DeepSeek V4
DeepSeek V4 ships in two open-weight MoE variants - V4-Pro at 1.6T/49B active and V4-Flash at 284B/13B active - both with 1M-token context and MIT license, released April 24, 2026.

TL;DR
- Two MIT-licensed MoE variants: V4-Pro (1.6T total / 49B active) and V4-Flash (284B / 13B active), both with 1M-token context
- V4-Pro scores 80.6% SWE-bench Verified, 90.1% GPQA Diamond, 93.5% LiveCodeBench in max reasoning mode - within a few points of Claude Opus 4.7 and GPT-5.5
- V4-Pro costs $1.74/$3.48 per million input/output tokens - roughly 7x cheaper than Claude Opus 4.7 at near-identical coding benchmark performance
Overview
DeepSeek released V4 on April 24, 2026, shipping two open-weight Mixture-of-Experts models under MIT license. V4-Pro carries 1.6 trillion total parameters with 49 billion active per token. V4-Flash runs at 284 billion total with 13 billion active. Both support a 1 million token context window. The pre-release page we published in March expected many of the architectural choices correctly - but the actual benchmarks and pricing are now confirmed and differ from early estimates in some standout ways.
The release landed on the same day as GPT-5.5, which means V4 competed for attention with OpenAI's rebuilt flagship. The timing wasn't accidental. DeepSeek's positioning has always been cost-per-capability, and V4 makes that case more aggressively than any prior release: our cost efficiency leaderboard shows V4-Pro delivering #3 overall intelligence at roughly one-sixth the price of GPT-5.5 and Opus 4.7.
The hardware story from the pre-release reporting held up. V4 runs natively on Huawei Ascend 950PR chips, with Nvidia support available for community deployments. V4-Pro hits only 27% of single-token inference FLOPs and 10% of KV cache compared to DeepSeek V3.2 at 1M-token context - a real efficiency gain that matters at production scale.
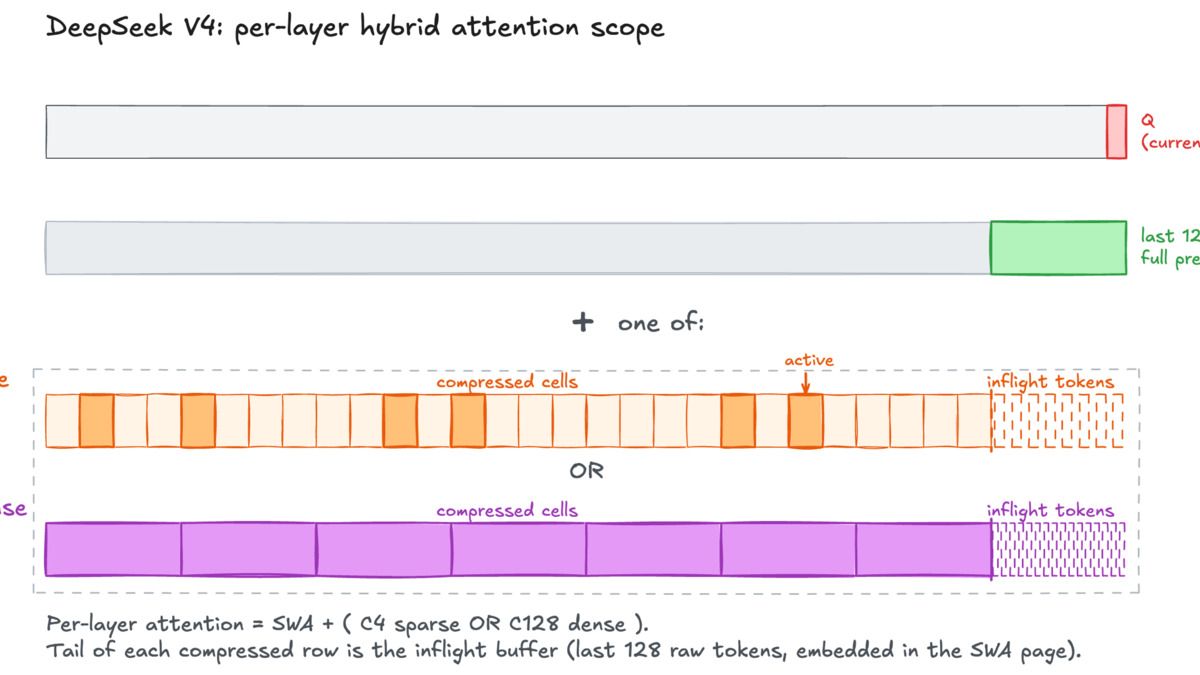 V4's hybrid attention: Compressed Sparse Attention (CSA) handles long-range dependencies while Heavily Compressed Attention (HCA) covers local context - together cutting KV cache to 10% of V3.2's requirement at 1M tokens.
