provider Performance - Artificial Analysis
✓ Last verified May 20, 2026