Source: lmsys.org
V4's hybrid attention: Compressed Sparse Attention (CSA) handles long-range dependencies while Heavily Compressed Attention (HCA) covers local context - together cutting KV cache to 10% of V3.2's requirement at 1M tokens.
Source: lmsys.org
Key Specifications
| Specification | V4-Pro | V4-Flash |
|---|---|---|
| Provider | DeepSeek | DeepSeek |
| Total Parameters | 1.6T | 284B |
| Active Parameters | 49B | 13B |
| Context Window | 1,000,000 tokens | 1,000,000 tokens |
| Input Price | $1.74/M tokens | $0.14/M tokens |
| Output Price | $3.48/M tokens | $0.28/M tokens |
| Cached Input | $0.145/M tokens | - |
| Release Date | 2026-04-24 | 2026-04-24 |
| License | MIT | MIT |
| API Model ID | deepseek-v4-pro | deepseek-v4-flash |
| Precision | FP4 + FP8 mixed | FP4 + FP8 mixed |
| Pretraining Tokens | 32T+ | 32T+ |
Benchmark Performance
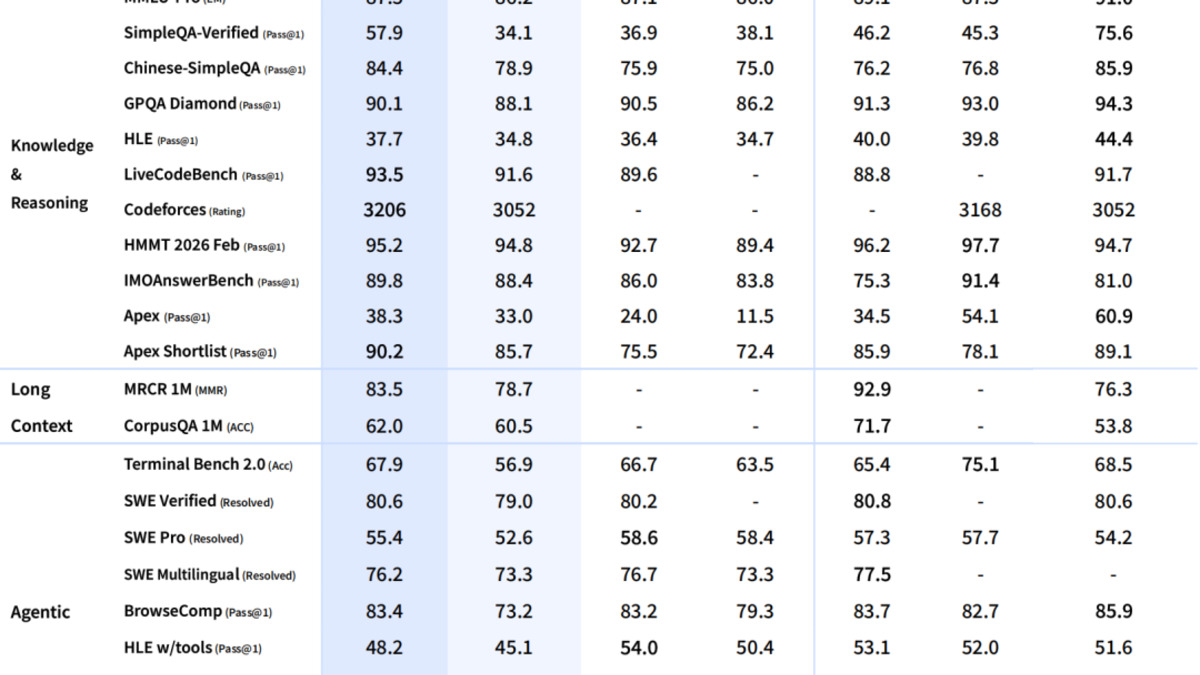
The benchmarks below are from DeepSeek's official technical report and Hugging Face model card. V4-Pro numbers use the "Max" reasoning mode (Think Max). Base model scores use the V4-Pro-Base checkpoint. Competitor numbers for GPT-5.5 and Claude Opus 4.7 come from Artificial Analysis and the respective providers.
| Benchmark | V4-Pro (Max) | V4-Flash (Max) | Claude Opus 4.7 | GPT-5.5 |
|---|---|---|---|---|
| GPQA Diamond | 90.1% | 88.1% | 94.2% | 93.6% |
| MMLU-Pro | 87.5 | 86.2 | - | - |
| LiveCodeBench | 93.5% | 91.6% | 88.8% | - |
| SWE-bench Verified | 80.6% | - | 87.6% | - |
| Terminal-Bench 2.0 | 67.9% | - | 65.4% | 82.7% |
| Codeforces Rating | 3206 | - | - | - |
| MRCR 1M (long context) | 83.5% | - | - | - |
| Humanity's Last Exam (no tools) | 37.7% | - | 46.9% | 41.4% |
V4-Pro lands in a clear third place on the Artificial Analysis Intelligence Index (score: 52), behind GPT-5.5 (60) and Claude Opus 4.7 (57). The gap is real. On GPQA Diamond, V4-Pro trails Opus 4.7 by 4.1 points and GPT-5.5 by 3.5 points. On Humanity's Last Exam without tools, the gap widens: V4-Pro at 37.7% vs Opus 4.7 at 46.9%.
Where V4-Pro beats the frontier models is coding throughput. Its Codeforces rating of 3206 has no direct comparison from Anthropic or OpenAI in the same timeframe. On LiveCodeBench, 93.5% tops Claude Opus 4.7's 88.8% in the same evaluation setting. And on Terminal-Bench 2.0, V4-Pro at 67.9% beats Opus 4.7 at 65.4%, though GPT-5.5 still leads at 82.7%. See the coding benchmarks leaderboard for a broader picture across all models.
V4-Flash is worth a closer look than most efficiency models. At 88.1% GPQA Diamond and 86.2 MMLU-Pro, it's within a few points of V4-Pro on knowledge benchmarks while costing 12x less on input tokens.
Key Capabilities
Two Reasoning Modes
Both V4 variants support three inference modes: Non-Think (fast, no chain-of-thought), Think High (structured reasoning for complex problems), and Think Max (full reasoning budget, used for the benchmark numbers above). The API controls this via a thinking_mode parameter. Non-Think mode is competitive with V3.2 for latency-sensitive applications. Max mode is where the benchmark-grade performance lives.
Hybrid Attention for Million-Token Contexts
The main architectural innovation is the hybrid attention mechanism: Compressed Sparse Attention (CSA) combined with Heavily Compressed Attention (HCA). At 1M tokens, this brings inference FLOPs down to 27% and KV cache to 10% of V3.2's requirements. In practice, this means running V4 at long contexts is substantially cheaper than running V3.2 at the same length. The long-context benchmarks leaderboard shows V4-Pro at 83.5% on MRCR 1M, which is a strong result.
Muon Optimizer and Manifold-Constrained Hyper-Connections
DeepSeek's training stack uses the Muon optimizer, a second-order method that speeds convergence. The Manifold-Constrained Hyper-Connections (mHC) system stabilizes gradient flow across the full depth of the 1.6T model. These aren't user-facing features, but they explain how DeepSeek trained a trillion-parameter model on 32T tokens without the instability that has historically plagued MoE models at this scale.
OpenAI and Anthropic API Compatibility
V4 supports both OpenAI ChatCompletions and Anthropic Messages API formats out of the box. Existing integrations built for Kimi K2.5 or Claude can switch to V4 with a model string change and no prompt reformatting.
Pricing and Availability
V4 is live at api.deepseek.com with model IDs deepseek-v4-pro and deepseek-v4-flash. Weights are on Hugging Face under MIT license. DeepSeek is running a 75% promotional discount on V4-Pro through May 5, 2026 - input tokens drop to roughly $0.04/M during the promo window. The standard cached input price is $0.145/M for V4-Pro, which brings the effective cost lower for RAG and multi-turn workloads.
| Model | Input | Output | vs Claude Opus 4.7 |
|---|---|---|---|
| DeepSeek V4-Flash | $0.14/M | $0.28/M | 178x cheaper input |
| DeepSeek V4-Pro | $1.74/M | $3.48/M | ~14x cheaper input |
| DeepSeek V3.2 | $0.28/M | $0.42/M | - |
| Kimi K2.5 | $0.60/M | $3.00/M | - |
| Claude Opus 4.7 | $5.00/M | $25.00/M | baseline |
| GPT-5.5 | ~$7.50/M | ~$30.00/M | - |
V4-Flash's $0.14/$0.28 pricing matches the original estimated pricing for V4 from March - DeepSeek kept V4-Flash affordable while charging more for V4-Pro's frontier-class reasoning. For high-volume production workloads where V4-Flash's benchmarks are sufficient, this is the most cost-effective option in its performance tier.
Self-hosting V4-Pro requires serious infrastructure. At 1.6T parameters with FP4+FP8 mixed precision, you need a multi-GPU cluster. V4-Flash at 284B is more approachable for well-resourced organizations, though still not a single-machine deployment.
 V4-Pro reaches third place on the Artificial Analysis Intelligence Index at roughly one-sixth the cost of GPT-5.5 and Claude Opus 4.7.
Source: datacamp.com
V4-Pro reaches third place on the Artificial Analysis Intelligence Index at roughly one-sixth the cost of GPT-5.5 and Claude Opus 4.7.
Source: datacamp.com
Strengths and Weaknesses
Strengths
- Open weights under MIT license - the most capable freely deployable model in the V4-Pro class
- V4-Flash delivers near-frontier GPQA and MMLU-Pro scores at $0.14/M input
- Coding benchmarks lead Opus 4.7 on LiveCodeBench and Terminal-Bench 2.0
- CSA + HCA hybrid attention makes million-token context affordable at production scale
- Both OpenAI and Anthropic API formats supported - easy drop-in replacement
- V4-Pro's 75% promo discount makes it cheaper than V3.2 until May 5
Weaknesses
- Intelligence Index #3 is real, not marketing noise - GPT-5.5 and Opus 4.7 lead on GPQA, MMLU-Pro, and Humanity's Last Exam
- Output speed is 36.6 tokens/second for V4-Pro (Max) - Artificial Analysis ranks it #44 for throughput
- Trillion-parameter V4-Pro isn't self-hostable for most users
- Chinese company; enterprise procurement teams should check their compliance posture
- Huawei chip optimization means Nvidia inference performance may not match the official benchmarks
- No multimodal support at launch - V4 is text only, despite pre-release speculation about native vision and audio
Related Coverage
- DeepSeek V4-Pro Review - Our hands-on review with real task evaluations
- DeepSeek V4 Drops Next Week - Our pre-release coverage with the confirmed timeline
- DeepSeek Locks US Chipmakers Out of V4 - Nvidia and AMD exclusion from the optimization pipeline
- DeepSeek V3.2 Model Profile - V4's predecessor
- Open Source LLM Leaderboard - Current rankings for open-weight models
- Coding Benchmarks Leaderboard - Full benchmark comparisons across all models
FAQ
Is DeepSeek V4-Pro better than Claude Opus 4.7?
On most knowledge and reasoning benchmarks, no - Opus 4.7 leads on GPQA Diamond (94.2% vs 90.1%) and Humanity's Last Exam. On pure coding throughput, V4-Pro leads on LiveCodeBench and Terminal-Bench 2.0. At ~14x lower cost, it's the better choice for cost-sensitive coding workloads.
Can I run DeepSeek V4 locally?
V4-Flash (284B) is feasible for organizations with multi-GPU server hardware. V4-Pro (1.6T) requires a large multi-node cluster. Weights for both are on Hugging Face under MIT license.
What is DeepSeek V4-Flash good for?
High-volume production workloads where V4-Pro's reasoning depth isn't needed. At $0.14/M input and 88.1% GPQA Diamond, V4-Flash competes with models that cost 3-5x more. Strong choice for RAG pipelines and batch inference jobs.
Does DeepSeek V4 support multimodal input?
No. Despite pre-release speculation about native vision and audio, V4 at launch is text-only. Multimodal capabilities may come in a later update.
What happened to the March release date?
The March 3-7 release window turned out to be wrong. DeepSeek released V4 on April 24, 2026 - about seven weeks later than originally reported.
Sources
- DeepSeek V4 Preview Release - DeepSeek API Docs
- DeepSeek-V4-Pro - Hugging Face model card
- DeepSeek-V4-Flash - Hugging Face model card
- DeepSeek V4 Pro - Artificial Analysis
- DeepSeek V4 comparison article - VentureBeat
- DeepSeek slashes V4-Pro pricing - Dataconomy
- DeepSeek V4 unveiling - Al Jazeera
- DeepSeek V4 benchmark comparison - BenchLM.ai
- DeepSeek Models & Pricing - API Docs
✓ Last verified April 28, 2026
